Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Peut-on publier le même contenu en HTML et PDF sans risque de duplicate content ?
- □ Google indexe-t-il vraiment le HTML et le PDF de manière indépendante ?
- □ Comment gérer efficacement le contenu dupliqué entre HTML et PDF ?
- □ Faut-il vraiment inclure un lien vers son site dans chaque PDF publié ?
- □ Faut-il vraiment choisir entre HTML et PDF selon le support de consultation ?
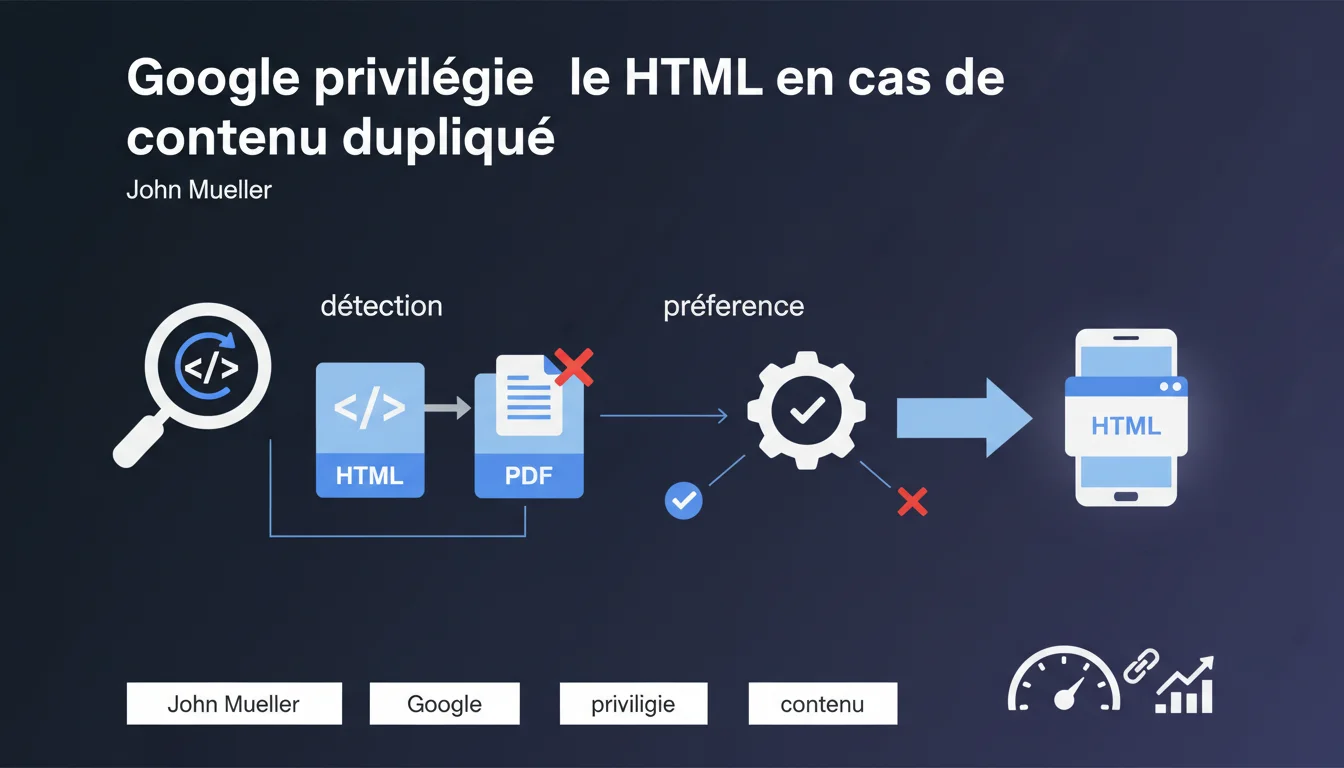
Quand Google détecte du contenu identique disponible en HTML et en PDF, il indexe préférentiellement la version HTML. Cette logique s'explique par la structure native du HTML, plus facilement exploitable par les crawlers. Pour éviter les doublons dans l'index, mieux vaut canonicaliser ou bloquer les PDF redondants.
Ce qu'il faut comprendre
Pourquoi Google préfère-t-il le HTML au PDF ?
Le HTML est le format natif du web. Il structure le contenu avec des balises sémantiques que Googlebot analyse sans effort : titres, paragraphes, liens, métadonnées. Le PDF, lui, nécessite une extraction — Google doit d'abord convertir le texte, repérer les titres (souvent absents ou mal balisés), gérer les images et les tableaux. C'est plus lent, moins fiable.
Quand les deux versions existent, Google choisit la voie du moindre effort : celle qui lui donne accès au contenu structuré de manière claire et directe.
Comment Google détecte-t-il le contenu dupliqué entre HTML et PDF ?
Les systèmes de Google comparent les empreintes textuelles des pages. Si le contenu principal est identique ou quasi-identique, il y a détection de duplication. Le moteur sélectionne ensuite la version qu'il juge la plus pertinente pour l'utilisateur — et c'est presque toujours le HTML.
Cette logique vaut aussi entre plusieurs PDF, ou entre plusieurs HTML. Mais dans un duel HTML vs PDF, le HTML gagne à tous les coups.
