Declaration officielle
Ce qu'il faut comprendre
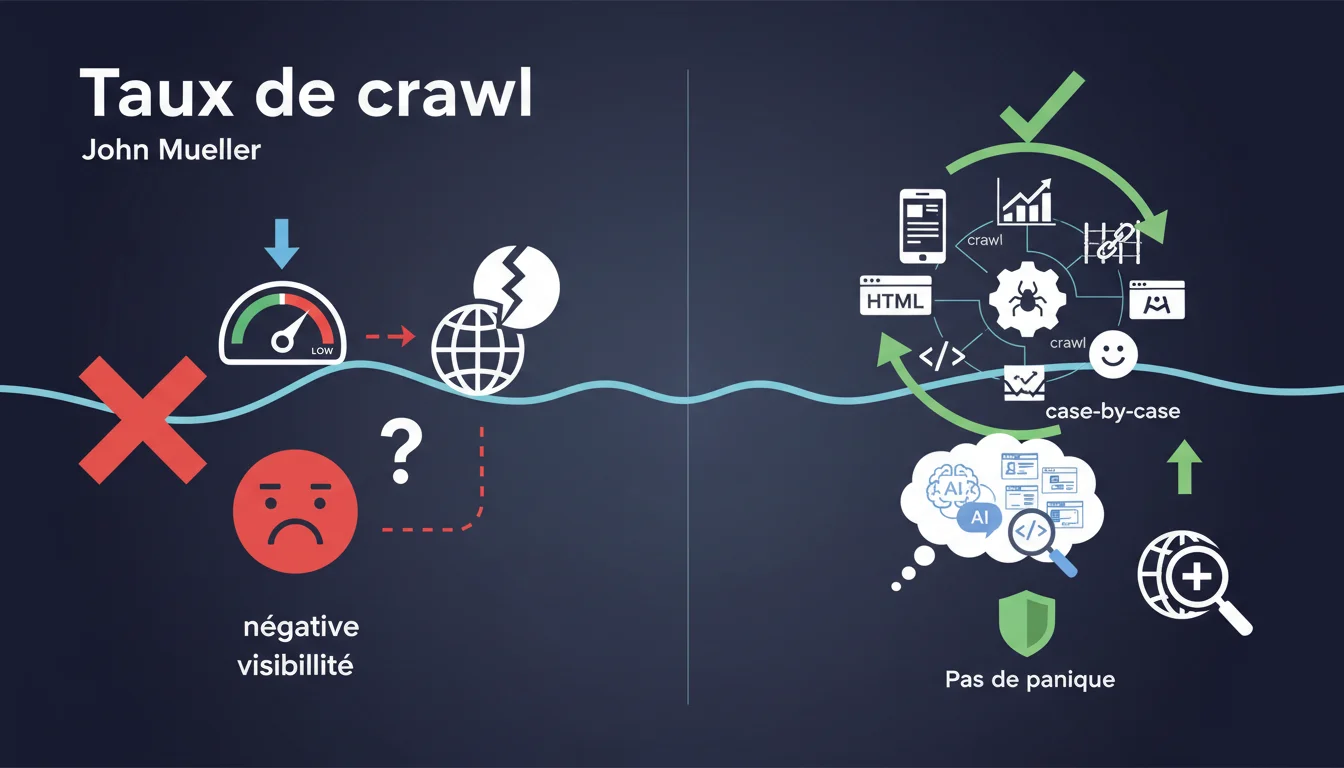
Le taux de crawl (ou crawl rate) représente la fréquence et l'intensité avec lesquelles Googlebot explore les pages de votre site. Dans la Search Console, Google propose un paramètre permettant de limiter ce taux, mais cette fonctionnalité est souvent mal comprise et mal utilisée.
John Mueller souligne que pour les très gros sites, cette modification manuelle n'est pas recommandée. Googlebot utilise des algorithmes sophistiqués pour déterminer automatiquement le rythme d'exploration optimal, en tenant compte de la santé du serveur, de la fraîcheur du contenu et de nombreux autres signaux.
Points essentiels à retenir :
- Googlebot ajuste automatiquement son taux de crawl en fonction des capacités de votre serveur
- Le moteur détecte les ralentissements et s'adapte pour ne pas surcharger votre infrastructure
- Limiter manuellement le crawl peut ralentir l'indexation de nouvelles pages importantes
- Ce paramètre ne sert qu'à limiter le crawl, jamais à l'augmenter
- Google privilégie naturellement les sites avec un contenu de qualité et une architecture technique saine
La recommandation éditoriale va même plus loin en suggérant de ne jamais toucher à ce réglage, quelle que soit la taille du site, sauf cas exceptionnels de problèmes serveur majeurs.
Avis d'un expert SEO
Cette position de Google est totalement cohérente avec les observations terrain. Dans 99% des cas, les sites qui limitent leur taux de crawl le font par méconnaissance ou par peur infondée de surcharge serveur. Or, Googlebot est particulièrement respectueux des ressources serveur : il ralentit automatiquement dès qu'il détecte des temps de réponse dégradés ou des erreurs 5xx.
Il existe toutefois quelques cas légitimes où une limitation temporaire peut se justifier : lors d'une migration technique majeure avec serveurs sous-dimensionnés, pendant une refonte complète avec environnement de production fragile, ou sur des sites e-commerce avec des pics de charge extrêmes pendant des événements commerciaux critiques. Même dans ces situations, il vaut mieux résoudre le problème d'infrastructure que de brider Googlebot.
Impact pratique et recommandations
- À FAIRE : Vérifier la santé technique de votre serveur (temps de réponse, disponibilité) dans la Search Console
- À FAIRE : Optimiser les performances serveur pour supporter naturellement un crawl intensif (cache, CDN, optimisation base de données)
- À FAIRE : Travailler sur votre architecture de liens internes pour guider efficacement Googlebot vers vos pages prioritaires
- À FAIRE : Utiliser le fichier robots.txt et les balises noindex pour éviter le crawl des pages sans valeur SEO (facettes inutiles, pages de recherche interne)
- À FAIRE : Monitorer les statistiques d'exploration dans la Search Console pour détecter d'éventuelles anomalies
- À NE PAS FAIRE : Modifier le taux de crawl dans la Search Console sans raison technique majeure et temporaire
- À NE PAS FAIRE : Croire qu'augmenter artificiellement le crawl améliorera votre référencement (ce paramètre ne permet que de limiter)
- À NE PAS FAIRE : Confondre budget de crawl et taux de crawl : travaillez sur la qualité et la structure plutôt que sur des limitations arbitraires
- CAS PARTICULIER : Si vous devez vraiment limiter temporairement (migration critique), documentez la raison et planifiez la réactivation rapide du mode automatique
💬 Commentaires (0)
Soyez le premier à commenter.