Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Le keyword stuffing est-il vraiment pénalisé par Google ?
- □ Le texte caché est-il toujours considéré comme du spam par Google ?
- □ Le contenu généré aléatoirement fait-il vraiment partie des pratiques spam selon Google ?
- □ Les backlinks sont-ils devenus inutiles pour le référencement naturel ?
- □ Le HTML valide est-il vraiment nécessaire pour bien se classer dans Google ?
- □ Pourquoi Google insiste-t-il autant sur les vraies balises <a href> ?
- □ Faut-il vraiment abandonner les images CSS au profit des balises <img> pour le SEO ?
- □ Le noindex est-il vraiment une règle absolue ou Google prend-il des libertés ?
- □ HTTPS est-il vraiment obligatoire pour être indexé par Google ?
- □ Pourquoi Google recommande-t-il d'abandonner les plugins pour afficher du contenu web ?
- □ L'alt text des images reste-t-il vraiment indispensable face à la vision par ordinateur de Google ?
- □ Les directives SEO de Google sont-elles vraiment fiables sur la durée ?
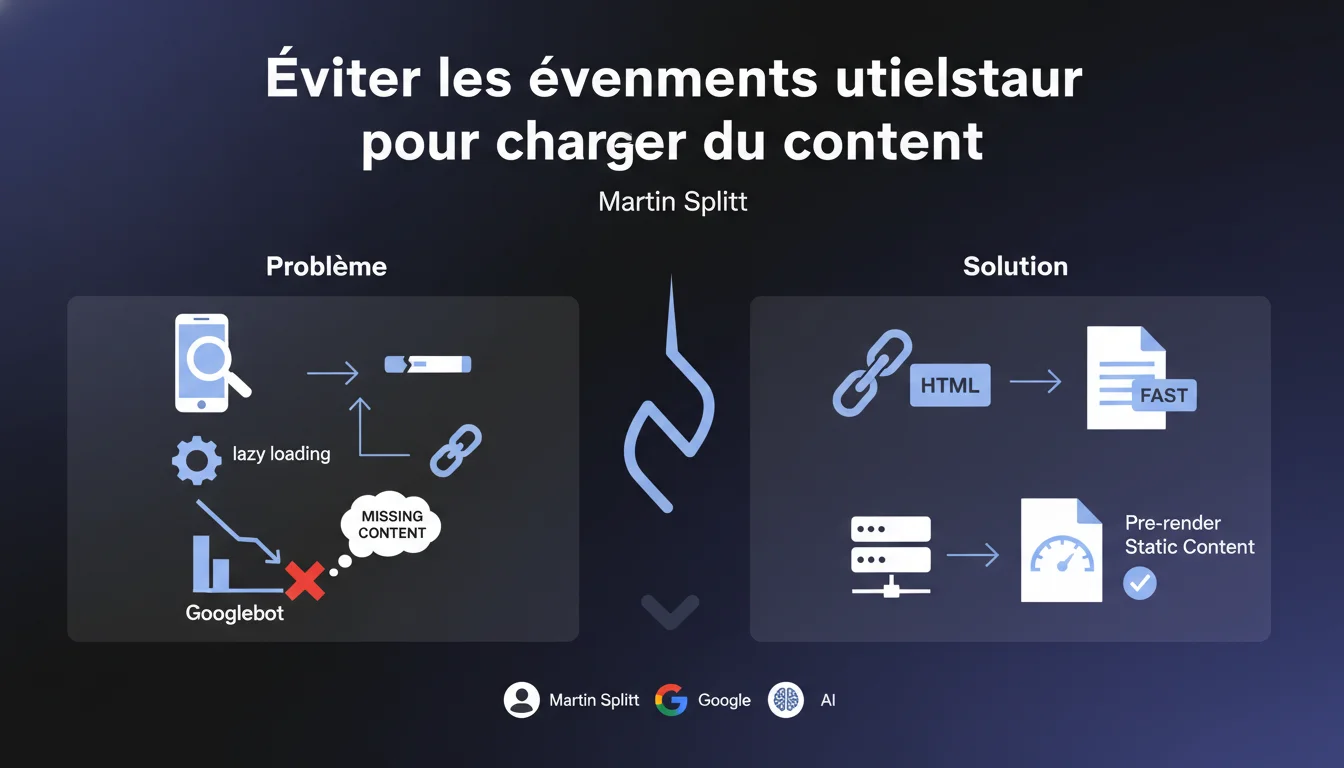
Google ne simule pas les interactions utilisateur (scroll, clic) lors du crawl. Tout contenu masqué derrière ces événements risque de ne jamais être indexé. Concrètement : exit le lazy loading au scroll, exit les boutons « Voir plus » pour charger du texte, exit les accordéons qui nécessitent un clic pour révéler du contenu essentiel.
