Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Google indexe-t-il vraiment vos PDF ou les transforme-t-il d'abord ?
- □ Le poids du contenu varie-t-il selon son emplacement en HTML et en PDF ?
- □ Google dépend-il vraiment d'Adobe pour indexer vos PDF ?
- □ Google indexe-t-il vraiment le code source comme du texte ordinaire ?
- □ Pourquoi les fichiers de code source peinent-ils à se classer dans Google ?
- □ Faut-il vraiment arrêter de stocker tous vos PDF dans un dossier /pdfs/ ?
- □ Pourquoi Google n'indexe-t-il jamais une image isolée sans page d'hébergement ?
- □ Google indexe-t-il vraiment les images et vidéos différemment du texte ?
- □ L'extension de fichier (.html, .php, .txt) a-t-elle un impact sur le référencement Google ?
- □ Google indexe-t-il vraiment tous vos fichiers XML ?
- □ Peut-on vraiment indexer des fichiers JSON et texte brut sans méta-données ?
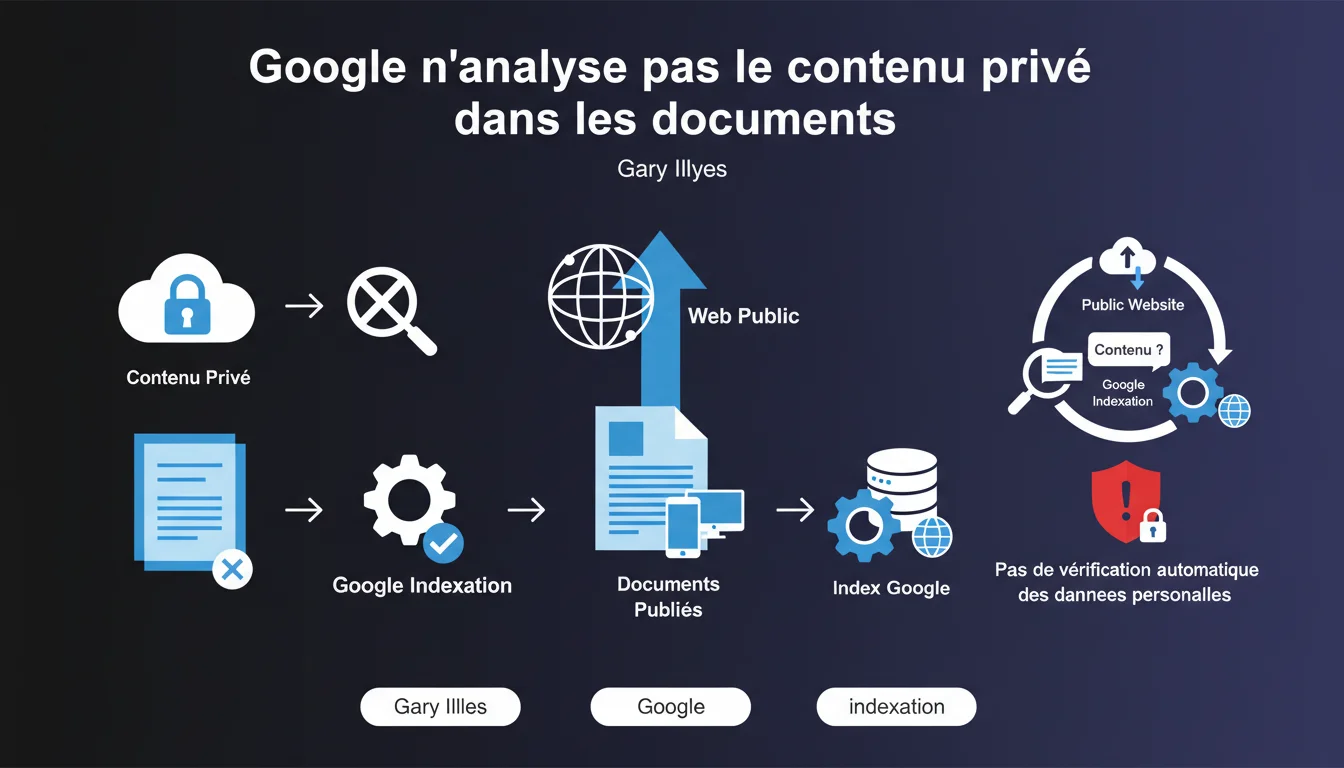
Google indexe tout contenu accessible sur le web public sans analyse préalable du caractère privé des informations. Si un document contenant des données personnelles est mis en ligne sur un serveur public, il sera indexé comme n'importe quelle autre page. La responsabilité de la protection incombe exclusivement au propriétaire du site, pas au moteur de recherche.
