Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Pourquoi Google déconseille-t-il l'utilisation du cache et de l'opérateur site: pour déboguer ?
- □ L'outil d'inspection d'URL est-il vraiment l'arme ultime pour déboguer vos problèmes d'indexation ?
- □ Faut-il vraiment demander une exploration manuelle via l'outil d'inspection d'URL ?
- □ Pourquoi Google indexe-t-il parfois une URL différente de celle que vous attendez ?
- □ Pourquoi vérifier le HTML rendu peut-il révéler des erreurs invisibles dans votre code source ?
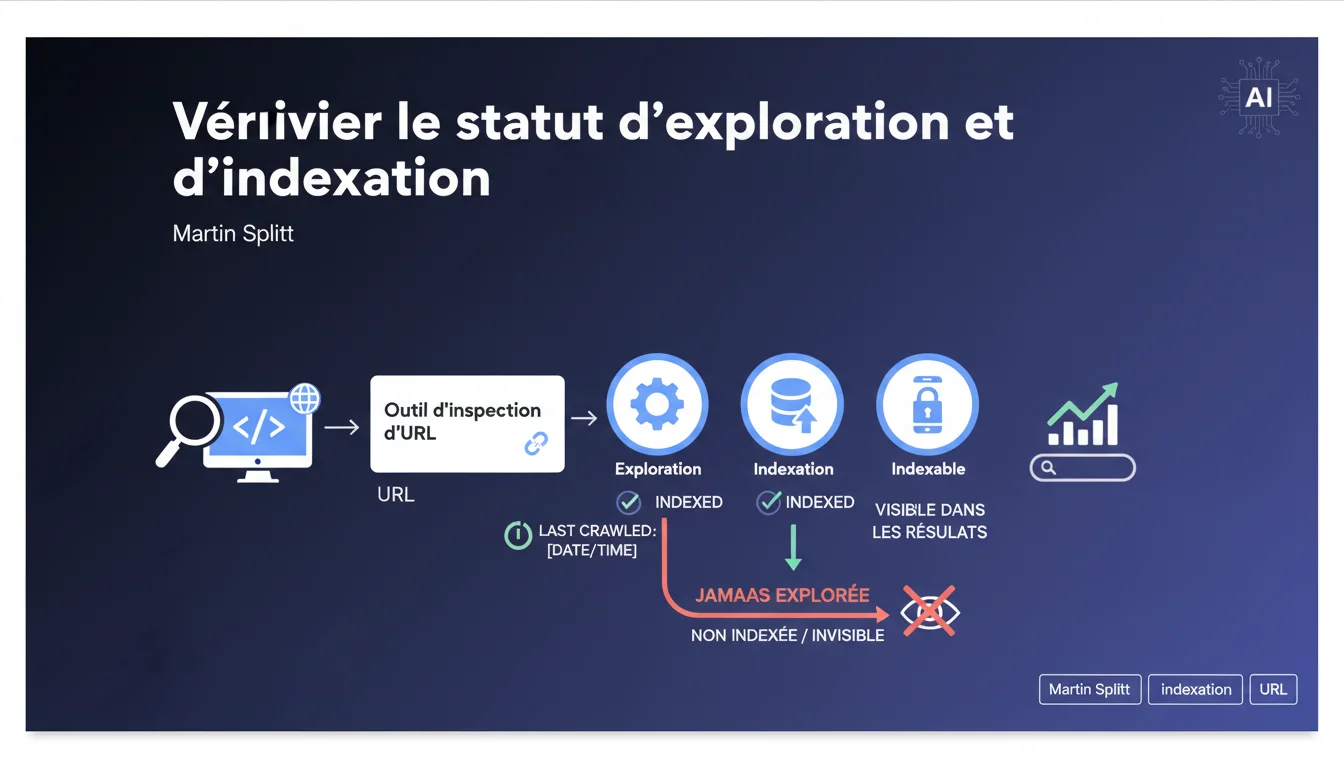
Martin Splitt confirme que l'outil d'inspection d'URL affiche le statut d'exploration et d'indexation d'une page, ainsi que la date du dernier crawl. Si une page n'a jamais été explorée, elle ne sera jamais indexée — et donc invisible dans les SERP. C'est le diagnostic de premier niveau pour identifier les URL orphelines ou bloquées.
