Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Peut-on publier le même contenu en HTML et PDF sans risque de duplicate content ?
- □ Google indexe-t-il vraiment le HTML et le PDF de manière indépendante ?
- □ Google privilégie-t-il vraiment le HTML face au PDF en cas de contenu dupliqué ?
- □ Faut-il vraiment inclure un lien vers son site dans chaque PDF publié ?
- □ Faut-il vraiment choisir entre HTML et PDF selon le support de consultation ?
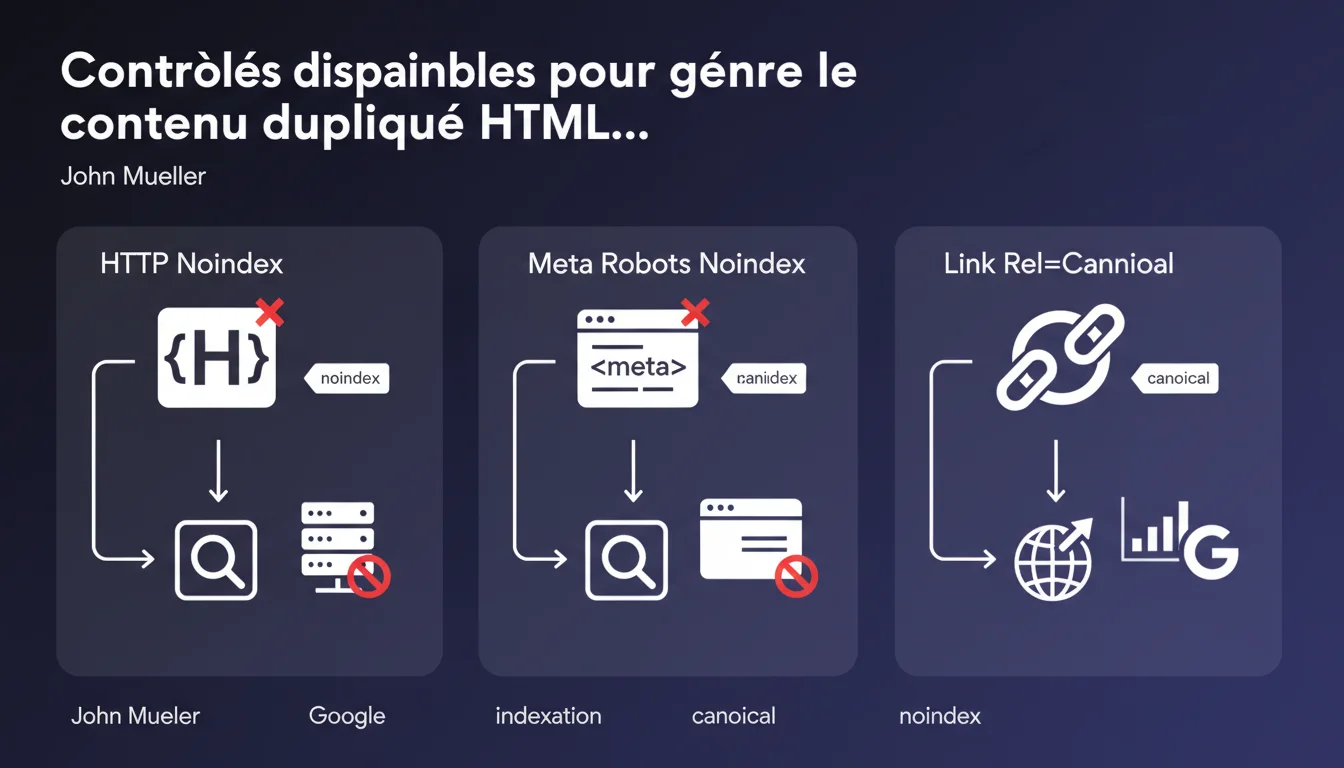
Google confirme trois leviers techniques pour contrôler l'indexation de contenus dupliqués HTML/PDF : l'en-tête HTTP noindex, la balise meta robots, ou le rel=canonical. Ces outils permettent d'indiquer quelle version privilégier et d'éviter la dilution d'autorité entre formats identiques.
Ce qu'il faut comprendre
Pourquoi Google mentionne-t-il spécifiquement le couple HTML/PDF ?
Les fichiers PDF sont indexables au même titre que les pages HTML. Quand un site propose le même contenu dans les deux formats — typique des études, rapports ou documentations techniques — Google doit choisir quelle version afficher dans les résultats.
Sans directive explicite, le moteur applique ses propres heuristiques. Résultat : la version PDF peut cannibaliser le trafic de la page HTML optimisée, ou inversement. Le risque principal est la dilution de l'autorité entre deux URLs concurrentes pour un même contenu.
Quels sont les trois contrôles évoqués par Mueller ?
Première option : l'en-tête HTTP noindex. Il bloque l'indexation côté serveur, avant même que le crawl ne traite le document. Efficace pour les PDF générés dynamiquement ou les versions imprimables.
Deuxième levier : la balise meta robots dans le <head> du HTML ou intégrée au PDF. Plus accessible pour les CMS standards, mais nécessite que Googlebot parse le document.
Troisième méthode : le rel=canonical. Il n'empêche pas l'indexation mais signale à Google quelle URL traiter comme référence canonique. Utile quand on veut garder le PDF accessible tout en consolidant l'autorité sur la page HTML.
Quelle méthode privilégier selon le contexte ?
