Official statement
What you need to understand
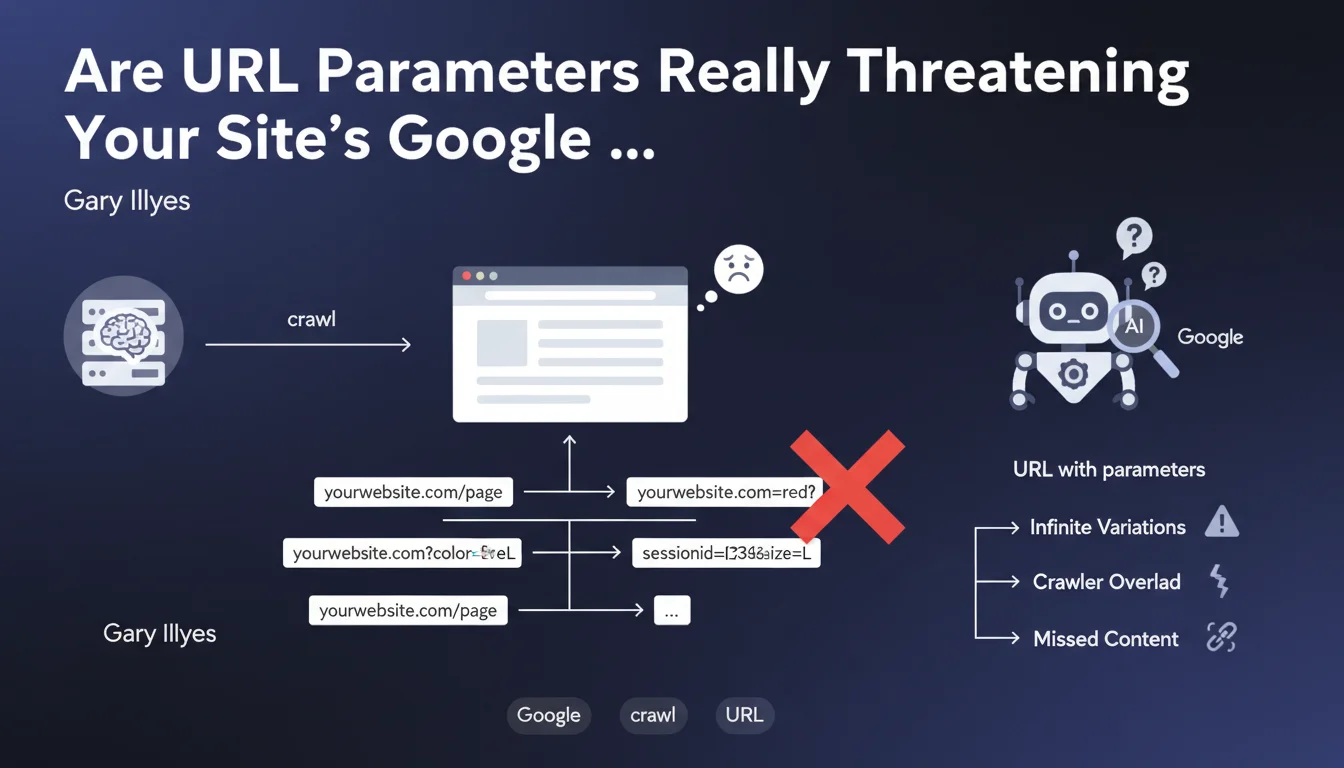
Google has revealed a major technical issue concerning URL parameters and their impact on website crawling. The finding is simple yet critical: a server can technically accept a virtually infinite number of parameters added to a URL, even if these parameters don't change the displayed content in any way.
This technical characteristic creates a trap for Google's crawler. When Googlebot explores a site by following links, it can find itself facing hundreds or thousands of URL variations pointing to the same content. Each parameter combination generates a unique URL that the bot must theoretically crawl.
E-commerce sites are particularly vulnerable to this phenomenon. Product filters, sorting options, session identifiers, and tracking parameters can exponentially multiply the number of crawlable URLs.
- Artificial inflation of the number of URLs for Google to crawl
- Risk of crawl budget waste on duplicate pages
- Problem amplified on sites with filters and facets (e-commerce, directories)
- Direct impact on the indexing efficiency of important content
- Difficulty for Google to determine the canonical URL to index
SEO Expert opinion
This statement confirms what SEO practitioners have been observing for years in the field. Sites with poor URL parameter management consistently show problematic signals in Search Console: explosion in the number of crawled pages, discovered but not indexed pages, and inefficient crawl budget consumption.
What's particularly interesting is the explicit recognition that the problem stems from the very nature of link-following crawling. Google can't always predict in advance which parameters are significant or not. This limitation explains why even well-structured sites can suffer from this issue if they generate internal links with parameters.
It should also be noted that not all parameters are problematic. Purely analytical tracking parameters (UTM, etc.) are generally well-handled by Google, especially if properly configured in Search Console. The real danger lies in parameters that modify content display or sorting.
Practical impact and recommendations
- Audit current URL parameters: Extract from Search Console or server logs all URL variations crawled by Google to identify problematic parameters
- Implement canonical tags: All pages with parameters must point to the canonical version without parameters (or with minimal parameters)
- Configure Search Console: Use the URL parameter management tool (if still available) or robots.txt directives to guide Google
- Block infinite combinations: Prevent indexing of URLs with multiple parameters via robots.txt or meta robots noindex
- Use JavaScript for filters: Favor client-side filter management with URL updates via History API rather than classic HTML links
- Clean up internal links: Ensure menus and navigation don't automatically generate URLs with multiple parameters
- Monitor crawl budget: Track in Search Console the number of pages crawled daily and identify parasitic URLs
- Implement clean URLs: For e-commerce, favor URL rewriting to transform filters into clean paths (/category/red-color/) rather than parameters
- Test the impact of modifications: Measure the evolution of crawled and indexed URLs after each optimization
Optimal URL parameter management requires in-depth technical expertise combining web development, server configuration, and a thorough understanding of Google's crawling mechanisms. The stakes are particularly critical for medium and large e-commerce sites where poor configuration can literally block the indexing of thousands of strategic pages. Given this complexity and the associated risks, support from a specialized SEO agency provides a personalized analysis of your architecture, an optimization strategy tailored to your technical constraints, and ongoing monitoring to ensure the sustainability of the improvements made.
💬 Comments (0)
Be the first to comment.