Declaration officielle
Ce qu'il faut comprendre
Pourquoi les sites copient-ils le contenu d'autres sites ?
Le scraping de contenu consiste à copier automatiquement le contenu d'un site web pour le republier ailleurs. Cette pratique, souvent utilisée par des spammeurs, vise à créer rapidement des sites sans effort de création original.
Ces acteurs cherchent à générer du trafic ou des revenus publicitaires en exploitant le travail des créateurs légitimes. Le scraping est généralement massif et peu sélectif.
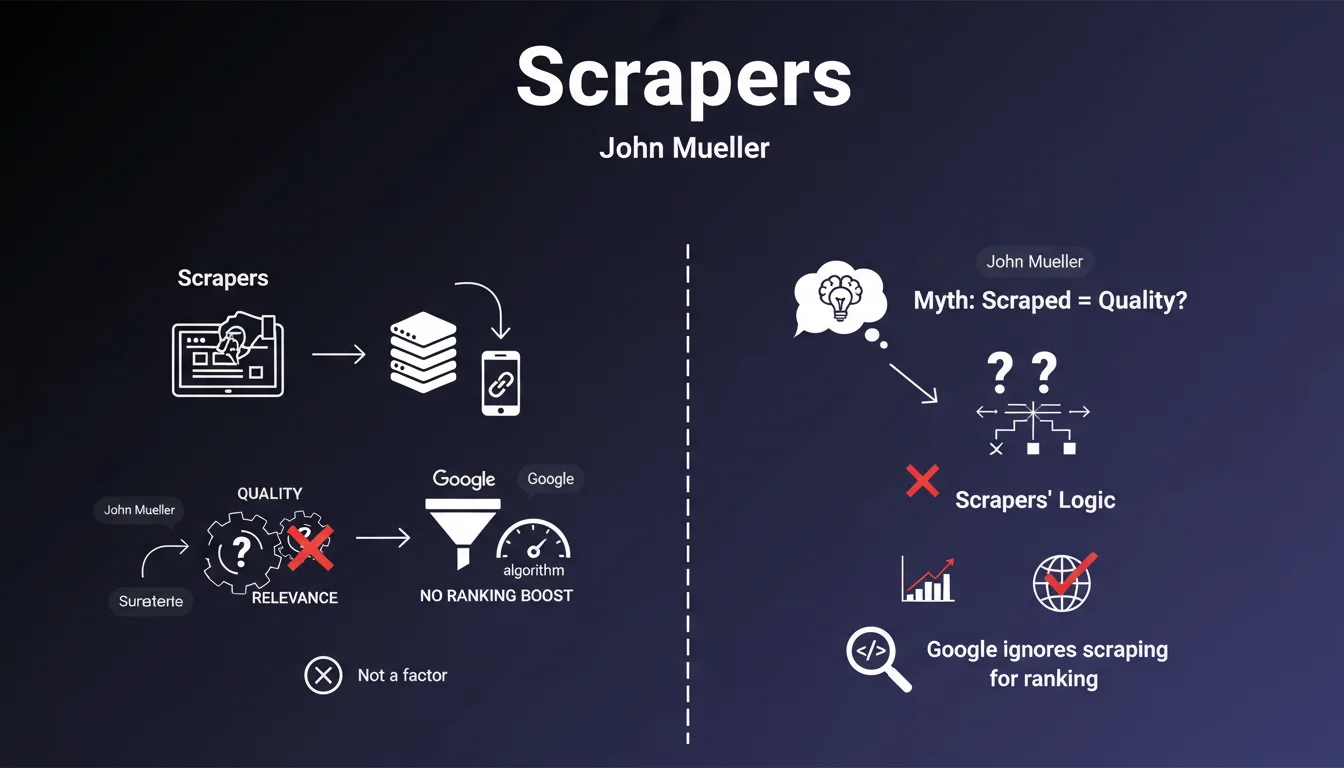
Quelle est la position officielle de Google sur le scraping ?
John Mueller a clarifié que le fait d'être victime de scraping n'est pas un signal de qualité pour les algorithmes de Google. Autrement dit, Google ne considère pas qu'un contenu copié ailleurs indique nécessairement sa qualité.
Cette position s'explique par le fait que les scrapers copient massivement sans réelle sélection qualitative. Ils ne sont pas des indicateurs fiables de la valeur d'un contenu.
Que signifie concrètement cette déclaration pour votre site ?
Si votre contenu est copié par d'autres sites, cela ne pénalise pas votre référencement. Google ne considère pas que vous perdez en légitimité ou en autorité parce que d'autres sites vous copient.
