Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Google indexe-t-il vraiment vos PDF ou les transforme-t-il d'abord ?
- □ Le poids du contenu varie-t-il selon son emplacement en HTML et en PDF ?
- □ Google dépend-il vraiment d'Adobe pour indexer vos PDF ?
- □ Google indexe-t-il vraiment le code source comme du texte ordinaire ?
- □ Pourquoi les fichiers de code source peinent-ils à se classer dans Google ?
- □ Faut-il vraiment arrêter de stocker tous vos PDF dans un dossier /pdfs/ ?
- □ Pourquoi Google n'indexe-t-il jamais une image isolée sans page d'hébergement ?
- □ Google indexe-t-il vraiment les images et vidéos différemment du texte ?
- □ Google filtre-t-il les données personnelles avant indexation ?
- □ L'extension de fichier (.html, .php, .txt) a-t-elle un impact sur le référencement Google ?
- □ Google indexe-t-il vraiment tous vos fichiers XML ?
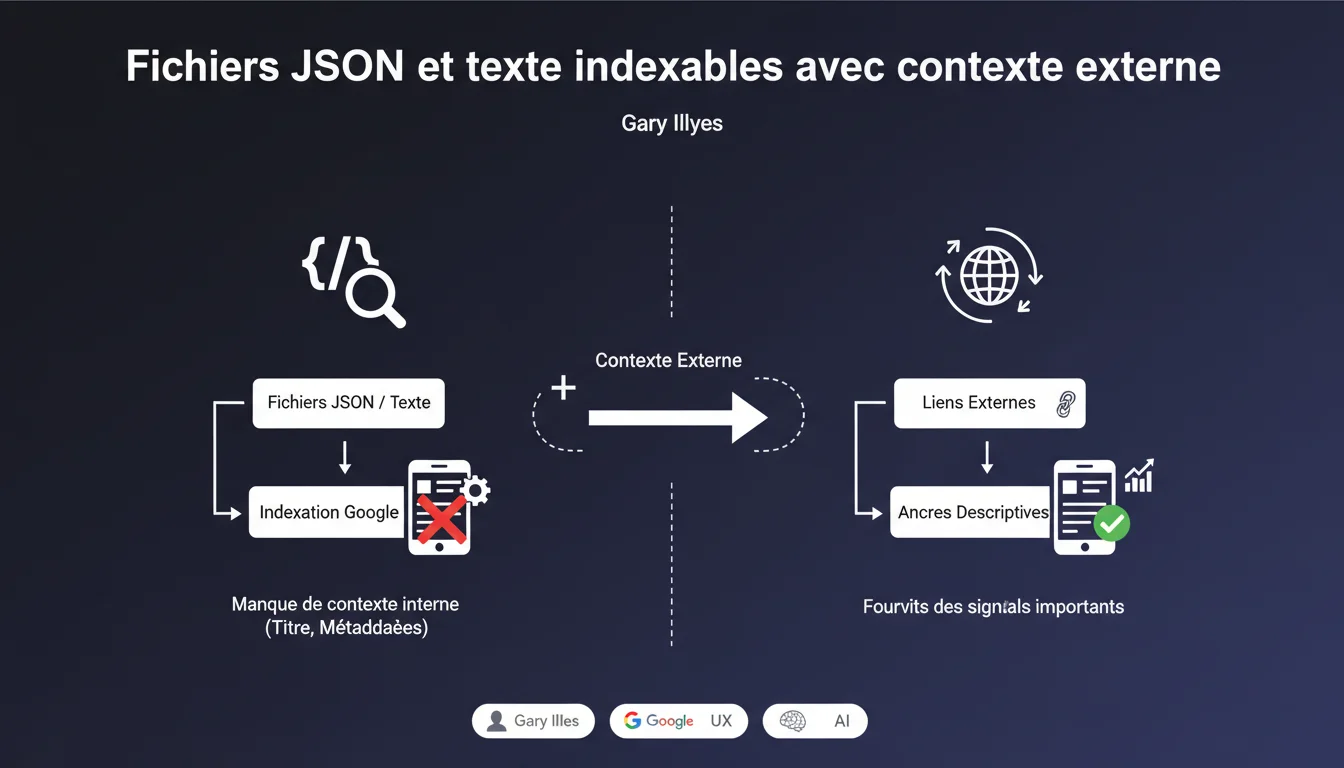
Google peut indexer et afficher des fichiers JSON et texte brut dans les SERP, même sans titre ni méta-données. Le moteur s'appuie alors massivement sur le contexte externe : ancres de liens, texte environnant, signaux de pertinence fournis par les pages qui pointent vers ces fichiers. C'est une révélation importante pour la stratégie de linking interne et externe.
Ce qu'il faut comprendre
Google indexe-t-il vraiment des fichiers sans structure HTML classique ?
Oui. Gary Illyes confirme explicitement que les fichiers JSON et les fichiers texte brut (.txt, .json) peuvent être indexés et apparaître dans les résultats de recherche. Pas besoin d'enrobage HTML.
Le moteur traite ces fichiers comme des documents à part entière, même s'ils manquent des balises conventionnelles (title, meta description, h1). C'est une nuance souvent ignorée : beaucoup supposent que seules les pages HTML structurées sont éligibles à l'indexation. Faux.
Pourquoi est-ce si difficile de classer ces fichiers dans les résultats ?
Parce qu'ils sont aveugles sémantiquement. Sans titre interne, sans hiérarchie de contenu (pas de headings), Google ne peut pas s'appuyer sur les signaux on-page habituels pour déterminer de quoi parle le fichier.
