Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- □ Faut-il vraiment choisir entre www et non-www pour le SEO ?
- □ Pourquoi Googlebot ignore-t-il vos boutons et comment contourner cette limite ?
- □ Les guest posts pour des backlinks sont-ils vraiment bannis par Google ?
- □ Faut-il vraiment du texte sur les pages catégories pour bien ranker ?
- □ Le HTML sémantique a-t-il vraiment un impact sur le classement Google ?
- □ Faut-il vraiment s'inquiéter des erreurs 404 générées par JSON et JavaScript dans GSC ?
- □ Google privilégie-t-il vraiment la meta description quand le contenu est pauvre ?
- □ Faut-il vraiment bloquer l'indexation des menus et zones communes d'un site ?
- □ L'indexation mobile-first impose-t-elle vraiment la version mobile comme unique référence ?
- □ Les PDF hébergés sur Google Drive sont-ils vraiment indexables par Google ?
- □ Pourquoi Google indexe-t-il vos URLs même quand robots.txt les bloque ?
- □ Faut-il supprimer ou améliorer le contenu de faible qualité sur votre site ?
- □ Le CMS influence-t-il vraiment le jugement de Google sur votre site ?
- □ Un noindex sur la homepage peut-il vraiment faire apparaître d'autres pages en premier ?
- □ Faut-il vraiment optimiser l'INP si ce n'est pas (encore) un facteur de classement ?
- □ Faut-il vraiment nettoyer toutes les pages hackées ou laisser Google faire le tri ?
- □ Faut-il arrêter de forcer l'indexation quand Google désindexe vos pages ?
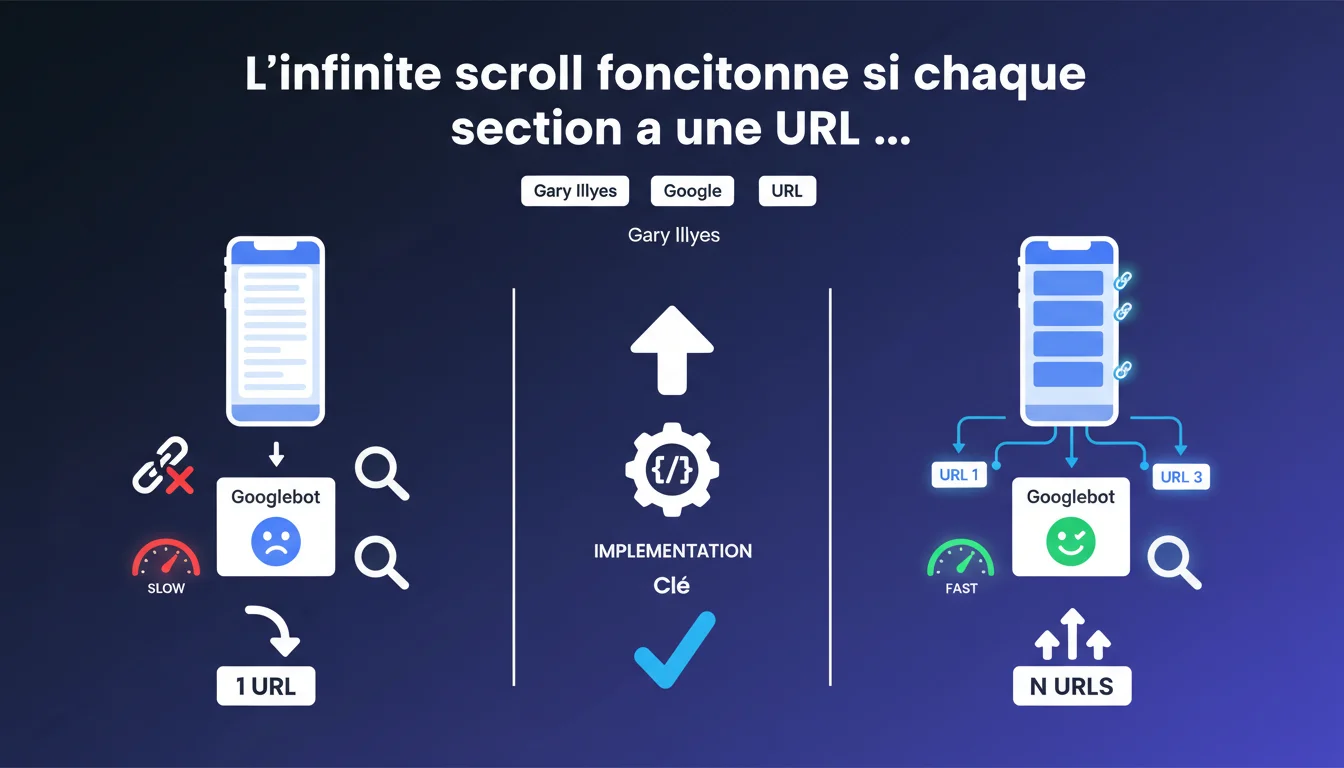
Google confirme que le défilement infini peut fonctionner pour le SEO, à condition que chaque section virtuelle soit accessible via une URL unique et trouvable par Googlebot. La qualité de l'implémentation technique détermine le succès ou l'échec de cette approche.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur les URLs uniques pour l'infinite scroll ?
L'infinite scroll pose un problème structurel majeur pour les crawlers : sans intervention, tout le contenu est chargé dynamiquement sur une seule URL. Googlebot ne peut pas « scroller » indéfiniment comme un utilisateur humain.
La solution réside dans la pagination virtualisée. Chaque « section » du flux infini doit correspondre à une URL distincte (example.com/page/2, example.com/page/3, etc.). Googlebot peut ainsi crawler méthodiquement chaque segment de contenu sans dépendre du JavaScript pour charger la suite.