Inversement, Google ne booste pas non plus votre classement sous prétexte que d'autres vous copient. Le scraping est un phénomène neutre dans l'évaluation de votre site.
- Le scraping de votre contenu n'affecte ni positivement ni négativement votre SEO
- Google ne considère pas le scraping comme un indicateur de qualité
- Les algorithmes Google peuvent généralement identifier la source originale du contenu
- La lutte contre le duplicate content reste une priorité pour les moteurs de recherche
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, cette position correspond effectivement à ce que nous observons depuis des années. Les sites victimes de scraping massif ne subissent généralement pas de pénalité tant que leur contenu original est clairement identifiable.
Google a considérablement amélioré sa capacité à identifier la source originale d'un contenu grâce à des signaux comme la date de première indexation, l'autorité du domaine, et les patterns de publication. Les algorithmes font généralement bien la distinction entre original et copie.
Quelles nuances importantes faut-il apporter à cette déclaration ?
Attention toutefois : si votre propre site republie massivement du contenu externe ou duplique son propre contenu, vous pouvez être considéré comme un scraper. La déclaration de Mueller concerne les victimes de scraping, pas les scrapers eux-mêmes.
Par ailleurs, même si le scraping n'est pas un signal SEO direct, il peut avoir des impacts indirects négatifs. Les utilisateurs peuvent tomber sur la copie avant l'original, créant de la confusion. Votre trafic peut être dilué si les copies se positionnent bien.
Dans quels cas cette règle pourrait-elle ne pas suffire ?
Cette déclaration rassure sur l'absence de pénalité directe, mais ne résout pas tous les problèmes liés au scraping. Si un site très autoritaire copie votre contenu et l'enrichit légèrement, il peut parfois surpasser votre positionnement grâce à sa puissance de domaine supérieure.
De plus, dans des niches très compétitives ou pour des contenus très similaires entre sites légitimes, Google peut avoir du mal à déterminer l'original. Renforcer vos signaux d'autorité et d'authenticité reste donc crucial.
Impact pratique et recommandations
Que faut-il faire concrètement si votre contenu est scrapé ?
D'abord, ne paniquez pas : votre référencement n'est pas menacé directement. Surveillez vos positions et votre trafic pour vérifier que les copies n'impactent pas vos performances.
Si le scraping est massif et affecte votre visibilité, vous pouvez agir en envoyant des demandes DMCA (Digital Millennium Copyright Act) à Google pour faire retirer les contenus copiés. Utilisez l'outil de signalement de violation de droits d'auteur de Google.
Renforcez également vos signaux d'authenticité : dates de publication visibles, mentions d'auteur, liens internes cohérents, et mise à jour régulière de vos contenus. Cela aide Google à identifier votre site comme la source originale.
Quelles erreurs éviter face au problème du scraping ?
Ne bloquez pas complètement l'exploration de votre contenu par peur du scraping. Cela empêcherait également Google d'indexer vos pages, ce qui serait bien plus dommageable que le scraping lui-même.
Évitez aussi de dupliquer vous-même votre contenu sur plusieurs domaines ou plateformes sans utiliser les balises canonical appropriées. Vous deviendriez alors vous-même un créateur de contenu dupliqué.
Ne sous-estimez pas l'importance de la vitesse d'indexation. Plus votre contenu est rapidement indexé par Google après publication, plus il est facile pour l'algorithme de vous identifier comme source originale.
Comment protéger et valoriser efficacement votre contenu original ?
Mettez en place une stratégie de publication et d'indexation rapide : utilisez l'API d'indexation Google, soumettez vos nouveaux contenus via la Search Console, et maintenez un sitemap XML à jour.
Développez votre autorité de domaine par une stratégie de netlinking qualitative et une présence cohérente sur votre thématique. Un site autoritaire est mieux reconnu comme source originale.
- Surveillez régulièrement si votre contenu est copié (outils de détection de plagiat, alertes Google)
- Assurez-vous que vos dates de publication sont clairement visibles et structurées (Schema.org)
- Configurez correctement vos balises canonical sur toutes vos pages
- Indexez rapidement vos nouveaux contenus via la Search Console
- Développez votre E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness)
- Enrichissez vos contenus originaux avec des éléments uniques (images, données, analyses)
- Créez des liens internes cohérents pointant vers vos contenus originaux
- Utilisez les demandes DMCA uniquement pour les cas impactant réellement votre visibilité
💬 Commentaires (0)
Soyez le premier à commenter.