Declaration officielle
Ce qu'il faut comprendre
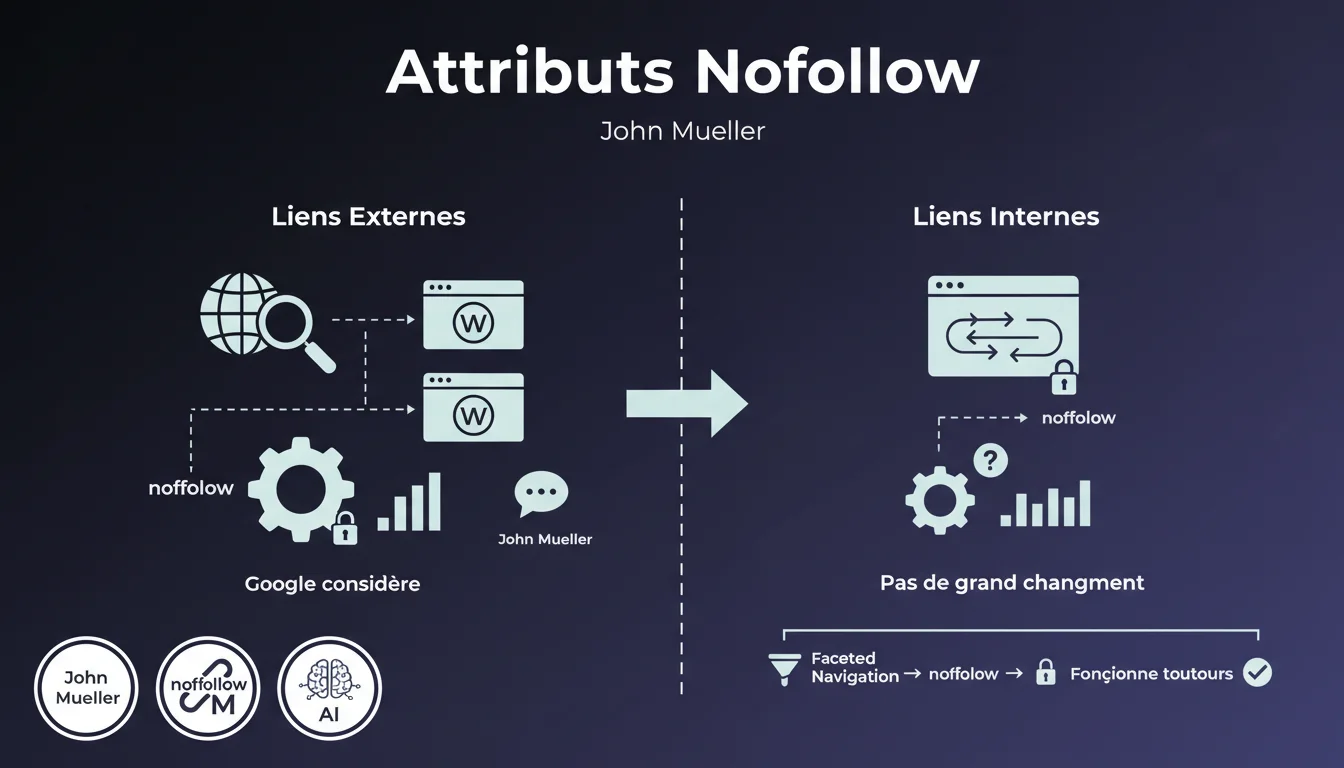
Google a apporté une modification majeure au fonctionnement de l'attribut nofollow en le faisant passer d'une directive stricte à un simple indice que le moteur peut choisir de suivre ou d'ignorer. Bien que cette évolution ait été principalement conçue pour les liens externes, elle s'applique également aux liens internes, ce qui soulève des questions importantes pour la gestion du crawl budget.
Traditionnellement, les SEO utilisaient massivement le nofollow sur les liens internes pour contrôler le flux de PageRank et optimiser le crawl, notamment dans les cas de navigation à facettes (filtres de produits générant des milliers d'URLs), de pagination complexe, ou de pages à faible valeur SEO. Cette pratique permettait de guider précisément Googlebot vers les pages prioritaires.
Avec cette nouvelle approche, Google se réserve désormais le droit de suivre ces liens nofollow internes s'il le juge pertinent, introduisant une forme d'incertitude dans la stratégie de crawl. Le moteur affirme que cela ne devrait pas changer grand-chose en pratique, mais cette perte de contrôle absolu représente un changement philosophique important.
- Le nofollow interne devient un indice, pas une directive absolue
- Google peut décider de crawler des pages marquées nofollow si jugé pertinent
- L'impact devrait être limité sur la navigation à facettes existante
- Perte de contrôle total sur la distribution du crawl budget
- Introduction d'une part d'aléatoire dans l'optimisation technique
Avis d'un expert SEO
Cette évolution révèle une volonté claire de Google de reprendre le contrôle sur les décisions de crawl et de limiter la capacité des SEO à manipuler trop finement le flux de PageRank interne. Dans la pratique, mes observations sur des sites complexes montrent que Google respecte encore largement le nofollow interne, mais avec des exceptions notables sur les sites à forte autorité où le moteur se permet plus de libertés.
Le message sous-jacent est assez clair : Google souhaite que les webmasters se concentrent sur l'architecture du site et la qualité du contenu plutôt que sur des optimisations techniques trop agressives. L'ambiguïté introduite semble intentionnelle pour décourager les stratégies de sur-optimisation. Cependant, cela pose un vrai problème pour les sites e-commerce avec des millions de pages générées dynamiquement, où le contrôle précis du crawl reste crucial.
Impact pratique et recommandations
- Maintenir le nofollow sur la navigation à facettes : cela reste efficace dans la grande majorité des cas malgré l'incertitude théorique
- Compléter avec robots.txt : pour les sections vraiment inutiles (paramètres de session, pages de test), utiliser une exclusion ferme via robots.txt plutôt que compter uniquement sur nofollow
- Analyser les logs serveur régulièrement : vérifier que Google ne crawle pas massivement des pages nofollow à faible valeur, signe qu'il ignore vos indications
- Privilégier l'architecture en silos : créer une structure de liens naturelle où les pages importantes sont facilement accessibles, plutôt que compter sur le nofollow pour corriger une mauvaise architecture
- Utiliser les canoniques stratégiquement : pour les variations de pages (filtres, tris), la balise canonical reste une directive plus forte que le nofollow
- Ne pas abuser du nofollow interne : réserver son usage aux cas vraiment problématiques (millions d'URLs générées, spam interne) plutôt que de l'appliquer systématiquement
- Monitorer le crawl budget : utiliser Search Console pour vérifier que les pages stratégiques sont bien crawlées régulièrement
- Tester progressivement : sur les nouveaux sites ou refonte, commencer sans nofollow excessif et n'ajouter que si problèmes de crawl constatés
💬 Commentaires (0)
Soyez le premier à commenter.