Official statement
What you need to understand
Why do websites copy content from other sites?
Content scraping consists of automatically copying a website's content to republish it elsewhere. This practice, often used by spammers, aims to quickly create websites without any original creation effort.
These actors seek to generate traffic or advertising revenue by exploiting the work of legitimate creators. Scraping is generally massive and not very selective.
What is Google's official position on scraping?
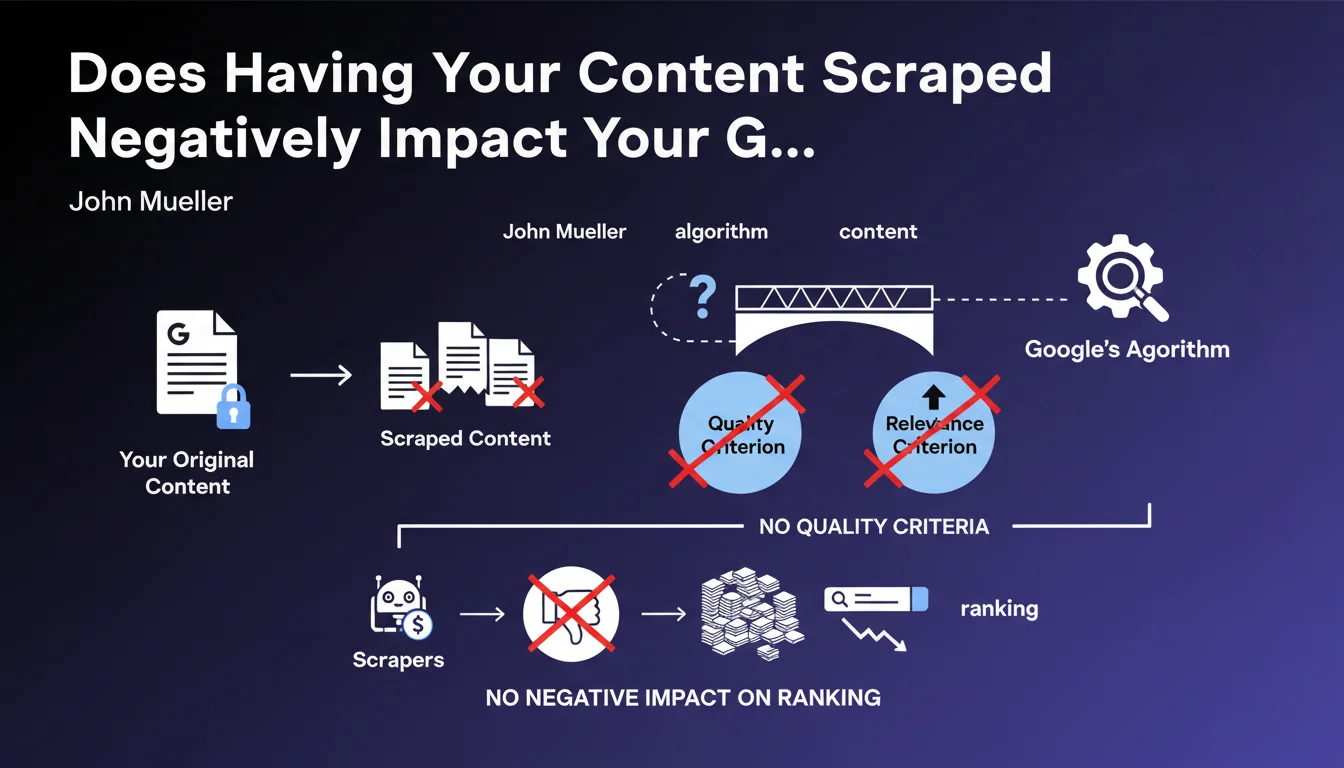
John Mueller clarified that being a victim of scraping is not a quality signal for Google's algorithms. In other words, Google does not consider that content copied elsewhere necessarily indicates its quality.
This position is explained by the fact that scrapers copy massively without any real qualitative selection. They are not reliable indicators of a content's value.
What does this statement actually mean for your website?
If your content is copied by other sites, this does not penalize your rankings. Google does not consider that you lose legitimacy or authority because other sites copy you.
Conversely, Google also does not boost your ranking on the pretext that others are copying you. Scraping is a neutral phenomenon in the evaluation of your site.
- Scraping of your content does not affect your SEO either positively or negatively
- Google does not consider scraping as a quality indicator
- Google's algorithms can generally identify the original source of content
- The fight against duplicate content remains a priority for search engines
SEO Expert opinion
Is this statement consistent with field observations?
Yes, this position indeed corresponds to what we have been observing for years. Sites that are victims of massive scraping generally do not suffer penalties as long as their original content is clearly identifiable.
Google has considerably improved its ability to identify the original source of content through signals such as first indexing date, domain authority, and publication patterns. The algorithms generally do a good job of distinguishing between original and copy.
What important nuances should be added to this statement?
Be careful however: if your own site massively republishes external content or duplicates its own content, you may be considered a scraper. Mueller's statement concerns victims of scraping, not the scrapers themselves.
Furthermore, even if scraping is not a direct SEO signal, it can have indirect negative impacts. Users may come across the copy before the original, creating confusion. Your traffic may be diluted if the copies rank well.
In what cases might this rule not be sufficient?
This statement is reassuring about the absence of direct penalty, but does not solve all problems related to scraping. If a very authoritative site copies your content and enriches it slightly, it can sometimes surpass your positioning thanks to its superior domain power.
Moreover, in very competitive niches or for very similar content between legitimate sites, Google may have difficulty determining the original. Strengthening your authority and authenticity signals therefore remains crucial.
Practical impact and recommendations
What should you do concretely if your content is scraped?
First, don't panic: your rankings are not directly threatened. Monitor your positions and your traffic to verify that the copies are not impacting your performance.
If the scraping is massive and affects your visibility, you can take action by sending DMCA requests (Digital Millennium Copyright Act) to Google to have the copied content removed. Use Google's copyright violation reporting tool.
Also strengthen your authenticity signals: visible publication dates, author mentions, consistent internal links, and regular updates of your content. This helps Google identify your site as the original source.
What mistakes should you avoid when facing the scraping problem?
Do not completely block the crawling of your content for fear of scraping. This would also prevent Google from indexing your pages, which would be far more damaging than scraping itself.
Also avoid duplicating your content yourself across multiple domains or platforms without using appropriate canonical tags. You would then become a creator of duplicate content yourself.
Do not underestimate the importance of indexing speed. The faster your content is indexed by Google after publication, the easier it is for the algorithm to identify you as the original source.
How can you effectively protect and enhance your original content?
Implement a strategy for quick publication and indexing: use the Google Indexing API, submit your new content via Search Console, and maintain an up-to-date XML sitemap.
Develop your domain authority through a qualitative netlinking strategy and a consistent presence in your thematic area. An authoritative site is better recognized as an original source.
- Regularly monitor whether your content is being copied (plagiarism detection tools, Google alerts)
- Make sure your publication dates are clearly visible and structured (Schema.org)
- Properly configure your canonical tags on all your pages
- Quickly index your new content via Search Console
- Develop your E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness)
- Enrich your original content with unique elements (images, data, analyses)
- Create consistent internal links pointing to your original content
- Use DMCA requests only for cases actually impacting your visibility
💬 Comments (0)
Be the first to comment.