Qu'est-ce qu'une implémentation correcte selon Google ?
Une implémentation correcte combine progressive enhancement et accessibilité. Les liens de pagination traditionnels doivent exister dans le HTML, même si l'interface utilisateur les masque visuellement au profit de l'infinite scroll.
L'History API (pushState) doit mettre à jour l'URL du navigateur au fur et à mesure du scroll. Ainsi, si un utilisateur partage un lien ou qu'un bot crawle directement une section, le contenu correspondant s'affiche — pas la page 1 par défaut.
Quels sont les pièges techniques les plus fréquents ?
Le piège classique : implémenter l'infinite scroll uniquement côté client, sans URLs canoniques pour chaque segment. Résultat ? Googlebot indexe la première page et ignore tout le reste, ou pire, tente de crawler des centaines de variations d'états JavaScript.
Autre erreur courante : les URLs de pagination existent, mais renvoient un contenu vide ou incomplet sans JavaScript activé. Google peut renderer le JS, mais ça consomme du crawl budget inutilement et ralentit l'indexation.
- Chaque section virtuelle doit avoir une URL propre et stable
- Les URLs doivent être crawlables et trouvables (liens internes, sitemap)
- Le contenu doit être accessible sans JavaScript ou via rendering minimal
- L'History API doit synchroniser l'URL avec la position de scroll
- Les balises rel="next" / rel="prev" peuvent clarifier la séquence (bien que Google les ignore officiellement depuis 2019, elles aident à la compréhension structurelle)
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, mais avec une nuance de taille : entre « peut fonctionner » et « fonctionne efficacement », il y a un gouffre. En pratique, les sites e-commerce ou médias qui ont migré vers l'infinite scroll sans URLs uniques ont vu leur indexation s'effondrer.
Les rares implémentations réussies (Pinterest, Airbnb anciennement) investissent des ressources considérables dans l'architecture technique. Pour un site moyen, le risque de régression SEO est réel si l'équipe technique sous-estime la complexité.
Quand cette approche est-elle réellement pertinente ?
