Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Le mobile-first indexing a-t-il vraiment changé la donne en SEO depuis 2016 ?
- □ La balise meta keywords sert-elle encore à quelque chose en SEO ?
- □ Utiliser Google Analytics ou Chrome améliore-t-il vraiment votre référencement ?
- □ Pourquoi Google normalise-t-il votre HTML même quand il est cassé ?
- □ Le CSS influence-t-il réellement le poids SEO de vos balises H1-H6 ?
- □ Faut-il vraiment dé-optimiser certaines pages pour améliorer ses performances SEO ?
- □ Faut-il vraiment optimiser différemment chaque outil de suppression Google ?
- □ Pourquoi Google ne documente-t-il qu'une seule balise meta dans son guide SEO officiel ?
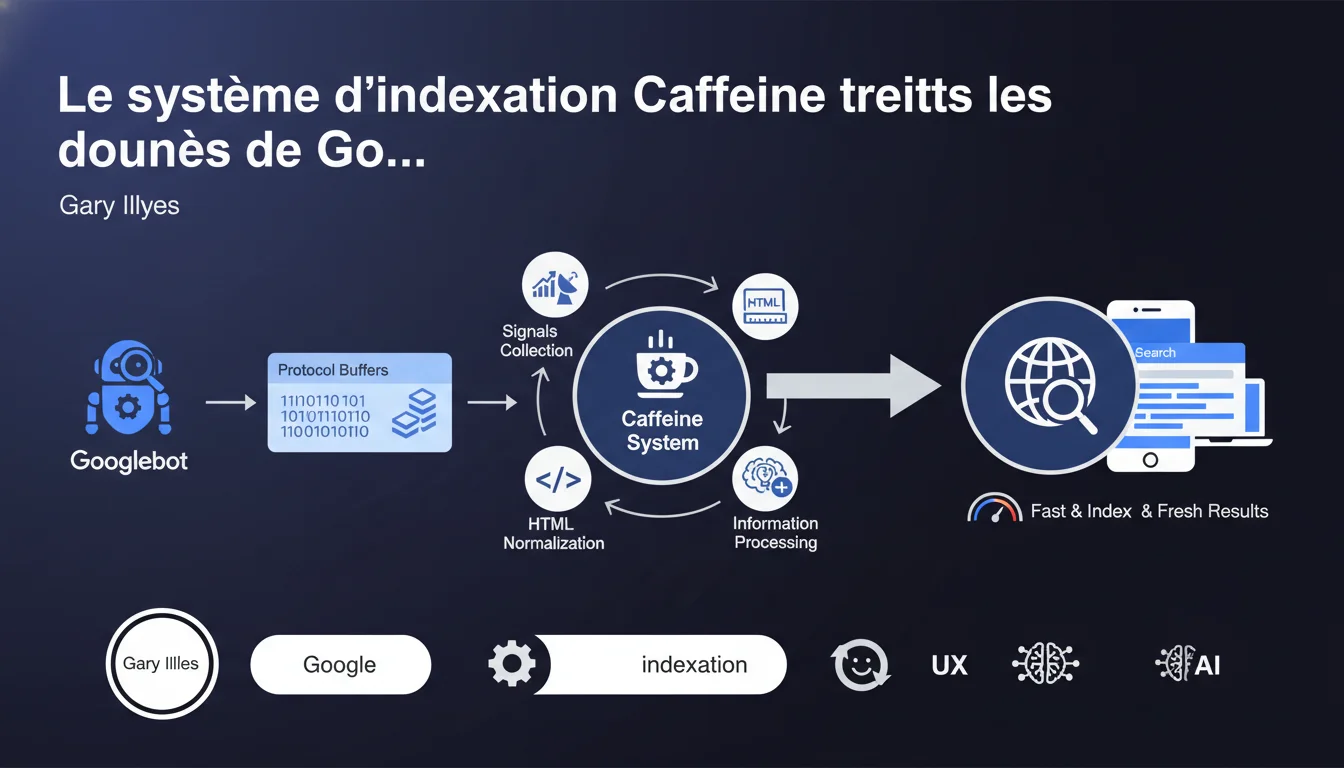
Caffeine est le nom du système d'indexation de Google qui traite les protocol buffers générés par Googlebot. Concrètement, il collecte les signaux de crawl, normalise le HTML récupéré et alimente l'index de recherche avec ces données structurées. Cette déclaration confirme l'architecture technique du pipeline entre exploration et indexation.
Ce qu'il faut comprendre
Qu'est-ce que Caffeine et pourquoi Google nous le rappelle maintenant ?
Caffeine est le système d'indexation de Google — pas le moteur de recherche lui-même, mais la couche qui digère ce que Googlebot ramène. Lancé en 2010, il a remplacé l'ancien système pour permettre une indexation plus rapide et continue.
Cette déclaration de Gary Illyes précise le rôle exact de Caffeine : il ingère les protocol buffers produits par Googlebot. Ces protocol buffers sont des fichiers de données structurées contenant le HTML brut, les métadonnées, les signaux de crawl — tout ce que le bot a collecté sur une page.
Que fait concrètement Caffeine avec ces données ?
Caffeine exécute trois opérations principales. D'abord, il collecte les signaux — temps de chargement, redirections, codes HTTP, liens internes et externes. Ensuite, il normalise le HTML : il corrige les balises mal fermées, restructure le DOM, élimine le code superflu.
