Declaration officielle
Ce qu'il faut comprendre
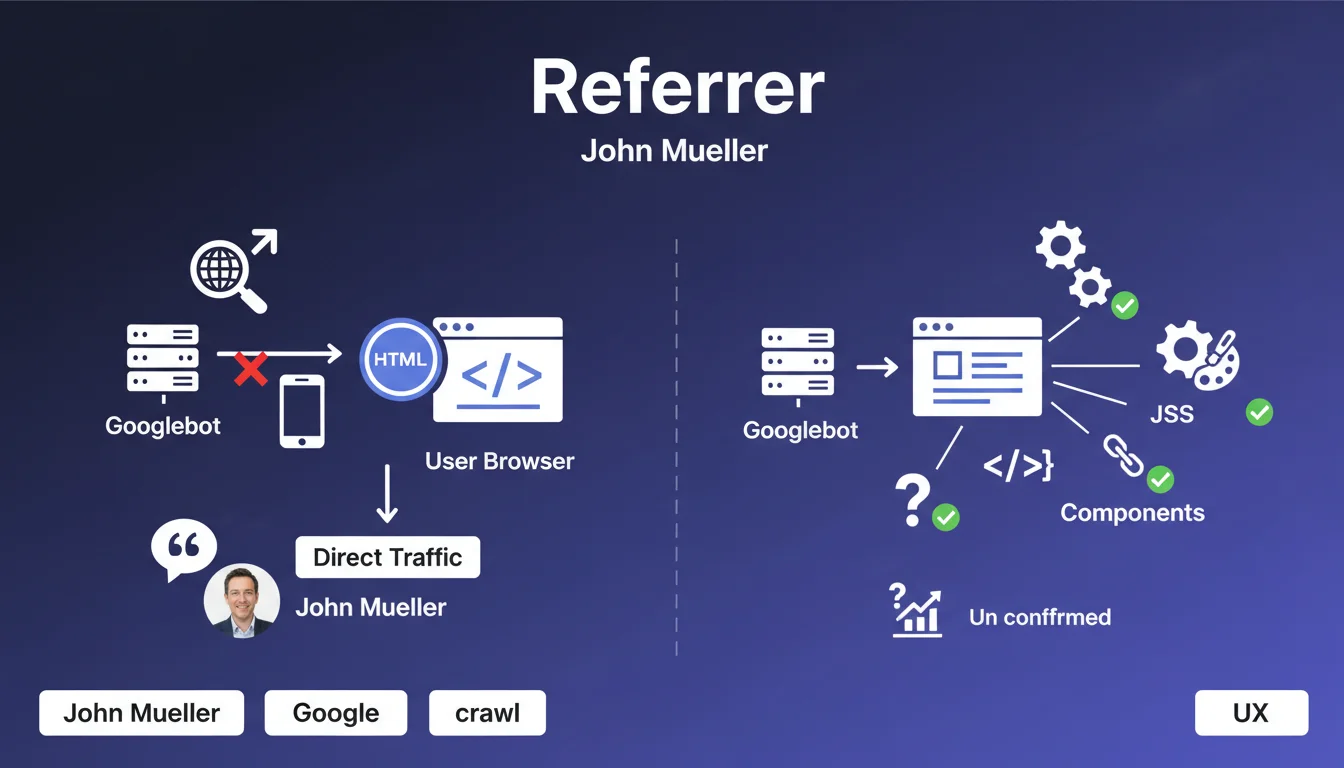
Lorsque Googlebot explore votre site web, il ne transmet pas d'URL referrer HTTP comme le ferait un visiteur humain naviguant d'une page à l'autre. Cela signifie que dans vos logs serveur ou outils analytics, les visites du robot Google apparaissent comme du trafic direct, sans provenance identifiable.
Cette particularité technique a des implications concrètes pour l'analyse de vos données. Contrairement à un navigateur classique qui indique la page d'où provient le visiteur via l'en-tête HTTP referer, Googlebot se comporte différemment selon le type de ressource qu'il télécharge.
Une nuance importante existe néanmoins : pour les ressources annexes comme les fichiers JavaScript, CSS ou images, Googlebot pourrait transmettre un referrer indiquant la page HTML qui les appelle. Cette distinction permet théoriquement de tracer l'origine des demandes de ressources secondaires.
- Les visites Googlebot s'enregistrent comme du trafic direct dans vos analytics
- Aucun referrer n'est envoyé lors du crawl des pages HTML principales
- Un referrer peut être présent pour les ressources JS, CSS et images
- L'identification reste possible via le user-agent et l'adresse IP
- Cette information impacte l'analyse de vos logs serveur
Avis d'un expert SEO
Cette déclaration est parfaitement cohérente avec les observations terrain des praticiens SEO qui analysent régulièrement les logs serveur. En effet, la présence de Googlebot se détecte principalement via son user-agent spécifique et les plages d'IP de Google, jamais via un referrer classique.
Une subtilité mérite attention concernant les ressources secondaires : dans la pratique, on observe effectivement parfois un referrer pour les fichiers CSS, JS ou images, mais ce comportement n'est pas systématique ni garanti. Il serait risqué de bâtir une stratégie de détection uniquement sur ce critère.
Par ailleurs, cette spécificité ne change rien au fonctionnement du PageRank et de la transmission de valeur via les liens. L'absence de referrer lors du crawl n'affecte pas la manière dont Google évalue et suit les liens de votre site.
Impact pratique et recommandations
- Identifiez Googlebot correctement dans vos logs via le user-agent et la vérification DNS inverse des IP Google, pas via le referrer
- Configurez vos outils analytics pour différencier le trafic bot du trafic direct réel, en utilisant les user-agents
- Ne bloquez pas le trafic sans referrer au niveau serveur, cela empêcherait Googlebot d'accéder à vos pages
- Analysez vos logs serveur régulièrement pour comprendre les patterns de crawl, même sans données de referrer
- Utilisez Search Console comme source complémentaire pour identifier quelles pages pointent vers d'autres dans votre crawl
- Vérifiez que vos ressources JS/CSS sont accessibles à Googlebot sans restriction basée sur le referrer
- Documentez cette spécificité auprès de vos équipes techniques pour éviter des blocages accidentels
L'analyse fine des comportements de crawl et la configuration optimale de l'infrastructure technique nécessitent une expertise pointue combinant SEO, développement web et administration système. Ces optimisations deviennent particulièrement complexes sur des sites de grande envergure avec des architectures techniques sophistiquées. Faire appel à une agence SEO spécialisée peut s'avérer judicieux pour bénéficier d'un accompagnement personnalisé, d'audits techniques approfondis et de recommandations adaptées à votre contexte spécifique, garantissant ainsi une mise en œuvre conforme aux meilleures pratiques.
💬 Commentaires (0)
Soyez le premier à commenter.