Official statement
What you need to understand
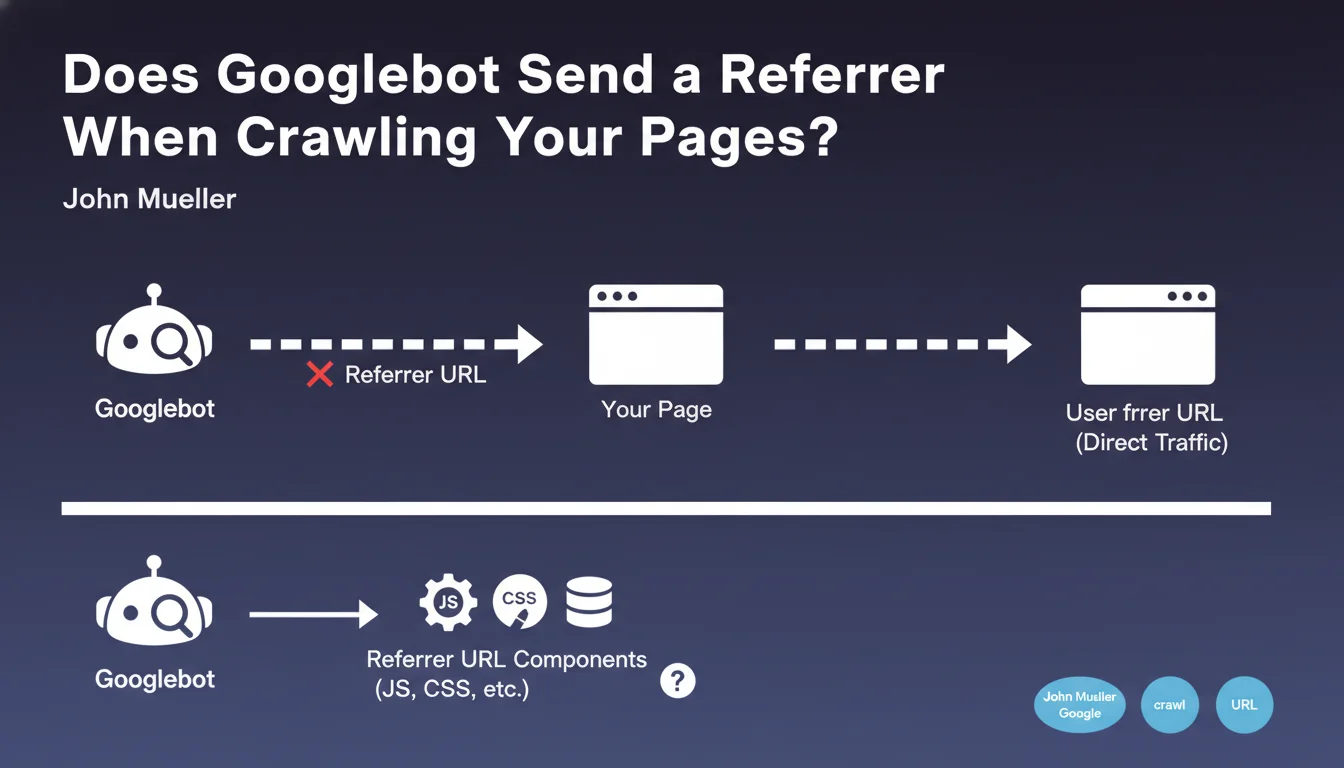
When Googlebot crawls your website, it does not transmit an HTTP referrer URL as a human visitor would when navigating from one page to another. This means that in your server logs or analytics tools, Google bot visits appear as direct traffic, with no identifiable source.
This technical characteristic has concrete implications for your data analysis. Unlike a standard browser that indicates the page from which the visitor came via the HTTP referer header, Googlebot behaves differently depending on the type of resource it downloads.
An important nuance exists nevertheless: for secondary resources such as JavaScript files, CSS or images, Googlebot might transmit a referrer indicating the HTML page that calls them. This distinction theoretically allows tracing the origin of secondary resource requests.
- Googlebot visits are recorded as direct traffic in your analytics
- No referrer is sent when crawling main HTML pages
- A referrer may be present for JS, CSS and image resources
- Identification remains possible via the user-agent and IP address
- This information impacts your server log analysis
SEO Expert opinion
This statement is perfectly consistent with field observations from SEO practitioners who regularly analyze server logs. Indeed, Googlebot's presence is primarily detected via its specific user-agent and Google's IP ranges, never via a standard referrer.
A subtlety deserves attention regarding secondary resources: in practice, we do indeed sometimes observe a referrer for CSS, JS or image files, but this behavior is neither systematic nor guaranteed. It would be risky to build a detection strategy solely on this criterion.
Moreover, this specificity does not change anything about PageRank functioning and value transmission through links. The absence of referrer during crawling does not affect how Google evaluates and follows links on your site.
Practical impact and recommendations
- Identify Googlebot correctly in your logs via the user-agent and reverse DNS verification of Google IPs, not via the referrer
- Configure your analytics tools to differentiate bot traffic from real direct traffic, using user-agents
- Don't block traffic without referrer at the server level, this would prevent Googlebot from accessing your pages
- Analyze your server logs regularly to understand crawl patterns, even without referrer data
- Use Search Console as a complementary source to identify which pages point to others in your crawl
- Verify that your JS/CSS resources are accessible to Googlebot without referrer-based restrictions
- Document this specificity with your technical teams to avoid accidental blocking
Fine-grained analysis of crawl behaviors and optimal technical infrastructure configuration require sharp expertise combining SEO, web development and system administration. These optimizations become particularly complex on large-scale sites with sophisticated technical architectures. Engaging a specialized SEO agency can prove judicious to benefit from personalized support, in-depth technical audits and recommendations tailored to your specific context, thus ensuring implementation that complies with best practices.
💬 Comments (0)
Be the first to comment.