Enfin, il ajoute tout ça à l'index — cette gigantesque base de données dans laquelle Google pioche pour répondre aux requêtes. Sans Caffeine, pas d'indexation. Sans indexation, pas de classement.
Pourquoi parler de protocol buffers plutôt que de HTML direct ?
Les protocol buffers sont un format de sérialisation développé par Google — plus compact et rapide à traiter que le XML ou le JSON. Googlebot ne transmet pas le HTML brut tel quel à Caffeine, il l'encapsule dans ces structures binaires optimisées.
Ça change quoi pour nous ? Rien directement — mais ça confirme que Google traite nos pages dans un pipeline industriel où chaque étape a son format propre. Le HTML que vous publiez n'est pas celui que Caffeine lit in fine.
- Caffeine est le système d'indexation, distinct du crawl (Googlebot) et du ranking (algorithmes de classement)
- Il ingère des protocol buffers, pas du HTML brut — la donnée est transformée avant indexation
- Ses trois rôles : collecte de signaux, normalisation du code, alimentation de l'index
- Toute page non traitée par Caffeine reste invisible dans les résultats de recherche
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Totalement. On sait depuis longtemps que Google normalise le HTML — d'où l'inutilité de s'acharner sur une validation W3C parfaite. Le DOM reconstitué par Caffeine n'est jamais strictement identique à votre code source.
Ce qui est intéressant ici, c'est la confirmation du rôle des signaux collectés dès l'étape d'indexation. Caffeine ne se contente pas d'enregistrer du texte — il agrège déjà des métriques techniques qui alimenteront plus tard les algorithmes de ranking. Temps de réponse serveur, profondeur de crawl, qualité du code : tout ça entre dans l'index avant même qu'on parle de pertinence sémantique.
Quelles nuances faut-il apporter à cette vision pipeline ?
Caffeine n'est pas un système figé. Google l'a mis à jour en continu depuis 2010 — notamment pour gérer le mobile-first, le JavaScript rendering, les Core Web Vitals. Ce que Gary Illyes décrit ici, c'est le principe de base, pas forcément l'état actuel du code.
Deuxième nuance : la normalisation du HTML peut masquer certains problèmes. Une balise mal fermée ? Caffeine la corrigera peut-être — mais ça ne garantit pas que l'intention sémantique d'origine soit préservée. Si votre <h1> est ouvert sans être fermé, Caffeine fera un choix arbitraire sur la portée du titre.
Où cette logique trouve-t-elle ses limites ?
Caffeine traite ce que Googlebot lui envoie — mais si le bot ne crawle pas, Caffeine ne voit rien. Les sites avec budget de crawl saturé, les pages bloquées par robots.txt, les contenus en infinite scroll mal implémenté : autant de cas où le problème se situe en amont.
Autre limite : le rendering JavaScript. Googlebot exécute JS avant d'envoyer les données à Caffeine, mais ce processus a ses propres contraintes — timeout, budget de calcul, compatibilité des frameworks. Si le contenu n'apparaît pas dans le DOM rendu, Caffeine n'indexera qu'une coquille vide.
Impact pratique et recommandations
Que faut-il vérifier concrètement sur son site ?
Commencez par l'inspection d'URL dans la Search Console — l'onglet "HTML" vous montre ce que Google a effectivement indexé. Comparez avec votre code source : si des éléments manquent, c'est soit un problème de crawl, soit un souci de rendering JavaScript.
Ensuite, traquez les erreurs HTML critiques qui pourraient perturber la normalisation : balises imbriquées incorrectement, attributs dupliqués, structures de données incohérentes. Un validateur HTML reste utile — non pour viser la perfection, mais pour détecter les anomalies grossières.
Quelles erreurs éviter absolument ?
Ne comptez jamais sur Caffeine pour "réparer" un mauvais code. La normalisation n'est pas magique — elle suit des règles, mais ces règles ne correspondent pas toujours à vos intentions. Un <title> mal fermé peut entraîner une coupure arbitraire du texte.
Deuxième erreur : ignorer les signaux techniques collectés. Caffeine enregistre bien plus que du texte — codes HTTP, redirections, vitesse de réponse. Un serveur lent ou instable laisse une trace dans l'index, même si le contenu est bon. Ces signaux influencent le crawl ultérieur et, indirectement, le ranking.
Comment s'assurer que l'indexation se passe correctement ?
Surveillez les rapports de couverture dans la Search Console. Pages explorées mais non indexées ? Souvent un signal que Caffeine a reçu les données mais les a jugées insuffisantes — contenu dupliqué, faible qualité, cannibalisation interne.
Utilisez aussi le test des résultats enrichis et l'outil d'inspection pour vérifier que vos données structurées sont bien ingérées. Caffeine les traite au même titre que le HTML — si elles sont mal formées, elles peuvent être ignorées ou mal interprétées.
- Comparer le code source et le HTML indexé via l'inspection d'URL
- Corriger les erreurs HTML structurelles qui perturbent le parsing
- Vérifier que le contenu JavaScript s'affiche bien dans le DOM rendu
- Surveiller les temps de réponse serveur — Caffeine enregistre ces signaux
- Auditer régulièrement les pages explorées non indexées
- Tester les données structurées pour s'assurer de leur bonne ingestion
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 03/11/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.