Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Google indexe-t-il vraiment vos PDF ou les transforme-t-il d'abord ?
- □ Le poids du contenu varie-t-il selon son emplacement en HTML et en PDF ?
- □ Google dépend-il vraiment d'Adobe pour indexer vos PDF ?
- □ Google indexe-t-il vraiment le code source comme du texte ordinaire ?
- □ Pourquoi les fichiers de code source peinent-ils à se classer dans Google ?
- □ Faut-il vraiment arrêter de stocker tous vos PDF dans un dossier /pdfs/ ?
- □ Pourquoi Google n'indexe-t-il jamais une image isolée sans page d'hébergement ?
- □ Google indexe-t-il vraiment les images et vidéos différemment du texte ?
- □ Google filtre-t-il les données personnelles avant indexation ?
- □ L'extension de fichier (.html, .php, .txt) a-t-elle un impact sur le référencement Google ?
- □ Peut-on vraiment indexer des fichiers JSON et texte brut sans méta-données ?
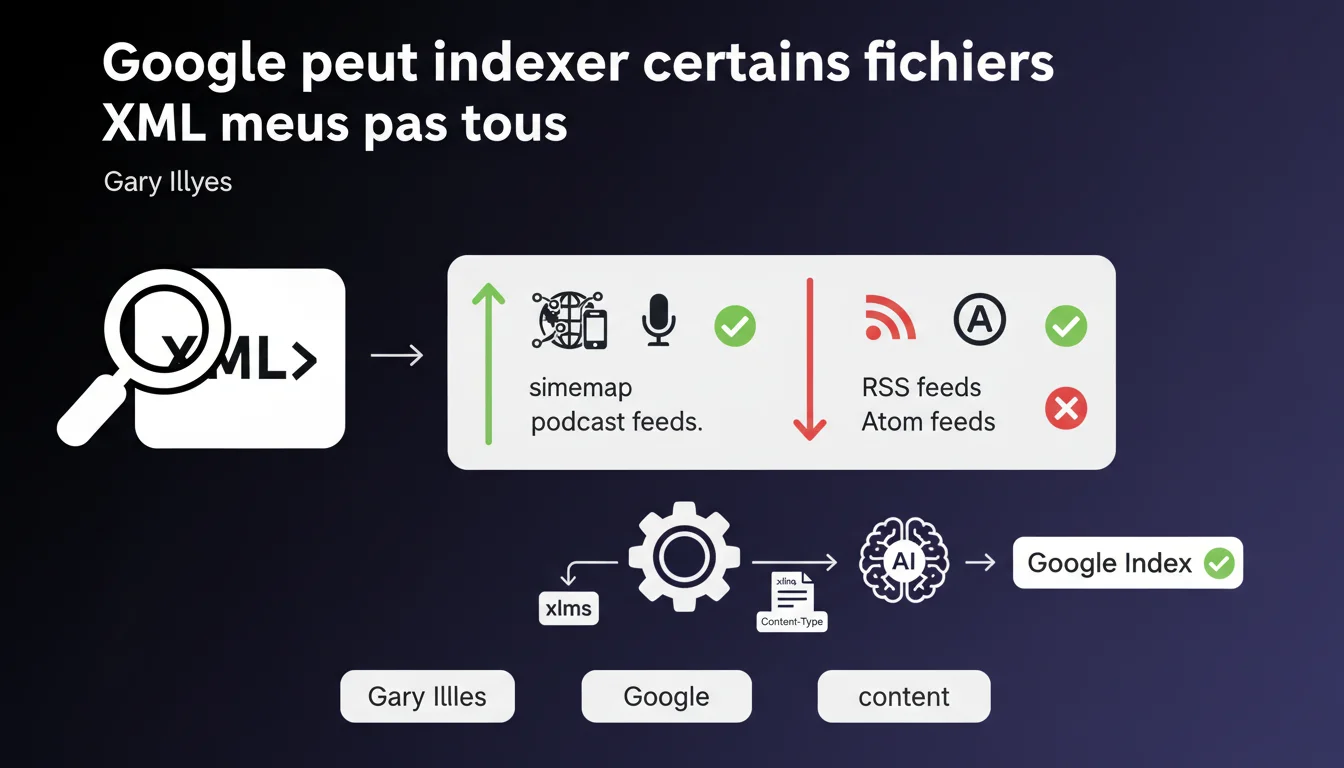
Google n'indexe pas tous les fichiers XML de manière uniforme. Les sitemaps XML et les podcasts feeds peuvent être indexés, mais les flux RSS et Atom sont généralement exclus. Le critère décisif ? Le namespace XML déclaré et le content-type header envoyé par le serveur.