Ce qu'il faut comprendre
Google procède-t-il à un filtrage éditorial du contenu indexé ?
La réponse est non, catégoriquement. Le crawler de Google ne dispose d'aucun mécanisme d'analyse sémantique destiné à identifier des informations sensibles avant indexation. Un document PDF contenant des numéros de sécurité sociale, un fichier Excel avec des coordonnées bancaires ou une page HTML listant des données médicales — si ces ressources sont accessibles publiquement, elles entrent dans l'index.
Le processus d'indexation fonctionne sur un principe binaire : accessible ou non accessible. Il n'existe pas de zone grise où Google évaluerait la nature du contenu pour décider s'il mérite ou non d'être indexé. Cette logique s'applique indépendamment du format — HTML, PDF, DOCX, XLSX.
Quelle différence entre « public » et « privé » pour Google ?
Un contenu est considéré comme public dès lors qu'il est techniquement crawlable : pas de blocage robots.txt, pas d'authentification requise, pas de noindex. Peu importe l'intention initiale du propriétaire du site.
Un cas fréquent : des fichiers uploadés dans un répertoire /uploads/ ou /documents/ sans protection. Le webmaster pensait ces fichiers « privés » parce que non linkés depuis le site. Sauf qu'un lien externe, une mention dans un fichier sitemap XML ou une découverte via un répertoire mal configuré suffit pour que Google les trouve.
Quelles sont les implications légales de cette politique d'indexation ?
Google se positionne clairement : la responsabilité de la protection des données incombe au webmaster, pas au moteur de recherche. C'est cohérent avec le cadre juridique actuel — un moteur de recherche n'est pas considéré comme hébergeur de contenu mais comme intermédiaire technique.
Sous RGPD, c'est le responsable du traitement (celui qui met les données en ligne) qui engage sa responsabilité. Google propose des outils de suppression a posteriori (Search Console, formulaires de demande de désindexation), mais n'effectue aucune vérification préventive.
- Aucun filtrage automatique des informations personnelles avant indexation
- Responsabilité totale du webmaster quant à la protection des contenus sensibles
- Distinction binaire : accessible = indexable, protégé = non indexable
- Outils de suppression disponibles mais uniquement après indexation
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Totalement. On voit régulièrement des fuites de données indexées : factures clients, contrats, documents RH, fichiers comptables. Ces cas ne résultent jamais d'un « bug » de Google, mais d'une mauvaise configuration côté serveur — répertoires ouverts, absence de .htaccess, fichiers orphelins accessibles par URL directe.
Un exemple récurrent concerne les sites sous WordPress avec des plugins de gestion documentaire mal configurés. Les fichiers uploadés deviennent accessibles via une URL prédictible, aucun noindex n'est appliqué, et bam — indexation dans les 48h si le crawl est actif.
Quelles nuances méritent d'être apportées ?
Google dispose bien de mécanismes de détection pour certains types de contenus — contenu pédopornographique, malware, hameçonnage — mais ces filtres relèvent de la sécurité utilisateur, pas de la protection de la vie privée au sens RGPD. Ce sont deux problématiques distinctes.
