Official statement
What you need to understand
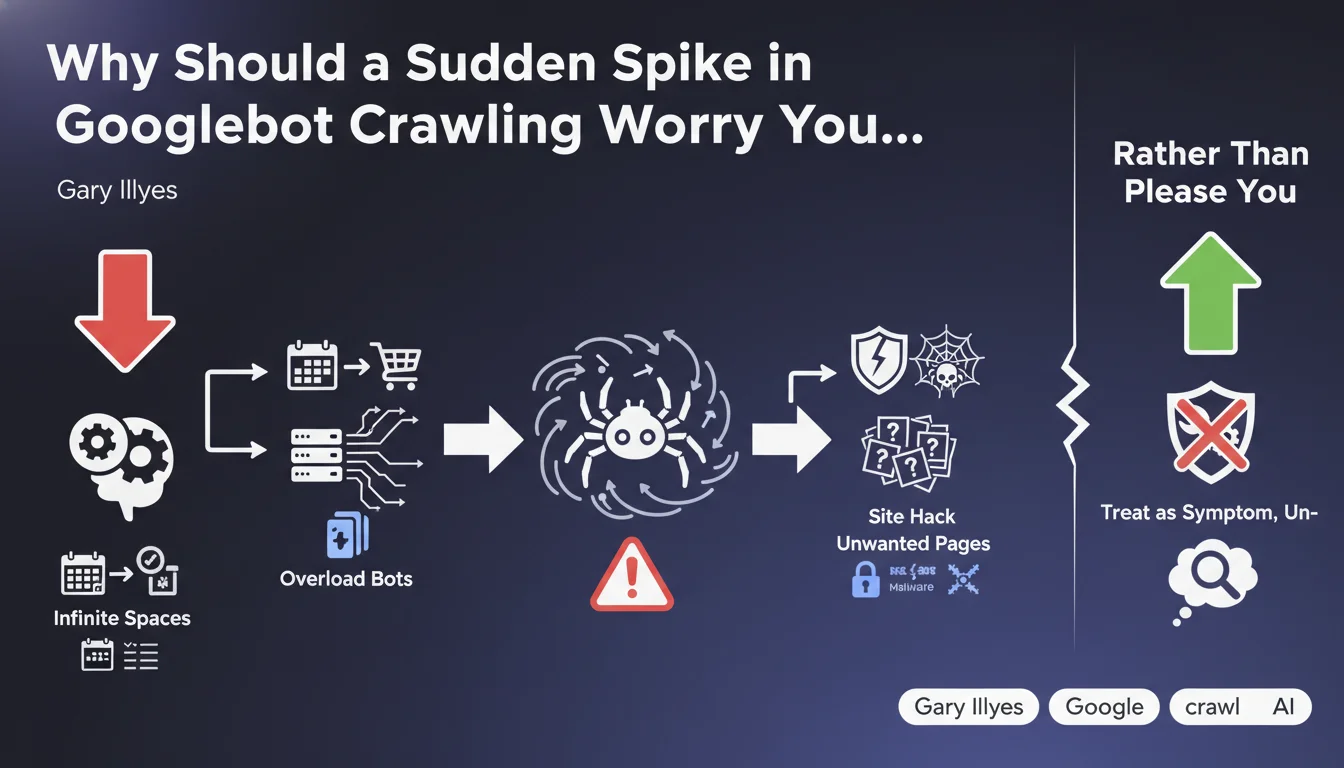
A sudden surge in Googlebot activity on your website is not necessarily a sign of improved visibility. On the contrary, it may reveal major technical issues affecting your crawl budget.
Gary Illyes, Senior Analyst at Google, recently alerted the SEO community to this counter-intuitive phenomenon. Far from being good news, an unexpected crawl spike often signals that Googlebot is trapped in problematic site structures.
This situation can have detrimental consequences: crawl budget waste, indexing of useless pages, and even masking of strategic content that won't be properly crawled.
- Infinite spaces (calendars, product filters, endless pagination) generate millions of useless URLs that Googlebot attempts to crawl
- Site hacking massively creates unwanted pages (spam, malicious redirects) that attract bots
- Crawl budget is limited: the more time Googlebot wastes on worthless pages, the less it crawls your important content
- Vigilance is essential: any crawl spike must be analyzed as a potential symptom before being considered positive
SEO Expert opinion
This statement is perfectly consistent with what we've been observing in the field for years. Infinite spaces remain one of the main causes of crawl budget waste, particularly on e-commerce sites and dynamic content platforms.
However, nuance is needed: a gradual and controlled increase in crawling can indeed be positive, especially after a migration, the addition of quality content, or technical structure improvements. The key lies in the sudden and unexplained nature of the activity spike.
Special cases include news sites where occasional spikes are normal during major events, or seasonal sites where variations are expected. In these contexts, the increase in crawling is justified and predictable.
Practical impact and recommendations
When facing a sudden crawling increase, immediately adopt a methodical investigation approach to identify the cause and protect your crawl budget.
- Analyze your server logs to precisely identify which URLs are being massively crawled by Googlebot
- Check Search Console: review the crawl report to detect anomalies in the types of pages being explored
- Audit your facets and filters: ensure they are properly blocked (robots.txt, noindex, or URL parameters in Search Console)
- Control your pagination: implement rel="next"/"prev" tags or adopt pagination with a fixed limit
- Look for signs of hacking: security scan, verification of indexed pages via "site:" on Google, analysis of suspicious backlinks
- Optimize your robots.txt file: block infinite spaces, calendars, session URLs, and unnecessary parameters
- Use the coverage report to identify crawled but excluded pages, a signal of a structural problem
- Set up alerts on your monitoring tools to be quickly notified of abnormal crawl variations
- Prioritize crawling of your strategic pages via XML sitemap and internal linking structure
💬 Comments (0)
Be the first to comment.