- Si le PDF n'apporte aucune valeur SEO : noindex via en-tête HTTP ou meta robots
- Si les deux versions doivent rester découvrables mais une doit primer : rel=canonical vers la version stratégique
- Si le contenu change fréquemment : privilégier le HTML avec canonical, le PDF étant souvent obsolète plus vite
- Pour les documentations techniques où le PDF est la référence : pointer le canonical du HTML vers le PDF
Avis d'un expert SEO
Cette recommandation correspond-elle aux pratiques observées sur le terrain ?
Oui, mais avec des nuances importantes. Les trois méthodes fonctionnent, mais leur efficacité varie selon l'architecture du site et la nature du contenu. Les PDF hébergés sur des domaines tiers (type Slideshare, Issuu) échappent souvent au contrôle via canonical — là, seul le noindex est viable si on peut intervenir côté serveur.
Un point que Mueller n'aborde pas : la gestion des PDF multi-pages. Quand un document de 50 pages génère autant d'URLs distinctes en HTML, le rel=canonical devient vite ingérable. Dans ce cas, mieux vaut bloquer complètement l'indexation du PDF et structurer le HTML en chapitres avec un maillage interne cohérent.
Quelles sont les limites non mentionnées de ces contrôles ?
Le rel=canonical est une directive, pas une instruction. Google peut l'ignorer s'il estime que la version non-canonique est plus pertinente pour une requête donnée. J'ai vu des cas où le PDF rankait malgré un canonical vers le HTML, notamment quand le PDF contenait des annotations ou une mise en forme jugée supérieure. [À vérifier] : le poids exact accordé au canonical dans les arbitrages HTML/PDF reste flou — Google ne publie aucune métrique.
Autre angle mort : les performances. Un PDF lourd ralentit le crawl, consomme du budget bot inutilement même avec un noindex. Si le fichier pèse 10 Mo et que Googlebot le télécharge systématiquement pour vérifier l'en-tête noindex, c'est du gâchis. Là, un Disallow dans le robots.txt est plus radical mais empêche aussi le suivi des liens internes dans le PDF.
Faut-il systématiquement choisir entre HTML et PDF ?
Non, pas toujours. Certains contenus gagnent à être indexés dans les deux formats : le HTML capte les requêtes informationnelles longue traîne, le PDF se positionne sur des recherches type "guide complet [thème] filetype:pdf". Dans ce scénario, il faut différencier les optimisations : titre, meta description, contenu éditorial enrichi côté HTML ; densité documentaire et structure d'index côté PDF.
Impact pratique et recommandations
Que faut-il auditer en priorité sur un site existant ?
Première étape : identifier tous les doublons HTML/PDF indexés. Requête site:example.com filetype:pdf dans Google, puis croiser avec un crawl Screaming Frog pour repérer les contenus en double. Listez les paires où le même texte existe en HTML et PDF.
Deuxième vérification : les signaux contradictoires. Un PDF avec un canonical vers une page HTML qui elle-même renvoie un noindex créera de la confusion. Vérifiez que les directives pointent dans une direction cohérente.
Comment implémenter techniquement ces contrôles ?
Pour les PDF statiques hébergés sur Apache/Nginx, ajouter un en-tête noindex via .htaccess ou configuration serveur. Exemple : Header set X-Robots-Tag "noindex" pour tous les fichiers *.pdf.
Sur WordPress ou CMS similaires, utiliser un plugin SEO (Yoast, RankMath) pour ajouter la balise meta robots sur les pages HTML de téléchargement. Si le PDF est généré dynamiquement, injecter l'en-tête HTTP au moment de la génération.
Pour le rel=canonical : insérer <link rel="canonical" href="URL_VERSION_PRINCIPALE" /> dans le <head> de la version secondaire. Côté PDF, c'est plus technique — certains générateurs permettent d'ajouter des métadonnées XMP, mais Google ne garantit pas leur lecture. Mieux vaut alors ne pas indexer le PDF si le canonical ne peut être injecté proprement.
Quelles erreurs éviter absolument ?
- Ne jamais utiliser
Disallowdans robots.txt si vous voulez que Google respecte le canonical — il faut que le bot accède au fichier - Éviter de mettre un noindex ET un canonical sur la même ressource : le noindex empêchera Google de transférer l'autorité
- Ne pas oublier de vérifier les versions mobiles : certains CMS servent des PDF différents selon le device
- Surveiller les mises à jour de contenu : un PDF obsolète laissé indexé dégrade l'expérience utilisateur et peut nuire à la réputation
- Attention aux PDF générés depuis des outils tiers (Canva, Google Docs exportés) : ils embarquent parfois des métadonnées parasites
La gestion du contenu dupliqué HTML/PDF exige une stratégie claire par type de document : bloquer l'indexation des formats redondants sans valeur ajoutée, canonicaliser ceux qui doivent coexister, et auditer régulièrement la cohérence des signaux envoyés à Google.
Ces arbitrages techniques — choix entre noindex et canonical, configuration serveur, analyse des doublons — demandent une expertise pointue et du temps. Si votre site génère des centaines de PDF ou que l'architecture est complexe, s'appuyer sur une agence SEO spécialisée permet d'éviter les erreurs coûteuses et d'implémenter une gouvernance documentaire solide sur le long terme.
❓ Questions frequentes
Un PDF peut-il pointer vers une page HTML via rel=canonical ?
Que se passe-t-il si j'oublie de canonicaliser et que les deux versions sont indexées ?
Le noindex via meta robots fonctionne-t-il dans un PDF ?
Dois-je désindexer tous mes PDF pour éviter le duplicate content ?
Comment vérifier que Google a bien pris en compte mon noindex sur un PDF ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.