Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ La méthode de production du contenu importe-t-elle vraiment pour Google ?
- □ Le système de contenu utile de Google peut-il vraiment distinguer l'intention éditoriale ?
- □ Faut-il vraiment lire les guidelines Google pour comprendre leurs critères de qualité ?
- □ Comment Google Extended permet-il de bloquer l'indexation pour Bard et Vertex AI ?
- □ Le robots.txt est-il vraiment respecté par tous les crawlers ?
- □ Les robots meta tags permettent-ils vraiment un contrôle précis de l'indexation ?
- □ Les CMS intègrent-ils vraiment les nouvelles options SEO aussi rapidement que Google le prétend ?
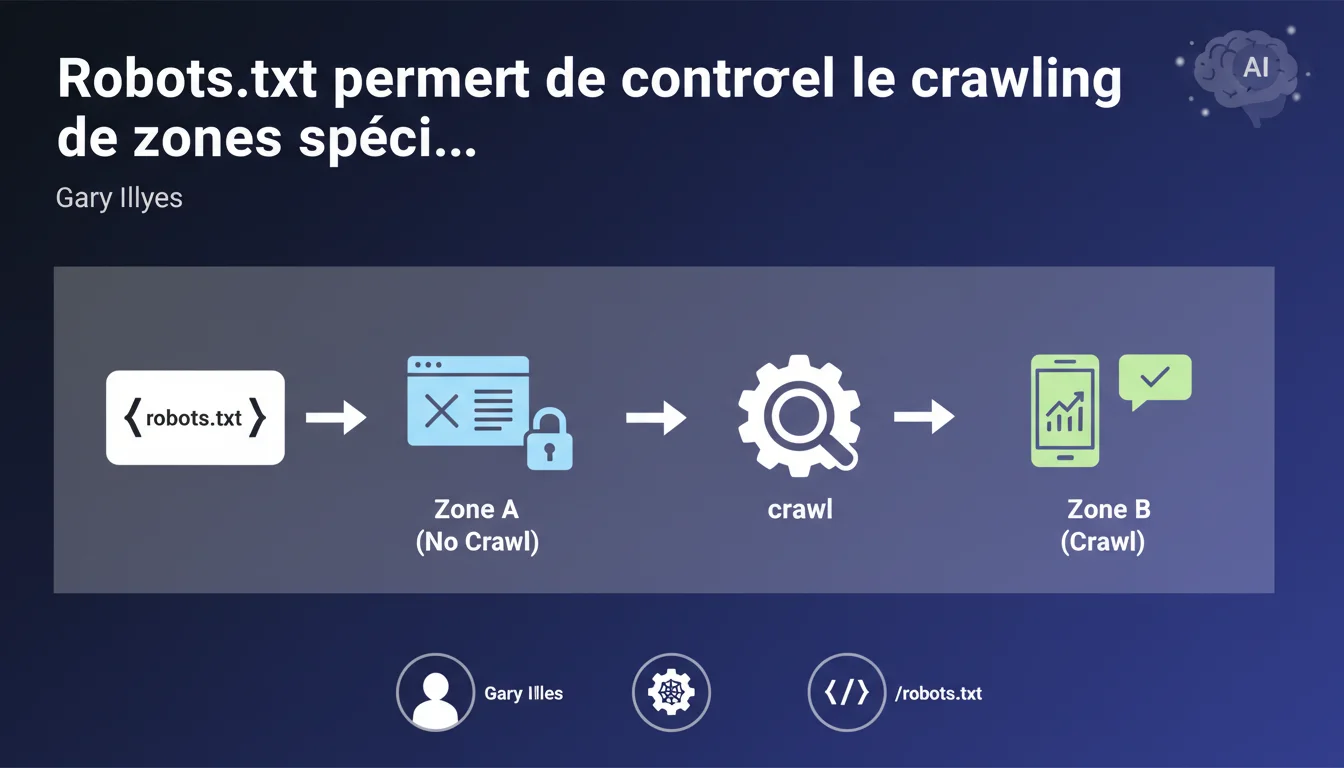
Google confirme que le robots.txt permet de contrôler le crawl de zones précises d'un site. Cette déclaration officielle pose toutefois la question de la différence entre bloquer le crawl et empêcher l'indexation — deux notions que trop de professionnels confondent encore. Le robots.txt reste l'outil de base pour gérer le budget crawl, mais son utilisation exige de la rigueur.