Quelles sont les implications pour l'indexation et le ranking ?
Si vous publiez un whitepaper en PDF et que vous reprenez le même texte mot pour mot sur une page HTML, Google n'indexera probablement que la page HTML. Le PDF sera ignoré ou considéré comme une variante secondaire, voire exclu de l'index principal.
Concrètement : vous perdez l'opportunité de ranker sur deux URLs distinctes, et vous risquez de diluer le signal si Google hésite entre les deux avant de trancher.
- Google favorise le HTML pour sa structure sémantique native
- Le PDF nécessite une extraction, plus coûteuse en ressources crawl
- En cas de duplication, un seul document est indexé — généralement le HTML
- Les métadonnées et balises du HTML sont mieux exploitées par les algorithmes de ranking
- Le PDF n'est conservé que s'il apporte une valeur unique ou si aucun HTML équivalent n'existe
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui — et on le constate depuis des années. Quand un site publie un rapport en PDF et crée une landing page HTML qui reprend les mêmes chapitres, c'est presque toujours la page HTML qui apparaît dans les SERP. Les PDF ne se positionnent en première page que lorsqu'ils sont uniques ou que la concurrence HTML est faible.
Soyons honnêtes : le PDF a longtemps été un format pénalisant en SEO. Il fonctionne mieux pour la distribution (téléchargement, impression) que pour l'indexation organique.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si le PDF contient du contenu exclusif — schémas annotés, tableaux complexes, annexes techniques — Google peut l'indexer même si une page HTML existe par ailleurs. Mais attention : il faut que le PDF apporte une vraie valeur différentielle, pas juste une mise en page différente du même texte.
Autre exception : les sites officiels (gouvernements, institutions) où Google accorde parfois plus de poids aux documents PDF publiés comme références. Mais c'est marginal. [A vérifier] : on manque de données publiques sur les seuils exacts de similarité qui déclenchent la dépriorisation du PDF.
Quelles nuances faut-il apporter à cette déclaration de Mueller ?
Mueller parle de "privilégier" le HTML, pas de supprimer le PDF de l'index. Nuance importante. Si votre PDF contient des éléments uniques — même mineurs — Google peut l'indexer en complément. Mais il n'apparaîtra jamais en concurrence directe avec le HTML sur la même requête.
Autre point : cette logique vaut pour le contenu textuel. Si votre PDF contient des infographies, des schémas techniques ou des datasets en tableaux, il peut survivre dans l'index — mais pour des requêtes différentes, souvent plus spécialisées.
Impact pratique et recommandations
Que faut-il faire concrètement avec les PDF dupliqués ?
Si vous avez un PDF et un HTML qui racontent la même histoire, choisissez votre camp. Soit vous gardez le PDF comme ressource téléchargeable (avec noindex ou canonical vers le HTML), soit vous supprimez le HTML et vous misez tout sur le PDF — mais c'est rarement la meilleure stratégie SEO.
L'idéal : publier le contenu en HTML structuré, et proposer le PDF en version imprimable ou pour archivage. Le PDF devient un complément, pas un concurrent.
Comment éviter la cannibalisation entre HTML et PDF ?
Première solution : ajouter une balise canonical dans les métadonnées du PDF pointant vers le HTML. Oui, c'est possible — via un fichier XMP ou un header HTTP. Mais c'est technique et rarement mis en œuvre.
Deuxième solution : bloquer l'indexation du PDF avec un X-Robots-Tag: noindex dans les headers HTTP. Plus simple, plus fiable. Le PDF reste accessible en téléchargement, mais Google ne l'indexe pas.
Troisième solution : différencier vraiment les contenus. Le HTML donne une vue d'ensemble, le PDF va plus loin avec des annexes, des données brutes, des schémas. Là, les deux peuvent coexister sans problème.
Quelles erreurs éviter absolument ?
Ne publiez jamais un PDF et un HTML identiques sans signaler à Google lequel privilégier. Vous laissez le moteur trancher — et il ne choisira pas forcément celui que vous voulez.
Évitez aussi de multiplier les versions PDF d'un même document (v1, v2, v3…) sans redirection. Google va indexer plusieurs URLs concurrentes, diluer le signal, et vous perdrez du ranking sur toutes.
- Auditer les PDF présents sur le site et vérifier s'ils dupliquent du contenu HTML
- Ajouter un X-Robots-Tag: noindex sur les PDF redondants
- Utiliser une canonical HTML → HTML si plusieurs versions HTML coexistent
- Structurer le HTML avec des balises sémantiques claires (h1, h2, schema.org)
- Proposer le PDF en téléchargement depuis la page HTML, mais ne pas l'indexer séparément
- Surveiller la Search Console pour détecter les PDF indexés par erreur
- Rediriger 301 les anciennes versions PDF vers la version HTML actuelle
❓ Questions frequentes
Google indexe-t-il encore les PDF en 2024 ?
Peut-on ajouter une balise canonical dans un PDF ?
Si mon PDF rank mieux que mon HTML, dois-je le garder ?
Comment vérifier si Google a indexé mes PDF ?
Dois-je supprimer tous mes PDF du site ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.