Par ailleurs, même si Google n'analyse pas le contenu avant indexation, certains signaux peuvent retarder ou limiter l'indexation : sites à faible autorité, pages orphelines sans liens entrants, crawl budget insuffisant. Mais ce n'est jamais lié à la nature privée des informations — c'est purement technique.
[A vérifier] : Gary Illyes ne précise pas comment Google gère les cas où un site mixte contient à la fois du contenu public légitime et des documents sensibles mal protégés. Y a-t-il un impact sur la perception globale du domaine ? Aucune donnée publique à ce sujet.
Dans quels cas cette règle semble-t-elle poser problème ?
Le principal angle mort concerne les sites de collectivités, d'associations ou de TPE gérés par des non-techniciens. Ces acteurs ignorent souvent les implications d'un upload de fichier sur un serveur public. Un compte-rendu de réunion avec noms et adresses, un fichier Excel d'adhérents — indexés avant même qu'on s'en aperçoive.
Autre cas : les espaces clients mal sécurisés. Un espace membre accessible sans authentification mais « caché » derrière une URL non linkée — Google finira par le trouver si quelqu'un partage le lien ou si un sitemap le référence.
Impact pratique et recommandations
Comment protéger efficacement les contenus sensibles contre l'indexation ?
Première mesure : sécuriser l'accès au niveau serveur. Un fichier .htaccess (Apache) ou une règle nginx pour bloquer l'accès public à certains répertoires. Pas de noindex ici — on empêche carrément l'accès HTTP.
Deuxième levier : l'authentification obligatoire pour tout espace contenant des données personnelles. Google ne crawle pas les zones protégées par login. C'est la barrière la plus fiable.
Troisième point : auditer régulièrement les répertoires accessibles via une recherche site:votredomaine.com filetype:pdf ou filetype:xlsx. Vous verrez immédiatement ce que Google a indexé. Si un document sensible apparaît, suppression d'urgence via Search Console et blocage serveur.
Quelles erreurs critiques faut-il absolument éviter ?
Erreur n°1 : compter uniquement sur robots.txt pour bloquer l'indexation de fichiers sensibles. Un robots.txt bloque le crawl mais n'empêche pas l'indexation si le fichier est découvert via un lien externe. Google peut indexer l'URL sans avoir crawlé le contenu.
Erreur n°2 : uploader des fichiers sans vérifier leur contenu. Un PDF généré automatiquement peut contenir des métadonnées sensibles, des commentaires cachés, des informations d'auteur. Toujours nettoyer les fichiers avant publication.
Erreur n°3 : penser qu'un document « non linké » reste invisible. Si l'URL est prédictible (/uploads/2023/facture-client-X.pdf), un bot ou un humain peut la deviner. La sécurité par obscurité ne fonctionne jamais longtemps.
Quelle checklist appliquer pour sécuriser un site existant ?
- Auditer tous les répertoires publics via
site:et recherches par filetype - Configurer .htaccess ou nginx pour bloquer l'accès aux dossiers sensibles (/uploads, /documents, /clients)
- Mettre en place une authentification pour tout espace contenant des données personnelles
- Vérifier que le fichier robots.txt ne bloque pas des URLs déjà indexées (elles resteraient dans l'index)
- Nettoyer les métadonnées de tous les fichiers uploadés (PDF, Office, images EXIF)
- Utiliser Search Console pour demander la suppression urgente de toute URL sensible déjà indexée
- Implémenter une politique de génération d'URLs non prédictibles (tokens, UUIDs) pour les fichiers uploadés
- Former les contributeurs du site aux bonnes pratiques de publication de documents
❓ Questions frequentes
Google peut-il indexer un fichier PDF uploadé dans un répertoire non linké ?
Un robots.txt suffit-il à bloquer l'indexation de documents sensibles ?
Combien de temps faut-il pour qu'un document sensible soit désindexé après une demande via Search Console ?
Les espaces clients protégés par un simple paramètre d'URL sont-ils sécurisés contre l'indexation ?
Google supprime-t-il automatiquement les contenus signalés comme contenant des données personnelles ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/09/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.