Declaration officielle
Autres déclarations de cette vidéo 15 ▾
- □ Hreflang booste-t-il vraiment le ranking dans un pays ciblé ?
- □ Faut-il vraiment réduire le nombre de pages pour optimiser son SEO international ?
- □ Comment Google détermine-t-il vraiment la langue d'une page multilingue ?
- □ Pourquoi Google ignore-t-il vos titres de page si la langue ne correspond pas au contenu ?
- □ Google utilise-t-il vraiment l'autorité de domaine pour classer les sites ?
- □ Pourquoi Googlebot refuse-t-il de cliquer sur vos boutons ?
- □ Les interstitiels JavaScript sont-ils vraiment sans risque pour le SEO ?
- □ Un bug technique pendant une Core Update peut-il vraiment faire chuter votre site ?
- □ Les problèmes techniques peuvent-ils vraiment déclencher une chute lors d'un Core Update ?
- □ La traduction de contenu est-elle pénalisée par Google ?
- □ Les traductions automatiques de mauvaise qualité peuvent-elles vraiment saboter votre SEO international ?
- □ Faut-il vraiment utiliser l'API d'indexation pour tous vos contenus ?
- □ Google favorise-t-il réellement ses propres plateformes dans les résultats de recherche ?
- □ La meta description influence-t-elle vraiment le classement dans Google ?
- □ Faut-il vraiment choisir ses données structurées en fonction des résultats enrichis visés ?
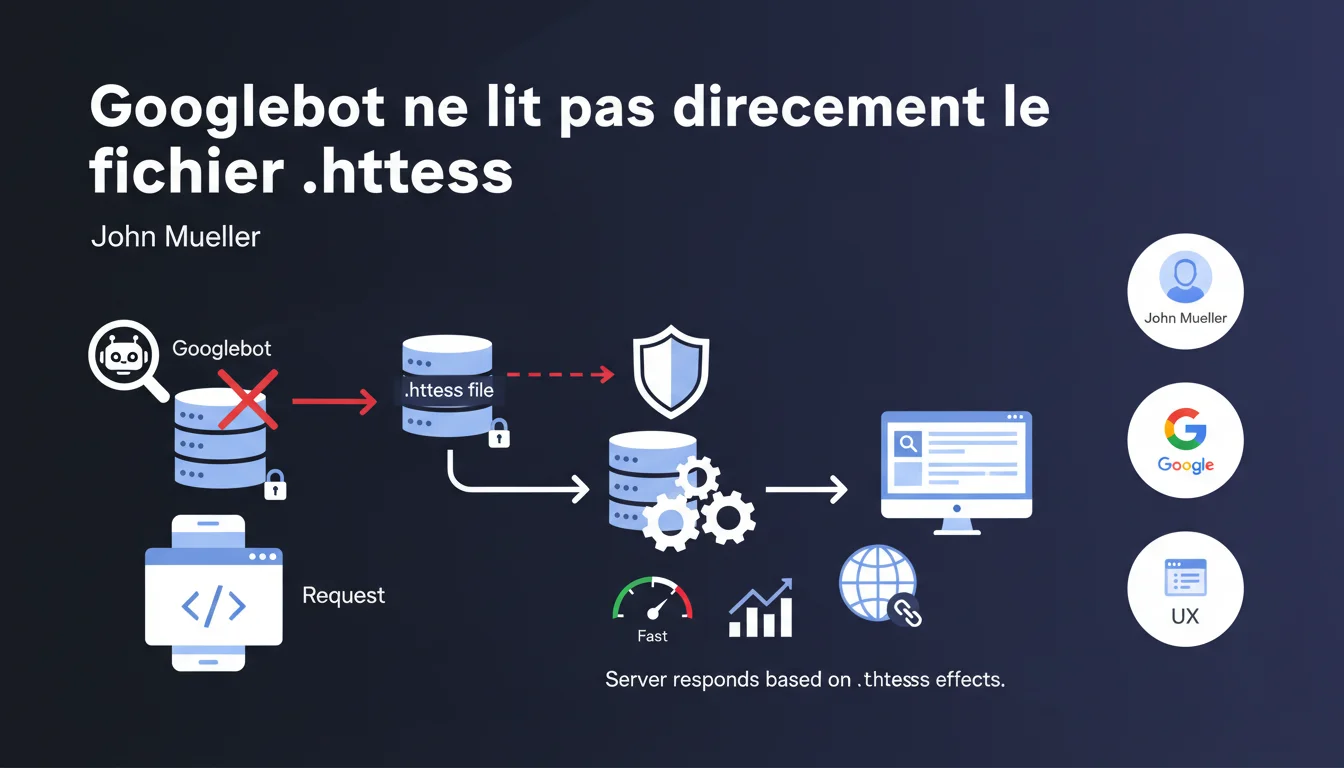
Googlebot ne lit jamais directement le fichier .htaccess car les serveurs web bloquent systématiquement son accès. En revanche, Google observe parfaitement les effets de ce fichier — redirections, blocages d'accès, réécriture d'URL — puisque le serveur applique ces règles avant de répondre au crawler.
Ce qu'il faut comprendre
Le fichier .htaccess est un élément de configuration invisible pour Googlebot, mais ses conséquences sont visibles à chaque requête. Cette nuance mérite qu'on s'y arrête.
Pourquoi Googlebot ne peut-il pas lire le .htaccess ?
