Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Le poids du contenu varie-t-il selon son emplacement en HTML et en PDF ?
- □ Google dépend-il vraiment d'Adobe pour indexer vos PDF ?
- □ Google indexe-t-il vraiment le code source comme du texte ordinaire ?
- □ Pourquoi les fichiers de code source peinent-ils à se classer dans Google ?
- □ Faut-il vraiment arrêter de stocker tous vos PDF dans un dossier /pdfs/ ?
- □ Pourquoi Google n'indexe-t-il jamais une image isolée sans page d'hébergement ?
- □ Google indexe-t-il vraiment les images et vidéos différemment du texte ?
- □ Google filtre-t-il les données personnelles avant indexation ?
- □ L'extension de fichier (.html, .php, .txt) a-t-elle un impact sur le référencement Google ?
- □ Google indexe-t-il vraiment tous vos fichiers XML ?
- □ Peut-on vraiment indexer des fichiers JSON et texte brut sans méta-données ?
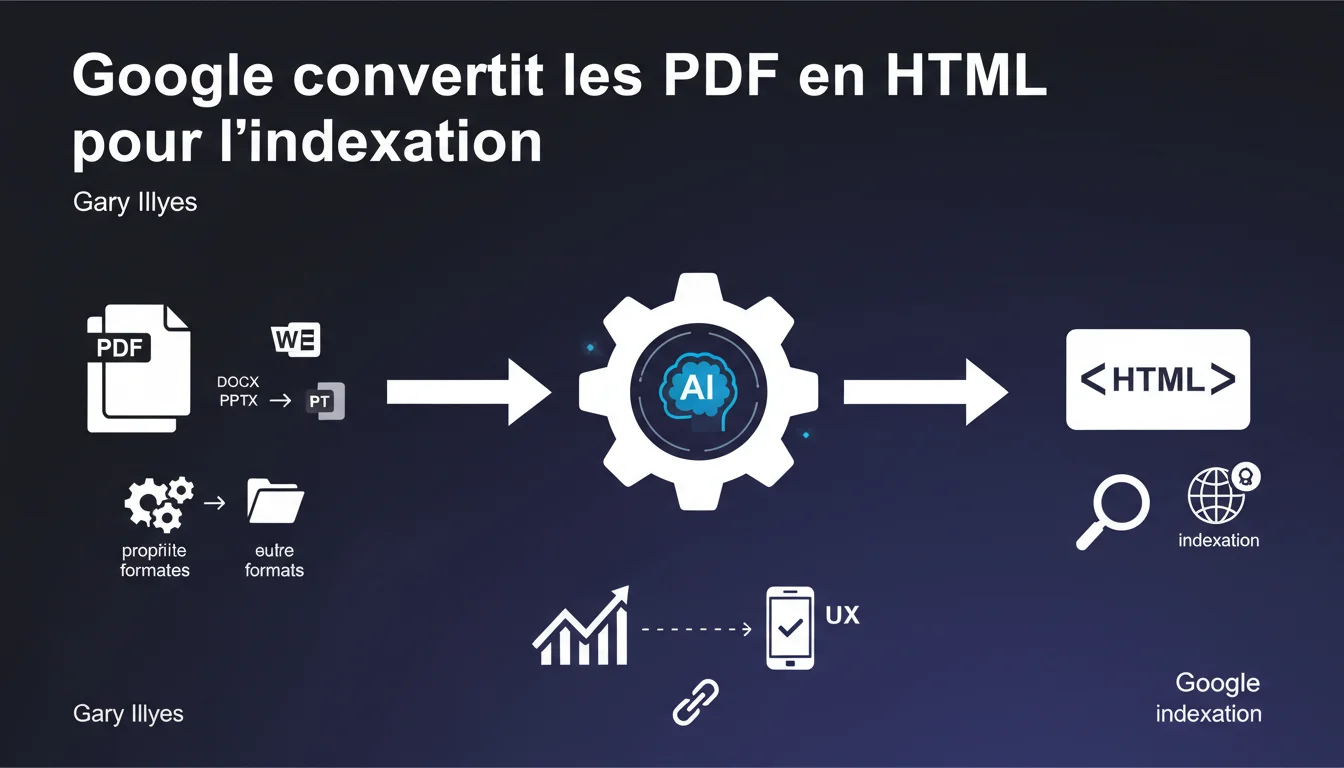
Google ne indexe jamais directement vos fichiers PDF. Chaque document — PDF, Word, PowerPoint — passe par une conversion en HTML avant d'entrer dans l'index. Cette transformation extrait le texte, les images et les métadonnées, ce qui peut impacter la façon dont votre contenu est compris et classé.
Ce qu'il faut comprendre
Pourquoi Google convertit-il les PDF en HTML au lieu de les indexer directement ?
La raison est simple : l'uniformité du traitement. Google fonctionne avec un index basé sur du HTML. Plutôt que de développer des systèmes d'indexation distincts pour chaque format propriétaire, le moteur convertit tout en HTML avant de passer à l'analyse sémantique et au classement.
Cette approche permet aussi d'extraire proprement les métadonnées, le texte et les images sans se heurter aux spécificités de chaque format. Un PDF peut contenir des calques, des annotations, des polices embarquées — autant d'éléments qui n'ont pas d'équivalent direct dans l'index de Google.
Qu'est-ce que cela change concrètement pour le référencement de vos documents ?
