Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ L'expérience de page suffit-elle vraiment à garantir une bonne UX pour Google ?
- □ Faut-il vraiment penser aux utilisateurs avant les machines en SEO ?
- □ Tirets vs underscores dans les URLs : pourquoi Google préfère-t-il l'un à l'autre ?
- □ Le contenu masqué dans les accordéons pénalise-t-il votre référencement ?
- □ Le contenu caché est-il devenu aussi important que le contenu visible pour Google ?
- □ Pourquoi Google ignore-t-il votre navigation si elle n'utilise pas de vrais liens anchor ?
- □ Les Core Web Vitals suffisent-ils vraiment à mesurer l'expérience utilisateur ?
- □ Pourquoi Google refuse-t-il de donner des critères précis sur certains aspects de l'UX ?
- □ Les URLs lisibles et cohérentes sont-elles vraiment un critère de ranking ?
- □ L'accessibilité web influence-t-elle directement le classement dans Google ?
- □ Lighthouse rate-t-il vraiment la qualité de vos ancres de liens ?
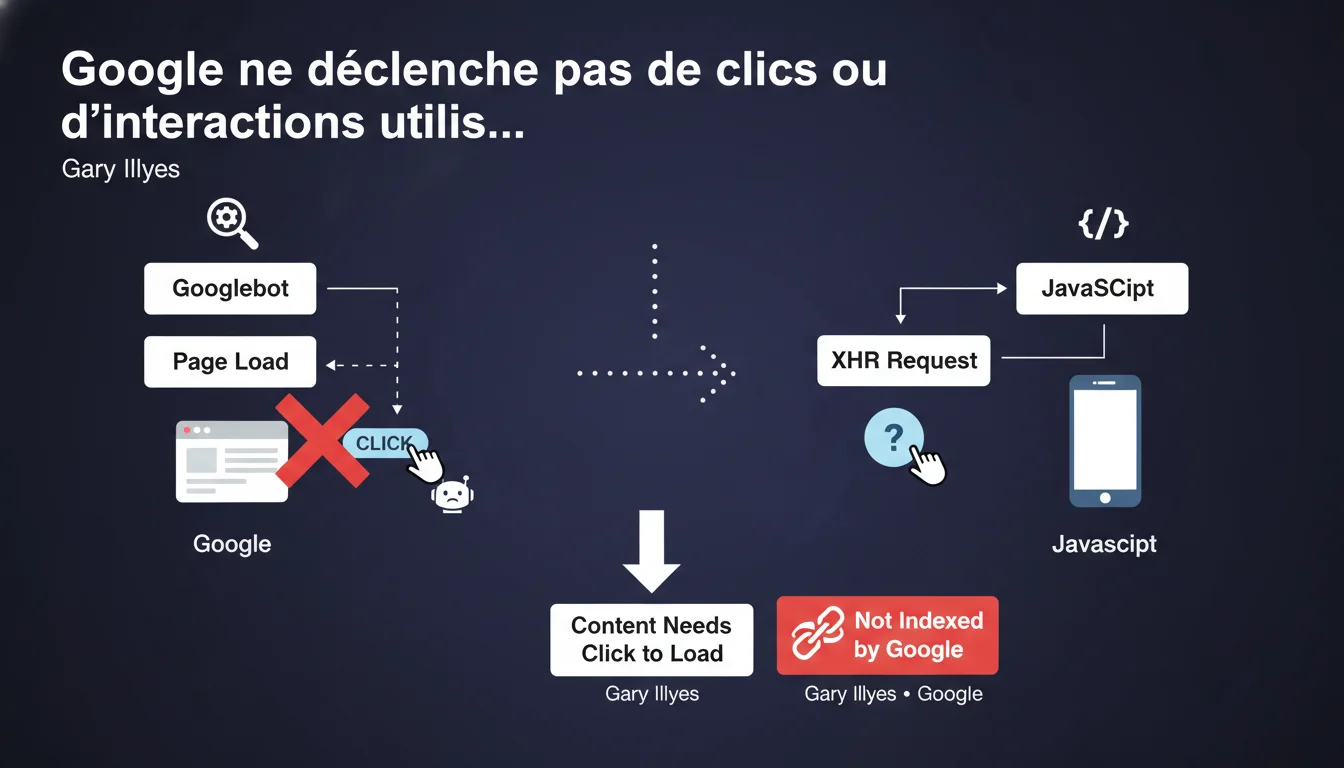
Googlebot ne déclenche aucune interaction utilisateur comme les clics. Si du contenu charge via une requête XHR après un clic, Google ne le verra probablement pas. Cette limitation impacte directement l'indexation des sites en JavaScript moderne.
Ce qu'il faut comprendre
Pourquoi Googlebot ne clique-t-il pas sur les éléments interactifs ?
Googlebot est conçu pour crawler et indexer du contenu statique, pas pour simuler un comportement humain. Il exécute le JavaScript initial d'une page, mais ne déclenche pas d'événements utilisateur comme les clics, les survols ou les scrolls.
Concrètement, si votre contenu nécessite un clic pour charger — typiquement via une requête XHR ou fetch déclenchée par JavaScript — ce contenu restera invisible pour Google. Cette déclaration confirme une réalité que les praticiens SEO observent depuis des années.
Qu'est-ce qu'une requête XHR exactement ?
XHR (XMLHttpRequest) est une API JavaScript permettant de charger du contenu de manière asynchrone, sans recharger la page. Fetch est son équivalent moderne.