Ce qu'il faut comprendre
Quelle est la fonction première du robots.txt selon Google ?
Le fichier robots.txt sert avant tout à définir des règles de crawl pour les robots des moteurs de recherche. Concrètement, il indique aux crawlers quelles zones du site ils peuvent explorer et lesquelles leur sont interdites.
Cette déclaration de Gary Illyes rappelle un fondamental : vous pouvez utiliser ce fichier pour bloquer le passage des bots sur des répertoires entiers, des types de fichiers spécifiques ou des URL paramétrées. L'objectif ? Économiser le budget crawl et éviter que Googlebot ne perde du temps sur des pages inutiles.
Que signifie "contrôle du traitement" dans ce contexte ?
L'expression "traitement de zones spécifiques" mérite d'être clarifiée. Elle suggère que le robots.txt influence non seulement le crawl, mais aussi la manière dont Google traite certaines ressources.
En pratique, cela peut concerner des fichiers CSS, JavaScript ou des images que vous ne souhaitez pas voir explorés massivement. Bloquer le crawl de ces ressources via robots.txt peut avoir des conséquences sur le rendu de la page — Google l'a rappelé à plusieurs reprises. Donc oui, vous contrôlez, mais attention aux effets de bord.
Quelles sont les limites de ce contrôle ?
Le robots.txt n'empêche pas l'indexation. Une URL bloquée dans le fichier peut quand même apparaître dans les résultats de recherche si Google la découvre via des liens externes. Elle s'affichera simplement sans description, avec la mention "Aucune information disponible".
C'est une confusion classique : bloquer le crawl ne signifie pas supprimer une page de l'index. Pour cela, il faut utiliser une balise meta robots noindex ou un en-tête HTTP X-Robots-Tag. Le robots.txt est un outil de gestion du crawl, pas de désindexation.
- Le robots.txt bloque le crawl, pas l'indexation
- Une URL bloquée peut quand même figurer dans les SERP si elle reçoit des backlinks
- Pour désindexer, utilisez noindex ou X-Robots-Tag
- Le fichier est consulté avant chaque requête de crawl par Googlebot
- Il fonctionne par répertoire, pattern ou règle globale (Allow / Disallow)
Avis d'un expert SEO
Cette déclaration est-elle alignée avec les pratiques terrain observées ?
Oui, globalement. La mécanique du robots.txt est bien documentée et son comportement correspond à ce que Google annonce officiellement. Les praticiens SEO expérimentés savent qu'un Disallow bien placé peut soulager un site de milliers de requêtes inutiles.
Là où ça coince, c'est sur les nuances. Par exemple, Google ne garantit pas que tous les bots respectent le robots.txt — certains crawlers malveillants l'ignorent. De plus, le délai de mise à jour du fichier peut atteindre 24 heures, ce qui signifie qu'un changement urgent ne prend pas effet instantanément. [A vérifier] : Google n'a jamais communiqué de chiffre officiel sur la fréquence exacte de re-crawl du robots.txt selon le PageRank ou l'autorité du domaine.
Dans quels cas cette règle ne s'applique-t-elle pas pleinement ?
Premier cas : les ressources critiques. Si vous bloquez des CSS ou JavaScript essentiels au rendu, Google peut avoir du mal à comprendre votre page. Résultat ? Mauvaise interprétation du contenu, voire non-indexation par manque de lisibilité.
Deuxième cas : les URLs déjà indexées. Si une page est dans l'index et que vous la bloquez ensuite dans le robots.txt, Googlebot ne pourra plus la crawler pour vérifier si elle contient une directive noindex. Vous la figez dans l'index. C'est contre-intuitif mais documenté.
Quelle est la limite pratique du robots.txt face aux budgets crawl serrés ?
