Official statement
Other statements from this video 2 ▾
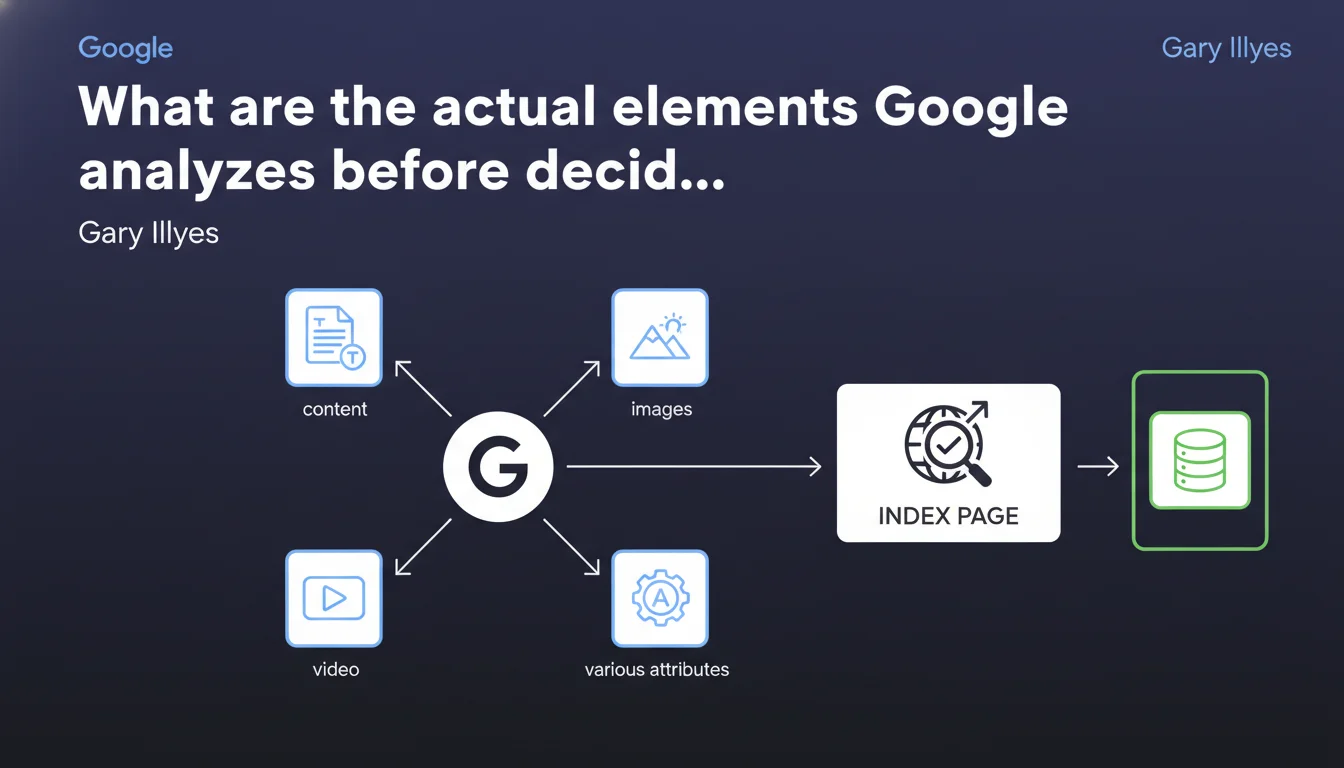
Google parses content tags, images, videos and various attributes to decide whether a page deserves indexing. These elements function as quality and relevance signals. The statement remains deliberately vague about the thresholds and weightings applied.
What you need to understand
Gary Illyes reminds us that parsing precedes the indexation decision. Google doesn't just read plain text — it analyzes a multitude of structural and media elements to assess whether a page is worth storing in the index.
This clarification comes at a time when many sites suffer from chronic indexation problems. Understanding what is analyzed becomes strategic for diagnosing why certain pages remain out of the index.
What exact elements does Google parse during the crawl?
The statement mentions content tags, images, videos and various attributes. Concretely, this encompasses semantic HTML tags (title, meta, headings), structured metadata (Schema.org), image alt attributes, and potential video transcripts.
