Declaration officielle
Autres déclarations de cette vidéo 15 ▾
- □ Hreflang booste-t-il vraiment le ranking dans un pays ciblé ?
- □ Faut-il vraiment réduire le nombre de pages pour optimiser son SEO international ?
- □ Comment Google détermine-t-il vraiment la langue d'une page multilingue ?
- □ Pourquoi Google ignore-t-il vos titres de page si la langue ne correspond pas au contenu ?
- □ Google utilise-t-il vraiment l'autorité de domaine pour classer les sites ?
- □ Pourquoi Googlebot refuse-t-il de cliquer sur vos boutons ?
- □ Les interstitiels JavaScript sont-ils vraiment sans risque pour le SEO ?
- □ Un bug technique pendant une Core Update peut-il vraiment faire chuter votre site ?
- □ Les problèmes techniques peuvent-ils vraiment déclencher une chute lors d'un Core Update ?
- □ La traduction de contenu est-elle pénalisée par Google ?
- □ Les traductions automatiques de mauvaise qualité peuvent-elles vraiment saboter votre SEO international ?
- □ Faut-il vraiment utiliser l'API d'indexation pour tous vos contenus ?
- □ Googlebot peut-il accéder à votre fichier .htaccess ?
- □ Google favorise-t-il réellement ses propres plateformes dans les résultats de recherche ?
- □ La meta description influence-t-elle vraiment le classement dans Google ?
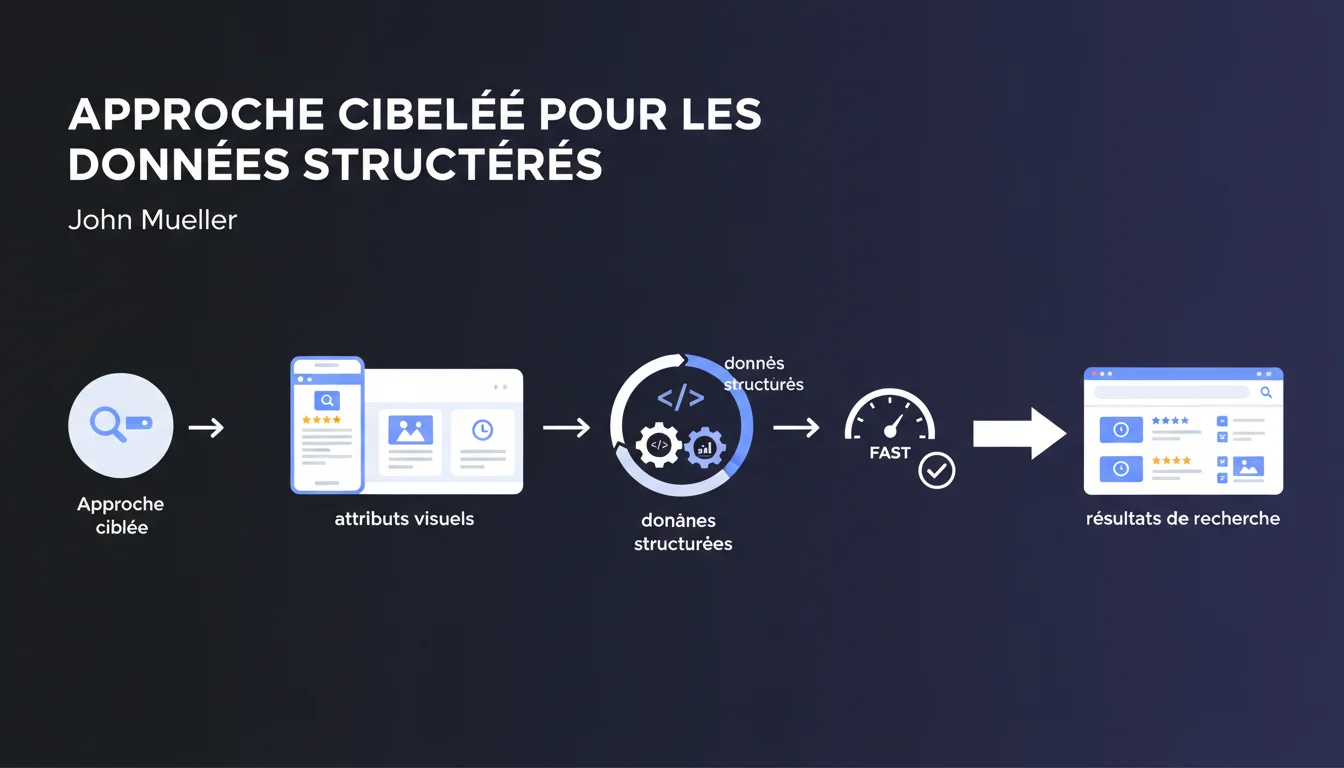
Google inverse la logique traditionnelle : au lieu de plaquer des données structurées selon la typologie du site, il faut d'abord identifier quels extraits enrichis on vise dans les SERP, puis implémenter uniquement les schémas qui déclenchent ces affichages. Une approche orientée résultat plutôt que conformité aveugle.
Ce qu'il faut comprendre
La déclaration de John Mueller remet en cause une pratique courante : celle qui consiste à implémenter systématiquement tous les schémas disponibles pour un type de contenu donné. Beaucoup de sites e-commerce, par exemple, ajoutent Product, Offer, Review, AggregateRating, BreadcrumbList... sans vraiment se demander à quoi ça sert.
L'approche proposée inverse le raisonnement. Elle part du résultat souhaité dans les SERP — étoiles d'avis, prix, disponibilité, FAQ accordéon, fil d'Ariane — puis identifie les données structurées spécifiques qui déclenchent ces affichages.