Soyons honnêtes : l'infinite scroll répond d'abord à un besoin UX, pas SEO. Il améliore l'engagement sur mobile pour des flux sociaux ou des galeries visuelles. Mais pour un blog, un catalogue produit ou un site d'actualités, la pagination classique reste plus robuste.
Le vrai débat — que Gary n'aborde pas — c'est le coût d'opportunité. Implémenter un infinite scroll SEO-friendly mobilise des sprints de dev qui pourraient être alloués à des quick wins : vitesse de chargement, maillage interne, contenu. [À vérifier] : aucune étude publique ne démontre un avantage SEO mesurable de l'infinite scroll correctement implémenté vs. pagination traditionnelle.
Quels risques sont passés sous silence ?
Google ne parle jamais du crawl budget. Si votre site génère 500 URLs de pagination pour un flux infini, Googlebot va-t-il toutes les crawler régulièrement ? Probablement pas, surtout sur un site à autorité moyenne.
Autre point mort : les métriques Core Web Vitals. L'infinite scroll mal optimisé provoque des layout shifts (CLS) catastrophiques et des interactions bloquantes (INP). Google valorise l'UX dans son algo, mais ne fait jamais le lien dans cette déclaration.
Impact pratique et recommandations
Comment vérifier que mon infinite scroll est SEO-compatible ?
Premier test : désactive JavaScript complètement dans Chrome DevTools. Navigue dans ton flux. Si tu ne peux pas accéder aux pages 2, 3, 4 via des liens cliquables, c'est raté.
Deuxième test : utilise l'outil d'inspection d'URL de la Search Console. Demande un test en direct sur une URL de section (ex: /page/5). Le contenu attendu s'affiche-t-il ? Si Google te montre la page 1 ou une erreur, ton implémentation est défaillante.
Troisième test : vérifie les logs serveur. Googlebot crawle-t-il réellement tes URLs de pagination ? À quelle fréquence ? Si les pages 10+ ne sont jamais visitées, ton architecture dilue ton crawl budget.
Quelles erreurs éviter absolument ?
Ne jamais implémenter l'infinite scroll sans fallback. Même si 95% de tes users ont JS activé, les 5% restants + les bots doivent pouvoir naviguer. C'est une question d'accessibilité autant que de SEO.
Évite les URLs avec fragments (#) pour la pagination. Les ancres ne sont pas envoyées au serveur et Google les traite comme des variations d'une même page. Utilise des query parameters (?page=2) ou des segments d'URL (/page/2/).
Ne duplique pas le contenu. Si ta page 1 affiche les items 1-20 ET que ta page 2 affiche aussi les items 1-20 + 21-40, tu crées de la cannibalisation interne. Chaque URL doit servir un segment unique.
Quelle stratégie adopter concrètement ?
- Génère des URLs statiques pour chaque segment de pagination (/page/N ou ?page=N)
- Implémente l'History API (window.history.pushState) pour synchroniser scroll et URL
- Ajoute des liens HTML natifs vers next/prev, même masqués visuellement
- Configure le sitemap XML pour inclure toutes les URLs de pagination (jusqu'à un seuil raisonnable)
- Teste le rendu avec Screaming Frog en mode JavaScript et compare avec le rendu HTML brut
- Monitore les Core Web Vitals (CLS et INP) pour détecter les régressions UX
- Utilise des balises canonical auto-référencées sur chaque page de pagination
- Évite les directives noindex sur les pages 2+ (erreur fréquente héritée de vieilles pratiques)
❓ Questions frequentes
Dois-je absolument utiliser des URLs avec /page/2 ou puis-je utiliser des paramètres ?page=2 ?
Google crawle-t-il vraiment toutes mes pages de pagination avec l'infinite scroll ?
Les balises rel="next" et rel="prev" sont-elles encore utiles en 2023+ ?
Mon site React peut-il implémenter l'infinite scroll de manière SEO-safe ?
L'infinite scroll impacte-t-il les Core Web Vitals négativement ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 06/09/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.