Google looks for quality and consistency signals. A page with an empty title, images without alt text, no clear semantic structure sends negative signals. Conversely, a page rich in relevant metadata makes the engine's job easier.
Why aren't some pages indexed despite having decent content?
Parsing sometimes reveals structural inconsistencies that hinder indexation. Quality content buried in poorly rendered JavaScript code, missing essential tags, contradictory internal redirects — all reasons Google might give up.
The statement implies that textual content alone isn't enough. If structural signals are weak or absent, Google may judge the page insufficiently trustworthy to allocate indexing resources.
- Parsing evaluates dozens of elements, not just visible text
- Metadata and attributes play a role in the indexation decision
- Structural inconsistencies can block a technically crawlable page
- Google looks for quality and consistency signals before committing to indexation
SEO Expert opinion
Does this statement provide new information?
Honestly, no. That Google parses tags, images, videos and attributes has been documented for years. What's missing here — as often — is the actual weighting of these signals. Do all attributes carry the same weight? Is a missing alt enough to block indexation? [To verify]
The wording remains deliberately vague. "Various attributes" could mean practically anything. A professional expects thresholds, specific use cases, examples — not generalities that state the obvious.
Do we observe these parsing mechanisms in the field?
Yes, technical audits show that pages poor in semantic structure struggle to get indexed, even with decent content. A generic title, images without alt text, no Schema.org — these deficiencies accumulate and tip the decision against indexation.
On the other hand, we also see ultra-optimized pages that remain out of index for crawl budget or perceived duplication reasons. Parsing alone doesn't explain everything. Gary's statement omits that these signals interact with dozens of other factors — domain authority, freshness, thematic relevance.
What nuances should we add to this statement?
Parsing is just a first evaluation step. A page can be technically perfect on the parsing side and still not be indexed if Google deems it redundant, low value-add, or from a low-trust site.
Conversely, technically flawed pages can be indexed if they're heavily cited by authoritative sources. Parsing plays a role, but doesn't dictate the final decision alone — you need to keep Google's cost-benefit balance in mind.
Practical impact and recommendations
What should you prioritize optimizing to facilitate parsing?
Start by auditing the HTML structure of your strategic pages. Make sure each page has a unique title, a descriptive meta description, and logically hierarchized Hn tags. These elements are analyzed first.
Next, verify the alt attributes of images and video metadata. A descriptive alt (not keyword-stuffed) helps Google understand the visual context. For videos, prioritize accessible transcripts and VideoObject Schema tags.
What technical errors block parsing and indexation?
Content generated in client-side JavaScript without SSR or pre-rendering remains problematic. If Googlebot only sees an empty shell during initial parsing, signals are nonexistent — the page starts at a disadvantage.
Redirect chains, intermittent 4xx/5xx errors, contradictory canonical tags create noise. Google parses, detects inconsistencies, and may choose not to index to avoid polluting the index.
How do you verify that your pages send the right signals to parsing?
Use Google Search Console to inspect the URL and observe the HTML rendering as seen by Googlebot. Compare with the browser rendering — any divergence signals a parsing problem.
Supplement with third-party tools like Screaming Frog or Oncrawl to identify pages without titles, without alt text, without Schema.org. Prioritize strategic pages: those generating traffic or conversions must be structurally flawless.
- Audit HTML structure: title, meta, Hn on all strategic pages
- Complete alt attributes for images and video metadata
- Implement relevant Schema.org (Article, Product, FAQ depending on context)
- Verify Googlebot rendering via Search Console to detect discrepancies
- Fix redirect chains and intermittent errors
- Eliminate contradictory or duplicate canonical tags
- Monitor indexation via Search Console and react quickly to anomalies
❓ Frequently Asked Questions
Le contenu textuel suffit-il pour qu'une page soit indexée ?
Les images sans attribut alt bloquent-elles l'indexation ?
Le Schema.org influence-t-il la décision d'indexation ?
Pourquoi des pages techniquement parfaites restent-elles hors index ?
Comment prioriser les optimisations de parsing sur un gros site ?
🎥 From the same video 2
Other SEO insights extracted from this same Google Search Central video · published on 04/04/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.