Ça signifie que la structure interne de votre PDF compte énormément. Si votre document est mal balisé (pas de texte sélectionnable, images scannées sans OCR, absence de métadonnées), la conversion en HTML sera bancale. Google risque de passer à côté de pans entiers de votre contenu.
À l'inverse, un PDF bien structuré — avec des titres hiérarchisés, du texte réel, des balises alt sur les images — facilitera l'extraction et améliorera votre visibilité. C'est là que beaucoup de sites perdent des positions sans comprendre pourquoi.
Tous les formats propriétaires subissent-ils le même traitement ?
Oui. Word, PowerPoint, Excel, Pages — tous passent par cette conversion. Gary Illyes ne détaille pas le processus exact, mais on sait que Google utilise des convertisseurs internes pour transformer ces formats en HTML exploitable.
Concrètement, cela veut dire que votre présentation PowerPoint sera indexée comme une suite de pages HTML. Si elle contient du texte dans des zones de commentaires ou des notes non visibles, Google peut ou non les extraire — il n'y a aucune garantie officielle là-dessus.
- Google ne indexe jamais directement les PDF — tout passe par une conversion HTML
- Le processus s'applique aussi aux documents Word, PowerPoint, Excel et autres formats propriétaires
- La conversion extrait texte, images et métadonnées, mais la qualité de l'extraction dépend de la structure du document source
- Un PDF mal balisé ou scanné sans OCR sera partiellement ou mal indexé
- Les métadonnées (titre, auteur, description) jouent un rôle dans la compréhension du contenu par Google
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Totalement. Depuis des années, les SEO observent que les PDF bien structurés rankent mieux que les scans ou les documents mal formatés. Cette déclaration confirme ce qu'on savait empiriquement : Google ne lit pas le PDF « en natif », il le transforme.
Ça explique aussi pourquoi certains PDF apparaissent dans les SERP avec des extraits tronqués ou des métadonnées incorrectes. Si la conversion échoue à extraire proprement les informations, Google fait avec ce qu'il a — et ça peut donner n'importe quoi.
Quelles nuances faut-il apporter à cette affirmation ?
Gary Illyes reste vague sur la profondeur de l'extraction. Est-ce que Google récupère les annotations, les calques masqués, les métadonnées EXIF des images embarquées ? [À vérifier] — aucune documentation officielle ne le précise.
De même, rien n'indique si Google respecte les balises de structure PDF/UA (accessibilité). En théorie, un PDF bien balisé avec des tags sémantiques devrait faciliter la conversion. En pratique, personne ne sait si Google exploite vraiment ces informations ou s'il se contente d'un parsing basique.
Dans quels cas cette règle pourrait-elle poser problème ?
Si vous publiez des documents complexes avec des tableaux, des graphiques, des schémas, la conversion HTML peut massacrer la mise en page. Google extraira le texte, mais la structure logique — celle qui donne du sens au contenu — risque de se perdre.
Autre cas : les PDF protégés ou chiffrés. Si Google ne peut pas ouvrir le fichier pour le convertir, il ne l'indexera tout simplement pas. Idem pour les PDF derrière des formulaires ou des paywalls — la conversion n'aura jamais lieu.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser vos PDF ?
Première étape : assurez-vous que votre PDF contient du texte sélectionnable. Si c'est un scan, passez-le par un OCR de qualité avant publication. Google peut tenter de le faire, mais autant contrôler le résultat vous-même.
Ensuite, remplissez les métadonnées du document : titre, auteur, description, mots-clés. Ces informations sont extraites lors de la conversion et peuvent influencer le classement. Un PDF sans métadonnées, c'est comme une page HTML sans balise title.
Troisième point : structurez votre document avec des titres hiérarchisés. Si vous utilisez des styles H1, H2, H3 dans Word avant conversion en PDF, Google pourra mieux comprendre la structure logique. C'est du balisage sémantique, version document bureautique.
Quelles erreurs éviter absolument ?
Ne publiez jamais un PDF généré à partir d'images sans OCR. C'est la garantie d'une indexation catastrophique. Google ne verra qu'une suite de blocs images sans texte exploitable.
Évitez aussi les PDF trop lourds avec des centaines de pages. Si le document pèse 50 Mo, Google peut décider de ne pas le crawler entièrement ou de l'abandonner en cours de route. Découpez en fichiers plus petits si possible.
Dernière erreur classique : ne pas tester la conversion. Ouvrez votre PDF dans un lecteur, essayez de copier-coller le texte. Si ça ne fonctionne pas proprement, Google aura les mêmes difficultés.
- Vérifier que le PDF contient du texte sélectionnable (pas uniquement des images scannées)
- Remplir les métadonnées du document (titre, auteur, description) avant publication
- Utiliser une structure de titres (H1, H2, H3) pour faciliter l'extraction sémantique
- Ajouter des balises alt aux images embarquées dans le PDF (si le format le permet)
- Limiter le poids du fichier pour éviter les abandons de crawl
- Tester la sélection de texte manuellement pour détecter les problèmes d'extraction
- Éviter les protections par mot de passe ou chiffrement qui bloquent l'accès à Google
❓ Questions frequentes
Google peut-il indexer un PDF protégé par mot de passe ?
Les images dans un PDF sont-elles indexées par Google ?
Un PDF scanné sans OCR peut-il être indexé ?
Les métadonnées d'un PDF influencent-elles le classement ?
Faut-il préférer HTML ou PDF pour du contenu à forte valeur SEO ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/09/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.