Ces requêtes sont omniprésentes dans les interfaces modernes : onglets chargeant du contenu au clic, boutons « Voir plus », modales avec contenu dynamique, filtres de recherche. Tout ce qui charge sans navigation complète utilise probablement XHR ou fetch.
Cela concerne-t-il uniquement les anciens sites ?
Non, et c'est là le piège. De nombreux frameworks modernes (React, Vue, Angular) utilisent massivement ces patterns. Un site techniquement récent peut être complètement invisible pour Google si son architecture repose sur des interactions utilisateur.
Les sites e-commerce avec filtres dynamiques, les plateformes SaaS avec interfaces par onglets, les sites d'actualités avec lazy-loading au scroll — tous sont potentiellement concernés.
- Googlebot n'exécute pas de clics — aucune interaction utilisateur n'est simulée
- Le contenu chargé via XHR/fetch après un clic reste invisible
- Cette limitation s'applique aux sites modernes en JavaScript autant qu'aux anciens
- L'indexation dépend du rendu initial de la page, pas du comportement utilisateur
- Les frameworks modernes aggravent parfois le problème en masquant cette limitation derrière une UX fluide
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Totalement. Les SEO qui auditent des sites JavaScript le constatent quotidiennement : du contenu présent visuellement disparaît des rapports d'inspection d'URL. La corrélation avec les interactions utilisateur est systématique.
Le problème, c'est que Google reste volontairement vague sur la profondeur d'exécution JavaScript. Ils disent « nous exécutons le JS », mais ne précisent pas jusqu'où. Cette déclaration lève un coin du voile — mais soulève d'autres questions.
Quelles nuances faut-il apporter ?
D'abord, « probablement pas » n'est pas « jamais ». Gary Illyes utilise un conditionnel qui laisse une marge d'interprétation. Dans certains cas observés, du contenu chargé dynamiquement apparaît indexé — sans qu'on comprenne exactement pourquoi. [À vérifier]
Ensuite, cette règle ne s'applique qu'au crawl et à l'indexation initiale. Pour les Core Web Vitals et les métriques UX, Google utilise des données utilisateurs réels (CrUX) — donc le comportement post-clic compte pour le ranking, même s'il n'est pas crawlé.
Enfin, attention : un contenu invisible pour Googlebot peut quand même être découvert via les liens internes. Si une page A affiche un lien vers une page B après un clic, Googlebot ne verra pas ce lien — mais si B est accessible ailleurs, elle sera indexée normalement.
Dans quels cas cette règle ne s'applique-t-elle pas complètement ?
Il existe des zones grises. Certains crawlers de Google (Google Images, Discover) semblent avoir des comportements légèrement différents. Des images chargées en lazy-loading au scroll sont parfois indexées — mais c'est probablement parce que Google simule un viewport plus grand, pas parce qu'il scroll réellement.
De même, les Progressive Web Apps (PWA) avec Service Workers peuvent pre-render du contenu côté client — dans ces cas, le contenu est techniquement présent au chargement initial, donc visible pour Googlebot. Mais c'est une exception architecturale, pas une capacité de crawl.
Impact pratique et recommandations
Que faut-il faire concrètement sur un site existant ?
Première étape : auditer tous les contenus chargés dynamiquement. Identifiez les onglets, accordéons, modales, filtres, boutons « Voir plus » qui déclenchent des requêtes réseau. Vérifiez ensuite avec l'outil d'inspection d'URL si ce contenu apparaît dans le rendu Google.
Si du contenu stratégique est invisible, deux solutions : soit le pré-charger dans le HTML initial (masqué en CSS, révélé au clic), soit implémenter du Server-Side Rendering (SSR) ou de l'hydratation statique. Pas de demi-mesure — le contenu doit être dans le DOM au chargement.
Quelles erreurs éviter absolument ?
Ne vous fiez jamais à ce que vous voyez dans votre navigateur. Un site peut sembler parfait visuellement et être totalement vide pour Googlebot. Testez systématiquement avec les outils Google (Search Console, inspection d'URL, Mobile-Friendly Test).
Autre piège : ne comptez pas sur le « lazy-loading intelligent ». Même si un framework prétend gérer le SEO, vérifiez. J'ai vu des sites Next.js ou Nuxt.js mal configurés perdre 70% de leur contenu indexable parce que les devs avaient désactivé le SSR pour « améliorer les perfs ».
Enfin, évitez les solutions hybrides bancales. Un site qui mélange SSR et client-side rendering sans logique claire devient impossible à maintenir et génère des incohérences d'indexation.
Comment vérifier que mon site est conforme ?
- Crawlez votre site avec Screaming Frog en mode JavaScript activé et comparez avec un crawl JavaScript désactivé
- Utilisez l'outil d'inspection d'URL sur vos pages clés et examinez le HTML rendu
- Vérifiez que le contenu stratégique apparaît dans « Afficher le code source » (Ctrl+U), pas seulement dans l'inspecteur
- Testez vos filtres, onglets et accordéons : le contenu doit être présent dans le DOM initial, même masqué
- Si vous utilisez un framework JS, validez que le SSR ou la génération statique est active
- Surveillez vos URL indexées dans Search Console — une chute brutale signale souvent un problème de rendu
- Documentez les patterns d'interaction et leur impact SEO pour les futurs développements
❓ Questions frequentes
Googlebot exécute-t-il le JavaScript moderne (ES6+) ?
Le lazy-loading d'images pose-t-il le même problème ?
Un site en React ou Vue est-il forcément problématique ?
Les Single Page Applications (SPA) peuvent-elles être SEO-friendly ?
Comment tester si Googlebot voit mon contenu dynamique ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.