Official statement
What you need to understand
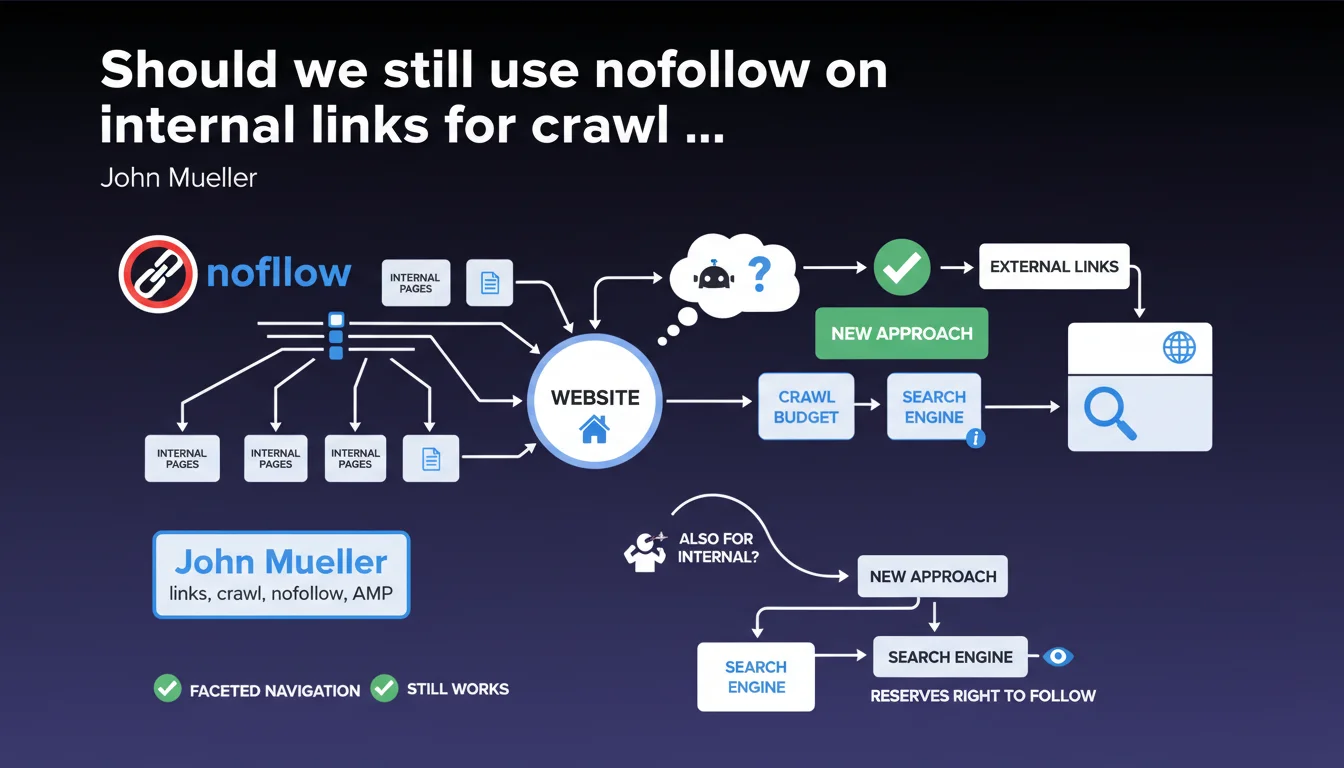
Google has made a major change to how the nofollow attribute works by shifting it from a strict directive to a simple hint that the search engine can choose to follow or ignore. Although this evolution was primarily designed for external links, it also applies to internal links, which raises important questions for crawl budget management.
Traditionally, SEOs extensively used nofollow on internal links to control PageRank flow and optimize crawling, particularly in cases of faceted navigation (product filters generating thousands of URLs), complex pagination, or low SEO-value pages. This practice allowed for precise guidance of Googlebot toward priority pages.
With this new approach, Google now reserves the right to follow these internal nofollow links if it deems it relevant, introducing a form of uncertainty into crawl strategy. The search engine claims this shouldn't change much in practice, but this loss of absolute control represents an important philosophical shift.
- Internal nofollow becomes a hint, not an absolute directive
- Google can decide to crawl pages marked nofollow if deemed relevant
- Impact should be limited on existing faceted navigation
- Loss of total control over crawl budget distribution
- Introduction of a random element in technical optimization
SEO Expert opinion
This evolution reveals Google's clear intention to regain control over crawl decisions and limit SEOs' ability to manipulate internal PageRank flow too precisely. In practice, my observations on complex sites show that Google still largely respects internal nofollow, but with notable exceptions on high-authority sites where the search engine takes more liberties.
The underlying message is quite clear: Google wants webmasters to focus on site architecture and content quality rather than overly aggressive technical optimizations. The introduced ambiguity seems intentional to discourage over-optimization strategies. However, this poses a real problem for e-commerce sites with millions of dynamically generated pages, where precise crawl control remains crucial.
Practical impact and recommendations
- Maintain nofollow on faceted navigation: this remains effective in the vast majority of cases despite theoretical uncertainty
- Complement with robots.txt: for truly useless sections (session parameters, test pages), use a firm exclusion via robots.txt rather than relying solely on nofollow
- Analyze server logs regularly: verify that Google isn't massively crawling low-value nofollow pages, a sign that it's ignoring your indications
- Favor silo architecture: create a natural link structure where important pages are easily accessible, rather than relying on nofollow to correct poor architecture
- Use canonicals strategically: for page variations (filters, sorting), the canonical tag remains a stronger directive than nofollow
- Don't overuse internal nofollow: reserve its use for truly problematic cases (millions of generated URLs, internal spam) rather than applying it systematically
- Monitor crawl budget: use Search Console to verify that strategic pages are being crawled regularly
- Test progressively: on new sites or redesigns, start without excessive nofollow and only add if crawl problems are observed
💬 Comments (0)
Be the first to comment.