Declaration officielle
Autres déclarations de cette vidéo 15 ▾
- □ Les fluctuations de classement sont-elles vraiment normales ou cachent-elles un problème technique ?
- □ Google utilise-t-il vraiment un seul index mondial pour tous les pays ?
- □ Faut-il encore se fier aux résultats de la requête site: pour diagnostiquer l'indexation ?
- □ L'engagement utilisateur influence-t-il réellement le classement Google ?
- □ Pourquoi les pages à fort trafic pèsent-elles plus dans le score Core Web Vitals ?
- □ Google segmente-t-il vraiment les sites par type de template pour évaluer la Page Experience ?
- □ Combien de liens internes faut-il placer par page pour optimiser son SEO ?
- □ Pourquoi la structure en arbre de votre maillage interne compte-t-elle vraiment pour Google ?
- □ La distance depuis la homepage influence-t-elle vraiment la vitesse d'indexation ?
- □ Pourquoi la structure d'URL n'a-t-elle aucune importance pour Google ?
- □ Pourquoi les positions Search Console ne reflètent-elles pas la réalité du classement ?
- □ Google distingue-t-il vraiment 'edit video' et 'video editor' comme des intentions différentes ?
- □ Le balisage FAQ doit-il obligatoirement figurer sur la page indexée pour générer un rich snippet ?
- □ Les liens en footer ont-ils la même valeur SEO que les liens dans le contenu ?
- □ L'indexation mobile-first a-t-elle un impact sur vos classements Google ?
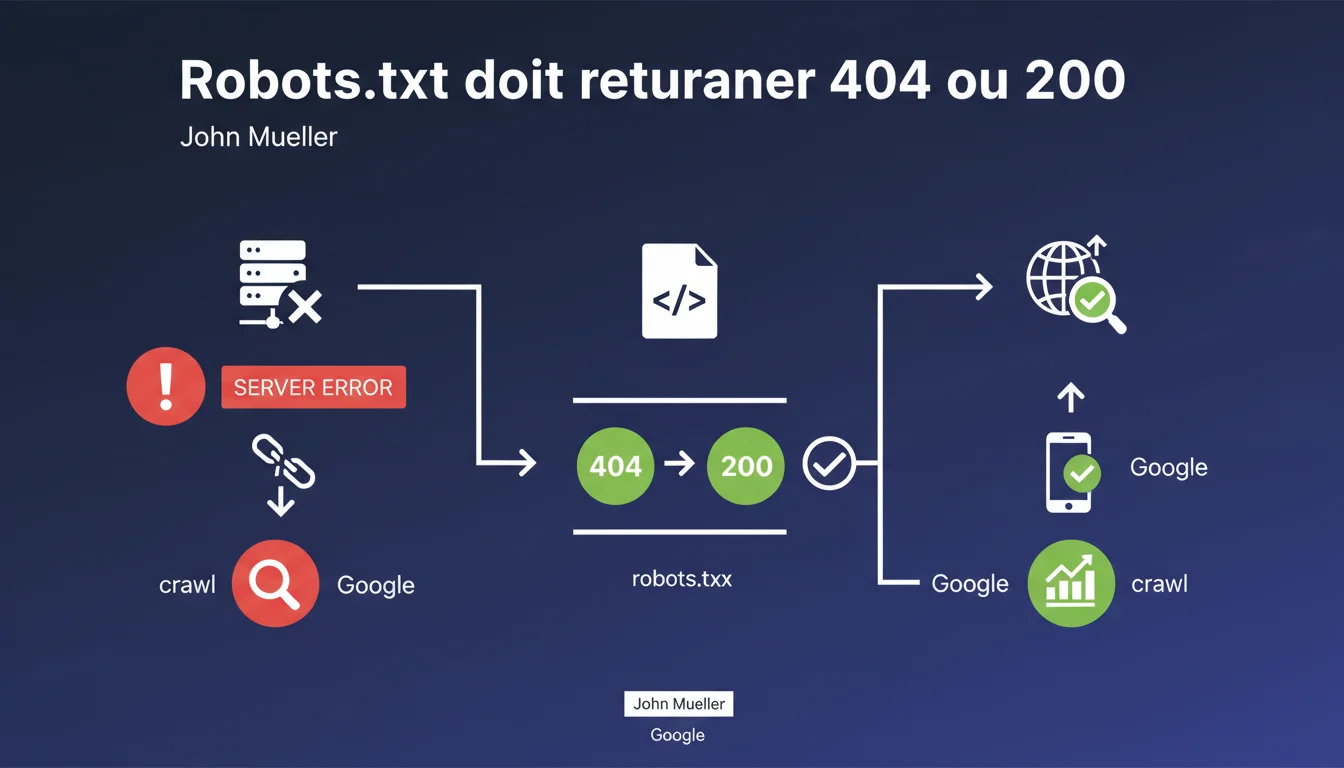
Google exige que le fichier robots.txt retourne soit un 200 (fichier présent), soit un 404 (fichier absent). Si le serveur renvoie une erreur 5xx, Googlebot considère qu'il y a un problème technique et suspend le crawl du site. Cette règle n'a rien de nouveau — elle s'applique depuis les débuts de Google.
Ce qu'il faut comprendre
Pourquoi Google bloque-t-il le crawl en cas d'erreur 5xx sur robots.txt ?
Quand Googlebot interroge /robots.txt, il attend une réponse claire : le fichier existe (200) ou n'existe pas (404). Dans les deux cas, le bot sait comment agir.