Ce qu'il faut comprendre
L'outil d'inspection d'URL de la Google Search Console est le premier réflexe quand une page n'apparaît pas dans les résultats. Il fournit des informations sur l'état d'exploration et d'indexation, la date du dernier passage de Googlebot, et les éventuels obstacles techniques.
Mais cette déclaration de Martin Splitt soulève une question essentielle : est-ce que cet outil reflète toujours la réalité du terrain ? Et surtout, quelles sont ses limites ?
Que montre vraiment l'outil d'inspection d'URL ?
L'outil affiche trois informations clés : si la page a été explorée, si elle est indexée, et quand le dernier crawl a eu lieu. Si le statut indique "URL non explorée", alors aucune indexation n'est possible — la page n'existe tout simplement pas pour Google.
Le problème, c'est que l'outil ne vous dit pas pourquoi la page n'a pas été crawlée. Robots.txt bloquant ? Budget de crawl insuffisant ? Page orpheline sans aucun lien interne ? Vous devez creuser ailleurs.
Pourquoi une page peut-elle rester non explorée ?
Plusieurs scénarios expliquent qu'une page ne soit jamais visitée par Googlebot. Le plus évident : elle n'est liée nulle part — ni dans le maillage interne, ni dans le sitemap XML. Pas de lien = pas de crawl.
Autre cas fréquent : le fichier robots.txt bloque l'accès. Ou alors la page est bien crawlée, mais un tag noindex empêche son indexation — et l'outil d'inspection le signale clairement. Mais attention, l'outil ne détecte pas toujours les problèmes de budget de crawl sur les gros sites.
Faut-il se fier aveuglément à cet outil ?
Non. L'outil d'inspection d'URL est précieux, mais il a ses limites. Il ne remplace pas une analyse de logs pour comprendre le comportement réel de Googlebot. Parfois, l'outil indique "URL non indexée" alors que la page apparaît bien dans les SERP via une recherche site:.
C'est souvent lié à un décalage temporel entre l'index live et les données affichées dans la Search Console. Ou à des signaux contradictoires — la page est indexée mais jugée non pertinente pour la requête testée.
- L'outil montre si une page a été explorée et indexée, mais pas pourquoi elle ne l'est pas
- Une page jamais crawlée ne sera jamais indexée — logique implacable
- Les blocages par robots.txt ou noindex sont détectés, mais pas les problèmes de budget de crawl
- L'outil peut afficher des informations en décalage avec l'index live
Avis d'un expert SEO
Cette déclaration est-elle vraiment utile pour un SEO praticien ?
Soyons honnêtes : ce que dit Martin Splitt est une évidence. Si une page n'est jamais explorée, elle ne sera jamais indexée. Aucune surprise. Ce qui manque ici, c'est une explication des raisons pour lesquelles une page reste non explorée.
En pratique, l'outil d'inspection d'URL est un point de départ — pas une solution complète. Il vous alerte, mais il ne diagnostique pas. Pour aller plus loin, il faut croiser avec les logs serveur, vérifier le maillage interne, analyser le sitemap XML et le fichier robots.txt. [A vérifier] : l'outil ne détecte pas toujours les pages crawlées mais exclues pour cause de contenu dupliqué ou de qualité insuffisante.
Quelles nuances faut-il apporter ?
Premier point : une page peut être crawlée sans être indexée. C'est même fréquent sur les sites e-commerce avec des milliers de fiches produit similaires. Google explore, évalue, et décide de ne pas indexer — sans que l'outil d'inspection ne vous explique vraiment pourquoi.