Pourquoi Google encourage-t-il cette méthode ciblée ?
Parce que l'inflation des données structurées pose un problème de qualité. Trop de sites implémentent des schémas inutiles, parfois mal renseignés, qui polluent l'extraction sémantique sans apporter de valeur ni au moteur ni à l'utilisateur.
En poussant les webmasters à se concentrer sur ce qui a un impact visible, Google filtre implicitement les implémentations. Seuls les attributs qui génèrent un gain d'affichage justifient l'effort — et donc l'exactitude des données.
Concrètement, qu'est-ce qui change pour les praticiens SEO ?
La démarche devient stratégique plutôt que technique. Avant de coder, il faut scanner les SERP concurrentes, identifier quels rich snippets apparaissent pour les requêtes cibles, puis vérifier dans la documentation Google quels schémas déclenchent ces affichages.
Ça signifie aussi qu'il ne sert à rien d'implémenter du schéma qui n'a aucun équivalent visuel dans les résultats. Si Google n'affiche jamais de recipes en carrousel pour votre niche, implémenter Recipe devient inutile — sauf si vous visez d'autres moteurs ou assistants vocaux.
- L'objectif visuel prime sur la conformité théorique au schéma
- Une implémentation minimaliste ciblée vaut mieux qu'un catalogue exhaustif mal renseigné
- Il faut analyser les SERP avant d'implémenter, pas après
- Les données structurées deviennent un levier d'affichage, pas une checklist de conformité
Avis d'un expert SEO
Cette approche est-elle vraiment nouvelle ou juste un recadrage ?
Soyons honnêtes : les praticiens expérimentés font déjà ça depuis des années. Personne ne perd son temps à implémenter des schémas sans retour visible. Mais la déclaration officialise un principe que beaucoup appliquaient empiriquement.
Ce qui change, c'est que Google le dit publiquement. Ça donne une légitimité pour refuser les demandes clients du type « on veut tout le schéma possible ». Le gain : concentrer les efforts sur ce qui déplace réellement l'aiguille dans les SERP.
Quels sont les angles morts de cette recommandation ?
Le problème, c'est que Google ne documente pas toujours clairement quels schémas déclenchent quels affichages. Certains rich snippets apparaissent de manière imprévisible, voire intermittente. [A vérifier] : l'algorithme qui décide d'afficher ou non un extrait enrichi reste opaque.
Autre point : cette logique fonctionne bien pour les résultats classiques, mais qu'en est-il des assistants vocaux, de Google Discover, des featured snippets complexes ? Certains schémas n'ont peut-être aucun impact visible sur desktop mais jouent un rôle dans d'autres contextes d'affichage.
Dans quels cas cette règle ne s'applique-t-elle pas complètement ?
Pour les sites d'actualités, par exemple, implémenter NewsArticle avec des métadonnées complètes reste indispensable même si l'affichage en Top Stories n'est jamais garanti. Google utilise ces données pour déterminer l'éligibilité elle-même.
Idem pour les sites locaux : LocalBusiness doit être implémenté de façon exhaustive, même si tous les champs ne génèrent pas un affichage visible. Certains attributs servent au matching sémantique plus qu'à l'enrichissement visuel.
Impact pratique et recommandations
Que faut-il faire concrètement pour appliquer cette approche ?
D'abord, auditer les SERP concurrentes sur vos requêtes cibles. Identifiez quels types d'extraits enrichis apparaissent : étoiles, prix, FAQ, How-To, vidéos, images... Notez ceux qui génèrent le plus de clics ou d'attention visuelle.
Ensuite, consultez la documentation officielle de Google sur les résultats enrichis éligibles. Croisez avec vos observations terrain : certains affichages documentés n'apparaissent jamais dans votre secteur, d'autres non documentés peuvent émerger.
Une fois les cibles identifiées, implémentez uniquement les schémas correspondants. Testez avec l'outil de validation Google, puis mesurez l'impact réel dans Search Console : impressions, CTR, apparition dans les rapports d'amélioration.
Quelles erreurs éviter absolument ?
Ne pas implémenter des données structurées par mimétisme sans vérifier qu'elles génèrent un affichage. Beaucoup de sites copient le schéma d'un concurrent sans analyser si celui-ci produit effectivement un rich snippet.
Éviter aussi le piège inverse : négliger un schéma parce qu'il ne génère pas d'affichage immédiat. Certains attributs servent au contexte sémantique global — ils ne sont pas inutiles, juste moins directement mesurables.
Enfin, ne pas oublier que les règles d'éligibilité évoluent. Un schéma inactif aujourd'hui peut devenir déclencheur demain. Une veille régulière sur les évolutions des SERP reste indispensable.
- Scanner les SERP concurrentes pour identifier les extraits enrichis présents
- Vérifier la documentation Google pour connaître les schémas déclencheurs
- Implémenter uniquement les données structurées qui correspondent aux affichages visés
- Tester l'implémentation avec l'outil de test des résultats enrichis
- Mesurer l'impact via Search Console (impressions, CTR, rapports d'amélioration)
- Documenter quels schémas génèrent quels affichages dans votre secteur spécifique
- Planifier une revue trimestrielle des SERP pour détecter les nouveaux formats
❓ Questions frequentes
Dois-je supprimer les données structurées qui ne génèrent pas d'affichage enrichi ?
Comment savoir quels schémas déclenchent quels affichages dans ma niche ?
Cette approche s'applique-t-elle aux sites d'actualités et aux sites locaux ?
Faut-il implémenter des données structurées qui n'ont aucun impact visible aujourd'hui ?
L'outil de test des résultats enrichis garantit-il l'affichage effectif ?
🎥 De la même vidéo 15
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/04/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.