Sur un gros site e-commerce ou un média avec des centaines de milliers de pages, le robots.txt reste un levier essentiel. Mais il ne fait pas de miracle. Si votre architecture génère du contenu dupliqué, des facettes infinies ou des paramètres URL non canonisés, le fichier devient vite ingérable.
Dans ces cas-là, il faut combiner robots.txt avec canonicalisation, paramétrage dans la Search Console, et parfois même du JavaScript pour bloquer dynamiquement certains crawlers. Soyons honnêtes : le robots.txt seul ne résout pas un problème de structure de site mal pensée.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser son robots.txt ?
Première étape : auditer ce qui est actuellement bloqué. Trop de sites ont des règles obsolètes ou contradictoires héritées de migrations successives. Vérifiez via la Search Console (outil "Testeur de robots.txt") que vous ne bloquez pas par erreur des sections importantes.
Ensuite, identifiez les zones à faible valeur SEO : répertoires de recherche interne (/search?), paramètres de session (?sessionid=), versions imprimables (/print/). Ce sont des candidats parfaits pour un Disallow. L'objectif est de concentrer le budget crawl sur les pages qui génèrent du trafic ou de la conversion.
Quelles erreurs éviter absolument ?
Erreur classique numéro un : bloquer des ressources critiques (CSS, JS, polices) en pensant économiser du crawl. Résultat : Google ne peut plus rendre la page correctement et peut la juger mobile-unfriendly ou mal structurée.
Erreur numéro deux : confondre robots.txt et noindex. Si vous voulez supprimer une page de l'index, ne la bloquez surtout pas dans le robots.txt — laissez Google la crawler pour qu'il voie la directive noindex.
Erreur numéro trois : oublier le Sitemap en fin de fichier. Préciser l'emplacement de votre sitemap XML dans le robots.txt accélère la découverte de nouvelles URLs.
Comment vérifier que votre configuration est correcte ?
Utilisez systématiquement l'outil de test de la Google Search Console. Il simule le comportement de Googlebot et vous alerte en cas de règle bloquante problématique.
Comparez ensuite avec vos logs serveur. Si Googlebot continue de heurter des URLs que vous pensiez avoir bloquées, c'est que votre syntaxe est incorrecte ou que des règles Allow/Disallow se contredisent. Le diable est dans les détails : un espace mal placé ou un wildcard (*) oublié peut ruiner toute la logique.
- Auditer le robots.txt existant et supprimer les règles obsolètes
- Bloquer uniquement les zones sans valeur SEO (recherche interne, paramètres de session)
- Ne jamais bloquer CSS, JS ou polices critiques au rendu
- Laisser les pages avec noindex accessibles au crawl
- Indiquer l'emplacement du sitemap XML dans le fichier
- Tester systématiquement via la Search Console avant déploiement
- Monitorer les logs serveur pour valider que les règles s'appliquent
Le robots.txt reste un outil fondamental pour gérer le budget crawl et protéger des zones sensibles ou inutiles de votre site. Mais son utilisation demande rigueur et compréhension fine des mécaniques de crawl et d'indexation.
Sur des sites complexes — plateformes e-commerce multi-facettes, médias à forte volumétrie, architectures internationales — la configuration optimale du robots.txt nécessite une analyse approfondie et une coordination avec d'autres leviers (canonicalisation, paramètres Search Console, gestion des sitemaps). Ces optimisations techniques peuvent rapidement devenir complexes à orchestrer seul, surtout si votre équipe manque de temps ou d'expertise terrain. Dans ce contexte, faire appel à une agence SEO spécialisée peut s'avérer judicieux pour bénéficier d'un accompagnement personnalisé et éviter des erreurs coûteuses.
❓ Questions frequentes
Le robots.txt empêche-t-il l'indexation d'une page ?
Peut-on bloquer des ressources CSS ou JavaScript dans robots.txt sans risque ?
Combien de temps faut-il pour qu'un changement dans robots.txt soit pris en compte ?
Dois-je indiquer mon sitemap dans le robots.txt ?
Comment vérifier que mes règles robots.txt fonctionnent ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 01/11/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.