Les serveurs Apache (et leurs équivalents) sont configurés par défaut pour interdire l'accès externe aux fichiers de configuration. Le .htaccess fait partie de ces ressources protégées.
Concrètement, si Googlebot tentait d'accéder à https://votresite.com/.htaccess, il recevrait une erreur 403 Forbidden. C'est une mesure de sécurité basique — exposer ce fichier révélerait la structure interne de votre configuration serveur.
Que voit réellement Google alors ?
Google n'a pas besoin de lire le fichier pour en constater les effets. Quand Googlebot demande une URL, le serveur applique d'abord les règles du .htaccess, puis renvoie une réponse HTTP.
Si vous avez configuré une redirection 301, Google reçoit le code 301 et l'URL de destination. Si vous bloquez l'accès à un répertoire, il reçoit un 403. Si vous réécrivez les URL via mod_rewrite, il voit l'URL finale servie.
Quelle différence avec robots.txt ?
Contrairement au robots.txt qui donne des instructions directes à Googlebot (« ne crawle pas ce répertoire »), le .htaccess agit au niveau serveur et s'applique à tous les visiteurs, humains ou robots.
Le robots.txt est une recommandation que Google respecte. Le .htaccess est une barrière technique que personne ne peut contourner — pas même Google.
- Googlebot ne peut jamais télécharger ni analyser le contenu du fichier .htaccess
- Google observe les réponses HTTP générées par les règles .htaccess (redirections, erreurs, réécritures)
- Les effets du .htaccess sont interprétés comme n'importe quelle autre réponse serveur
- Cette configuration serveur est invisible mais déterminante pour le crawl et l'indexation
Avis d'un expert SEO
Cette déclaration change-t-elle quelque chose aux pratiques SEO établies ?
Non. C'est une confirmation de ce que les praticiens savent depuis des années. Le .htaccess n'est pas un fichier de communication avec Google — c'est un outil de configuration serveur.
La confusion vient parfois du fait qu'on utilise le .htaccess pour implémenter des directives SEO : redirections 301, canonicalisation www/non-www, blocage de paramètres. Mais Google ne « lit » pas ces intentions — il constate simplement les résultats.
Faut-il s'inquiéter de la visibilité de nos règles .htaccess ?
Si votre serveur est correctement configuré, non. La vraie question est : vos règles produisent-elles les effets attendus côté Googlebot ?
J'ai vu des cas où des redirections .htaccess étaient techniquement fonctionnelles mais généraient des chaînes de redirections inutiles. Google suit ces redirections, mais ça rallonge le crawl et dilue le PageRank. Autre exemple : des règles RewriteCond mal configurées qui bloquaient Googlebot sans que l'équipe technique s'en rende compte.
Quels sont les pièges à éviter avec le .htaccess en SEO ?
Le premier piège : croire qu'une règle .htaccess est invisible pour Google parce que le fichier ne peut pas être lu. Faux. Tout ce qui modifie la réponse HTTP est visible par Google.
Deuxième piège : tester vos redirections uniquement dans un navigateur. Les navigateurs cachent certains comportements (mise en cache agressive, gestion des cookies). Testez toujours avec curl -I ou l'outil d'inspection d'URL de la Search Console pour voir ce que Googlebot reçoit réellement.
User-Agent trop restrictif) peut passer inaperçue pendant des semaines si vous ne surveillez pas vos logs serveur.Impact pratique et recommandations
Comment vérifier que vos règles .htaccess n'impactent pas négativement le crawl ?
Utilisez l'outil d'inspection d'URL de la Google Search Console pour tester vos pages critiques. Cet outil simule le comportement de Googlebot et vous montre exactement quelle réponse HTTP il reçoit.
Consultez régulièrement vos logs serveur. Cherchez les erreurs 403, 404 ou 500 déclenchées par Googlebot — elles révèlent souvent des règles .htaccess trop restrictives ou mal ciblées.
Quelles erreurs .htaccess sont critiques pour le SEO ?
Les redirections en chaîne. Si une règle redirige A vers B, puis une autre règle redirige B vers C, Google perd du temps et du crawl budget. Simplifiez : redirigez A directement vers C.
Les blocages accidentels. Une règle qui bloque un répertoire entier (Deny from all) alors que vous vouliez bloquer un seul fichier. Résultat : des sections entières de votre site deviennent inaccessibles à Google.
Que faut-il faire concrètement dès maintenant ?
- Auditez votre fichier .htaccess : identifiez toutes les règles qui affectent les réponses HTTP (redirections, blocages, réécritures)
- Testez chaque règle critique avec
curl -Ipour vérifier la réponse exacte renvoyée au crawler - Vérifiez dans la Search Console qu'aucune URL importante ne retourne une erreur 4xx ou 5xx liée à une règle .htaccess
- Analysez vos logs serveur pour repérer les patterns d'erreur déclenchés par Googlebot
- Documentez chaque règle .htaccess : dans 6 mois, vous aurez oublié pourquoi elle existe
- Éliminez les redirections en chaîne — une redirection = un saut, pas trois
❓ Questions frequentes
Googlebot peut-il contourner les restrictions définies dans le .htaccess ?
Faut-il protéger le fichier .htaccess avec des règles spécifiques ?
Les redirections .htaccess sont-elles équivalentes aux redirections PHP pour Google ?
Une erreur dans le .htaccess peut-elle empêcher l'indexation de tout mon site ?
Google peut-il détecter si j'affiche un contenu différent à Googlebot via .htaccess ?
🎥 De la même vidéo 15
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/04/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.