Ce qu'il faut comprendre
Pourquoi Google fait-il une différence entre les types de fichiers XML ?
La réponse tient en deux mots : intention éditoriale. Un sitemap XML est conçu pour les moteurs de recherche — c'est un fichier de métadonnées destiné au crawl. Un flux RSS ou Atom, lui, sert à distribuer du contenu vers des agrégateurs, des lecteurs de flux, des applications tierces.
Google distingue ces formats en analysant le namespace XML déclaré dans la balise racine du document. Un sitemap utilise xmlns="http://www.sitemaps.org/schemas/sitemap/0.9", un RSS emploie xmlns="http://purl.org/rss/1.0/" ou simplement <rss version="2.0">. Le moteur lit cette signature et décide s'il doit ou non indexer le contenu.
Quel rôle joue le content-type header dans cette histoire ?
Le content-type HTTP est le second filtre. Si votre serveur renvoie application/xml ou text/xml, Google peut considérer le fichier comme indexable. En revanche, un application/rss+xml ou application/atom+xml signale explicitement qu'il s'agit d'un flux de syndication — et là, l'indexation est généralement bloquée.
Concrètement ? Même si votre RSS contient du texte structuré, Google ne le traitera pas comme une page HTML classique. Il le lira pour détecter des URL à crawler, mais le fichier lui-même ne sera pas considéré comme une ressource indexable.
Les podcasts feeds sont-ils un cas à part ?
Oui — et c'est la subtilité de cette déclaration. Les podcasts feeds, souvent construits sur une base RSS avec des extensions iTunes ou Spotify, peuvent être indexés par Google Podcasts. Mais attention : l'indexation ne se fait pas dans l'index web classique, elle alimente un index dédié aux contenus audio.
Cela signifie que le même fichier XML peut avoir deux destins selon le contexte : ignoré pour la recherche web, mais exploité pour la recherche vocale ou les applications de podcasts.
- Les sitemaps XML sont conçus pour être indexés par les moteurs de recherche
- Les flux RSS et Atom sont généralement exclus de l'indexation web
- Le namespace XML et le content-type header déterminent le traitement du fichier
- Les podcasts feeds peuvent être indexés dans un index dédié, pas dans l'index web principal
- Un même format XML peut donc recevoir un traitement différent selon son usage déclaré
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Globalement, oui — mais avec des nuances importantes. On observe effectivement que les flux RSS n'apparaissent pas dans les SERP comme des pages indexables. En revanche, Google utilise massivement les flux RSS pour découvrir du contenu frais, notamment sur les sites d'actualité. Il les crawle, extrait les URL, mais ne les indexe pas en tant que tels.
Le problème, c'est que Gary Illyes ne précise pas si cette règle s'applique aussi aux flux RSS mal configurés qui renvoient un content-type générique comme text/html. Dans ce cas, est-ce que Google peut indexer le fichier par erreur ? [A vérifier] — aucune donnée publique ne tranche cette question.
Quelles implications pour les sites qui exposent plusieurs formats XML ?
Beaucoup de CMS génèrent automatiquement des sitemaps, des flux RSS, des feeds Atom, voire des API XML. Si votre site expose tout ça sans distinction, vous risquez de diluer le signal envoyé à Google. Un crawler qui tombe sur cinq fichiers XML différents pour la même section de contenu peut interpréter ça comme du duplicate ou du spam.