Résultat : le moteur doit reconstituer le sens à partir de signaux externes. C'est là que les ancres de liens deviennent critiques — elles fournissent le contexte manquant. Un fichier JSON pointé par 50 liens avec des ancres descriptives comme "API tarifs 2023" aura une chance de se classer. Sans ces signaux, il reste dans les limbes de l'index.
Quel rôle jouent les liens externes et leurs ancres ?
Ils deviennent le pilier sémantique. L'ancre d'un lien entrant agit comme un proxy de titre — elle dit à Google : "ce fichier parle de X". Plus les ancres sont cohérentes et descriptives, plus le moteur peut construire une représentation thématique fiable.
Concrètement : un fichier JSON exposé via une API technique, sans titre ni meta, peut quand même remonter dans les SERP si des pages tierces (documentation, forums, blogs) le citent avec des ancres précises. C'est un rappel brutal que le contexte externe forge la perception interne.
- Les fichiers JSON et texte peuvent être indexés même sans méta-données classiques
- Le manque de structure interne rend le classement difficile mais pas impossible
- Les ancres de liens externes fournissent les signaux sémantiques manquants
- La cohérence des ancres pointant vers ces fichiers devient un facteur de ranking critique
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui — et c'est même vérifiable. On observe régulièrement des fichiers .json, .xml, voire .txt dans les SERP, notamment pour des requêtes techniques (API docs, datasets, logs publics). Mais leur position est généralement médiocre, sauf si le fichier est massivement cité avec des ancres riches.
Ça colle avec l'explication de Gary : Google peut les indexer, mais sans aide externe, il ne sait pas quoi en faire. Les cas où ces fichiers rankent bien ? Toujours les mêmes : des liens nombreux et descriptifs depuis des pages autoritaires. Pas de miracle.
Quelles nuances faut-il apporter à cette règle ?
Premier point : contexte ne veut pas dire volume. Ce n'est pas parce qu'un fichier JSON reçoit 1000 liens spammy avec des ancres génériques ("cliquez ici", "télécharger") qu'il va bien se classer. La qualité sémantique des ancres prime sur la quantité brute.
Deuxième point : [A verifier] la notion de "suffisamment de contexte" reste floue. Gary ne donne aucun seuil, aucun ratio liens/ancres descriptives. On sait que ça marche parfois, mais impossible de prédire à partir de combien de signaux externes Google bascule un fichier orphelin vers un statut "classable". C'est frustrant pour la planification SEO.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si le fichier est bloqué par robots.txt ou X-Robots-Tag, évidemment. Mais aussi : si le fichier est techniquement accessible mais n'est jamais lié — ni en interne ni en externe — il restera invisible. Pas de signaux = pas de ranking, même si Google l'a crawlé.
Autre limite : les fichiers JSON imbriqués dans des flux authentifiés (API privées, tokens). Même si Google crawle l'URL publique, sans accès au contenu complet, il ne peut rien indexer de substantiel. Le contexte externe ne compense pas un contenu inaccessible.
Impact pratique et recommandations
Que faut-il faire concrètement si on expose des fichiers JSON ou texte publiquement ?
D'abord, décide si tu veux qu'ils soient indexés. Si non : robots.txt ou X-Robots-Tag: noindex sur ces fichiers. Si oui : construis délibérément le contexte externe.
Concrètement ? Crée une page de documentation ou un article de blog qui présente le fichier, avec un lien vers lui portant une ancre descriptive. Exemple : au lieu de "[Télécharger le fichier](fichier.json)", écris "[Télécharger les données tarifaires au format JSON](fichier.json)". Cette ancre devient le titre implicite du fichier aux yeux de Google.
Quelles erreurs éviter absolument ?
Erreur classique : laisser des fichiers JSON ou .txt en accès libre sans aucun lien interne ni externe. Résultat : Google peut les crawler par hasard (via un lien indirect, un sitemap oublié), les indexer, et les afficher dans les SERP avec un snippet vide ou absurde. Mauvais signal UX.
Autre piège : utiliser des ancres génériques partout ("voir ici", "fichier", "download"). Sans ancre descriptive, Google n'a aucun indice sémantique. Le fichier reste indexable techniquement, mais invisible en pratique.
Comment vérifier que ces fichiers sont traités correctement ?
Utilise la Google Search Console. Inspecte l'URL du fichier JSON ou .txt : est-il indexé ? Si oui, regarde le snippet tel que Google le génère. S'il est vide ou incohérent, c'est un symptôme de manque de contexte.
Ensuite, fais une recherche site:tondomaine.com filetype:json (ou filetype:txt). Tu verras tous les fichiers de ce type indexés. Pour chacun, vérifie : y a-t-il des liens pointant vers lui ? Avec quelles ancres ? Si la réponse est "aucun", soit tu ajoutes du contexte, soit tu bloques l'indexation.
- Décider explicitement si chaque fichier JSON/texte doit être indexé
- Bloquer l'indexation via robots.txt ou X-Robots-Tag si nécessaire
- Créer des pages de contexte (doc, blog) qui lient vers ces fichiers avec des ancres descriptives
- Éviter les ancres génériques ("cliquez ici", "télécharger") — privilégier des ancres sémantiquement riches
- Vérifier régulièrement dans la Search Console quels fichiers non-HTML sont indexés
- Auditer les snippets Google de ces fichiers pour détecter les problèmes de contexte
❓ Questions frequentes
Un fichier JSON sans aucun lien interne peut-il quand même être indexé par Google ?
Faut-il créer un sitemap dédié pour les fichiers JSON que je veux indexer ?
Les ancres de liens internes fonctionnent-elles aussi bien que les ancres externes pour donner du contexte ?
Dois-je ajouter des balises meta dans mes fichiers JSON pour aider Google ?
Comment bloquer l'indexation d'un fichier JSON sans bloquer son accès public ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/09/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.