Si le serveur renvoie une erreur 5xx (500, 503, etc.), Google interprète cela comme un dysfonctionnement temporaire du serveur. Par précaution, il suspend le crawl pour ne pas surcharger un site déjà en difficulté. Ce n'est pas une punition — c'est une mesure de protection.
Que se passe-t-il concrètement si robots.txt retourne un code 5xx ?
Le site devient temporairement incrawlable. Googlebot reviendra tenter sa chance plus tard, mais tant que l'erreur persiste, aucune page ne sera explorée.
Si le problème dure plusieurs jours, les pages peuvent commencer à disparaître de l'index, faute de rafraîchissement. Les nouvelles pages ne seront pas découvertes. C'est un blocage total du pipeline de crawl.
Cette règle s'applique-t-elle aussi aux autres codes HTTP ?
Non. Seules les erreurs 5xx déclenchent ce comportement prudent. Un 404 signifie simplement « pas de robots.txt, je crawle tout ». Un 200 indique un fichier valide à respecter.
Les redirections 3xx sont généralement suivies, mais Google recommande d'éviter les chaînes de redirections complexes sur ce fichier critique. Un code 401/403 est traité comme un blocage volontaire — équivalent à un Disallow: / complet.
- Un 404 sur robots.txt = aucune restriction de crawl
- Un 200 sur robots.txt = fichier lu et appliqué
- Une erreur 5xx = crawl suspendu jusqu'à résolution
- Les redirections 3xx fonctionnent mais sont déconseillées pour ce fichier
- Un 401/403 équivaut à bloquer tout le site
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment la pratique terrain observée ?
Oui, et c'est vérifiable en quelques minutes. Provoquez une erreur 500 sur votre robots.txt en dev ou preprod, surveillez la Search Console : vous verrez le crawl chuter brutalement.
Ce comportement est documenté depuis des années dans les guidelines officielles, mais beaucoup de développeurs l'ignorent encore. Résultat : une mise à jour mal testée, un CDN qui bascule en erreur, et soudain plus rien ne bouge côté indexation.
Pourquoi certains sites échappent-ils temporairement à cette règle ?
Google peut faire preuve de tolérance temporaire sur des sites à forte autorité ou avec un historique de crawl stable. Si votre robots.txt plante pendant 15 minutes, Googlebot ne va pas paniquer immédiatement.
Mais ne comptez pas dessus. Un site récent, un domaine peu autoritaire, ou une erreur qui persiste plusieurs heures ? Le crawl s'arrête net. [A vérifier] : la durée exacte de tolérance varie selon le site, Google ne publie aucun chiffre officiel.
Faut-il vraiment surveiller ce fichier comme une ressource critique ?
Absolument. Le robots.txt est l'une des premières ressources interrogées par tous les bots — Google, Bing, mais aussi des crawlers tiers plus agressifs.
Un serveur qui craque sous la charge peut commencer à renvoyer des 503 justement sur ce fichier. Et là, c'est l'effet domino : plus de crawl légitime, donc plus d'indexation fraîche, donc baisse de visibilité. Tout ça parce qu'un fichier texte de 200 octets n'est plus accessible.
Impact pratique et recommandations
Comment vérifier que mon robots.txt renvoie le bon code HTTP ?
Utilisez curl en ligne de commande : curl -I https://votresite.com/robots.txt. La première ligne doit afficher HTTP/1.1 200 ou HTTP/1.1 404.
Côté Search Console, l'outil Inspection d'URL teste aussi le robots.txt automatiquement. Si Google détecte un problème, il vous alerte directement dans la section « Couverture ».
Que faire si mon serveur renvoie régulièrement des erreurs 5xx ?
D'abord, isolez la cause : charge serveur, timeout base de données, problème CDN ? Les logs serveur sont votre meilleur allié.
Si le problème est lié à un pic de trafic, envisagez de servir robots.txt depuis un cache statique ou un CDN dédié. Ce fichier change rarement — aucune raison qu'il sollicite la stack applicative complète.
Quelles erreurs éviter lors de la gestion du robots.txt ?
Ne bloquez jamais ce fichier par un autre mécanisme (authentification HTTP, IP whitelisting trop strict). Googlebot doit pouvoir y accéder avant même de crawler le reste.
Évitez également de générer ce fichier dynamiquement si votre CMS est fragile. Un robots.txt statique, versionné, et servi directement par le serveur web est infiniment plus fiable.
- Testez régulièrement le code HTTP retourné par /robots.txt (200 ou 404 uniquement)
- Configurez une alerte monitoring sur ce fichier (Uptime Robot, Pingdom, etc.)
- Vérifiez que votre CDN/WAF n'interfère pas avec l'accès à robots.txt
- Servez ce fichier en statique plutôt qu'en génération dynamique
- Consultez Search Console hebdomadairement pour détecter les anomalies de crawl
- Documentez le chemin exact du fichier dans votre infrastructure (root serveur, CDN, cache)
❓ Questions frequentes
Un site sans robots.txt peut-il être correctement indexé par Google ?
Combien de temps Google tolère-t-il une erreur 5xx sur robots.txt avant de suspendre le crawl ?
Est-ce que Bing et les autres moteurs appliquent la même règle ?
Peut-on rediriger /robots.txt vers une autre URL ?
Que se passe-t-il si robots.txt retourne un code 403 (Forbidden) ?
🎥 De la même vidéo 15
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 14/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.