Soyons honnêtes : la plupart des audits SEO ne regardent jamais le header HTTP des fichiers XML. On vérifie que le sitemap existe, qu'il est soumis dans la Search Console, et on passe à autre chose. Mais si votre flux RSS est servi avec le mauvais content-type, vous créez une surface d'attaque pour des indexations parasites.
Faut-il bloquer les flux RSS dans le robots.txt ?
Pas nécessairement. Si Google ne les indexe pas de toute façon, les bloquer n'apporte rien — et ça peut même nuire à la découverte rapide de nouveau contenu. En revanche, si vous constatez que vos flux apparaissent dans l'index (via une recherche site:votredomaine.com filetype:xml), là oui, il y a un problème de configuration.
Dans ce cas, vérifiez d'abord le content-type header. Si le serveur renvoie text/html ou application/xml au lieu de application/rss+xml, corrigez ça avant de toucher au robots.txt. Bloquer un fichier qu'on aurait pu exclure proprement via les headers HTTP, c'est un pansement sur une jambe de bois.
application/xml par défaut, ce qui peut changer le comportement de Google.Impact pratique et recommandations
Que faut-il vérifier sur votre site dès maintenant ?
Première étape : identifiez tous les fichiers XML exposés publiquement. Sitemap principal, sitemaps sectionnels, flux RSS, Atom, podcasts, API publiques. Listez-les avec leur URL complète.
Ensuite, testez le content-type header de chacun. Utilisez curl en ligne de commande (curl -I https://votresite.com/feed.xml) ou un outil comme Postman. Notez la valeur du champ Content-Type. Si vous voyez text/html sur un flux RSS, vous avez un problème.
Enfin, vérifiez le namespace XML dans le code source. Ouvrez chaque fichier et regardez la balise racine. Un sitemap doit déclarer xmlns="http://www.sitemaps.org/schemas/sitemap/0.9", un RSS doit avoir <rss version="2.0"> ou un namespace RSS 1.0. Si le namespace est absent ou générique, Google peut mal interpréter le fichier.
Comment éviter que Google indexe un fichier XML par erreur ?
La solution la plus propre : configurez le content-type header au niveau serveur. Sur Apache, ajoutez dans votre .htaccess :
AddType application/rss+xml .rss
AddType application/atom+xml .atomSur Nginx, dans la config du vhost :
location ~* \.rss$ {
add_header Content-Type application/rss+xml;
}Si vous utilisez WordPress, Drupal ou un autre CMS, vérifiez que le plugin ou le module qui génère les flux envoie bien le bon header. Certains thèmes mal codés forcent text/html sur tous les endpoints, y compris les feeds.
Faut-il inclure les flux RSS dans le sitemap XML ?
Non. Un sitemap liste des URL de contenu indexable, pas des fichiers de métadonnées. Mettre https://votresite.com/feed.xml dans votre sitemap ne sert à rien — et ça peut même brouiller le signal envoyé à Google.
En revanche, si vous avez un sitemap d'images ou un sitemap vidéo généré automatiquement, vérifiez qu'ils ne contiennent pas de référence vers des flux. Certains plugins WordPress cassent cette logique et créent des sitemaps hybrides qui mélangent pages, posts et feeds.
- Lister tous les fichiers XML publics de votre site
- Vérifier le content-type header de chaque fichier (curl -I ou Postman)
- Contrôler le namespace XML dans le code source
- Configurer le serveur pour renvoyer le bon content-type (Apache, Nginx, CDN)
- Ne jamais inclure les flux RSS dans le sitemap XML principal
- Tester l'indexation avec une recherche
site:votredomaine.com filetype:xml - Documenter la configuration pour les futures migrations ou changements de CMS
❓ Questions frequentes
Google peut-il indexer mon flux RSS si je ne fais rien ?
Un sitemap XML mal configuré peut-il être ignoré par Google ?
Les podcasts feeds apparaissent-ils dans les résultats de recherche classiques ?
Faut-il bloquer les flux RSS dans le robots.txt ?
Comment vérifier le content-type header d'un fichier XML ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/09/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.