Deuxième nuance : l'outil affiche parfois "URL non indexée" alors qu'une recherche site:exemple.com/page renvoie bien la page. Ce décalage peut durer plusieurs jours. Ne paniquez pas immédiatement — vérifiez d'abord l'index live avec une requête manuelle.
Dans quels cas cet outil ne suffit-il pas ?
Sur un gros site avec des dizaines de milliers de pages, l'outil d'inspection d'URL devient insuffisant. Vous ne pouvez pas tester manuellement chaque URL. C'est là que l'analyse de logs prend tout son sens : elle vous montre quelles pages sont réellement crawlées, à quelle fréquence, et avec quel budget.
Autre limite : l'outil ne détecte pas les problèmes de crawl budget. Si Googlebot ne passe que toutes les trois semaines sur une section entière de votre site, l'outil ne vous le dira pas. Il faudra analyser les logs pour comprendre que le problème n'est pas un blocage technique, mais un manque de priorité attribuée par Google.
Impact pratique et recommandations
Que faut-il faire concrètement pour diagnostiquer une page non indexée ?
Première étape : vérifiez avec l'outil d'inspection d'URL si la page a bien été explorée. Si le statut est "URL non explorée", cherchez pourquoi. Vérifiez le fichier robots.txt — un simple Disallow: mal placé bloque tout.
Ensuite, contrôlez le maillage interne. Une page orpheline, sans aucun lien entrant depuis le site, ne sera jamais découverte par Googlebot. Ajoutez des liens contextuels depuis des pages déjà crawlées, ou intégrez l'URL dans le sitemap XML.
Si la page est bien explorée mais pas indexée, cherchez un tag noindex dans le code HTML ou dans les en-têtes HTTP. L'outil d'inspection le signale explicitement. Autre piste : le contenu dupliqué. Google a peut-être crawlé la page mais décidé de ne pas l'indexer parce qu'elle ressemble trop à une autre.
Quelles erreurs éviter avec l'outil d'inspection d'URL ?
Erreur classique : demander une indexation via l'outil sans avoir corrigé le problème sous-jacent. Si la page est bloquée par robots.txt ou marquée noindex, demander une réindexation ne sert à rien. Corrigez d'abord, indexez ensuite.
Autre piège : se fier uniquement à cet outil pour évaluer l'état de l'indexation d'un gros site. Sur 50 000 URLs, vous ne pouvez pas tout tester manuellement. Utilisez l'API Google Search Console pour extraire les données en masse, ou croisez avec les logs serveur.
Comment vérifier que mon site est correctement exploré et indexé ?
Au-delà de l'outil d'inspection, analysez régulièrement les rapports de couverture dans la Search Console. Ils vous montrent combien de pages sont indexées, exclues, ou en erreur — avec les raisons précises. Croisez ces données avec vos logs serveur pour identifier les URLs crawlées mais non indexées.
Mettez en place un monitoring automatisé : alertes sur les chutes brutales de pages indexées, suivi du crawl budget, vérification mensuelle du sitemap XML. Ces routines permettent de détecter les problèmes avant qu'ils n'impactent le trafic organique.
- Vérifier le statut d'exploration avec l'outil d'inspection d'URL
- Contrôler le fichier robots.txt et les balises noindex
- S'assurer que la page reçoit des liens internes ou est présente dans le sitemap
- Analyser les rapports de couverture pour détecter les erreurs à grande échelle
- Croiser avec les logs serveur pour comprendre le comportement réel de Googlebot
- Automatiser la surveillance de l'indexation et du crawl budget
❓ Questions frequentes
Pourquoi l'outil d'inspection d'URL affiche-t-il parfois des informations différentes de l'index live ?
Une page peut-elle être crawlée sans être indexée ?
Faut-il utiliser l'outil d'inspection pour forcer l'indexation d'une nouvelle page ?
L'outil d'inspection détecte-t-il les problèmes de crawl budget ?
Que faire si l'outil indique "URL non explorée" alors que la page est accessible ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.