Ce qu'il faut comprendre
Que se passe-t-il exactement quand Googlebot explore une page ?
Googlebot charge le HTML brut, exécute le JavaScript disponible, puis analyse ce qui est rendu dans le DOM. Il ne scrolle pas. Il ne clique pas. Il ne simule aucune interaction utilisateur.
Résultat : tout contenu qui nécessite un scroll pour être chargé — typiquement via des événements onScroll ou IntersectionObserver sans fallback — reste invisible. Google voit une page tronquée, pas votre contenu complet.
Pourquoi cette limitation persiste-t-elle alors que Google exécute JavaScript ?
L'exécution JavaScript par Google est réelle, mais conditionnée à ce que le code s'exécute automatiquement au chargement. Un script qui attend un déclencheur manuel (scroll, hover, clic) ne sera jamais activé.
C'est un choix technique et économique : simuler des interactions multiplie le temps de crawl et la consommation de ressources. Google privilégie l'efficacité — il scanne des milliards de pages chaque jour.
Quels types de contenu sont concernés par cette contrainte ?
Tout pattern d'interface qui masque du contenu derrière une action utilisateur est à risque. Les accordéons, les onglets non-préchargés, les boutons « Lire la suite », les grilles de produits en infinite scroll — autant de pièges potentiels.
Attention aussi aux images en lazy loading mal configurées : si l'attribut src est vide au chargement et rempli uniquement au scroll, Google peut rater vos visuels.
- Google ne déclenche aucun événement utilisateur (scroll, clic, hover)
- Le contenu masqué par ces mécanismes reste invisible au crawl
- Le lazy loading natif (
loading="lazy") est géré, mais les scripts custom au scroll ne le sont pas - Les accordéons et onglets doivent précharger leur contenu dans le DOM, même masqué visuellement
- Un contenu invisible à Googlebot = un contenu non indexable
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est documenté depuis des années. Les tests avec Search Console montrent systématiquement que le contenu chargé au scroll n'apparaît pas dans le rendu Googlebot. Aucune ambiguïté là-dessus.
Par contre — et c'est là que ça coince — Google a longtemps laissé entendre qu'il « comprenait » certains patterns UX modernes. Sauf qu'en pratique, il ne les supporte pas. Il y a un décalage entre les ambitions affichées (« nous exécutons JavaScript comme Chrome ») et la réalité (« mais sans aucune interaction »).
Dans quels cas peut-on quand même utiliser le lazy loading ?
Le lazy loading natif (loading="lazy" sur les balises <img>) est supporté par Google. Il détecte ces attributs et charge les images même si elles sont hors viewport. Pas de souci de ce côté.
Pour les images en JS custom, la règle est simple : l'attribut src doit être rempli dès le rendu initial. Si vous différez le chargement via un script au scroll, prévoyez un fallback SSR ou un prerender. Sinon, vous perdez vos images dans l'index.
Quelle nuance apporter concernant le contenu « caché » ?
Masquer visuellement du contenu avec CSS (display:none, visibility:hidden) tout en le laissant dans le DOM reste acceptable — Google crawle le HTML, pas le rendu visuel. C'est différent de masquer du contenu qui n'existe pas encore dans le DOM.
Exemple : un accordéon dont tous les panneaux sont présents dans le code source mais masqués par défaut ? Pas de problème. Un accordéon qui charge le contenu via AJAX au clic ? Perdu. [À vérifier] : Google affirme parfois détecter les « patterns d'interface courants » (accordéons, onglets) mais ne donne aucun détail technique sur ce qu'il considère comme « courant » ni comment il les traite réellement.
Impact pratique et recommandations
Que faut-il faire concrètement pour garantir l'indexation du contenu ?
Privilégiez le rendu côté serveur (SSR) ou le pre-rendering pour tout contenu critique. Si votre framework JavaScript (React, Vue, Next.js) permet le SSR, activez-le. Le HTML reçu par Googlebot doit contenir le contenu complet, pas un shell vide.
Pour les images, utilisez l'attribut natif loading="lazy" plutôt que des librairies JS custom. Si vous devez absolument utiliser un script, assurez-vous que l'attribut src est présent au chargement initial.
Comment vérifier que votre contenu est bien crawlable ?
Utilisez l'outil d'inspection d'URL dans Google Search Console. Comparez le code HTML source (« Afficher le code source crawlé ») avec le rendu final (« Tester l'URL en direct » puis « Afficher la page testée »). Si du contenu manque dans le rendu, c'est qu'il est masqué derrière une interaction.
Autre test simple : désactivez JavaScript dans votre navigateur. Ce qui disparaît est potentiellement invisible pour Googlebot — ou du moins retardé dans le pipeline de traitement.
Quelles erreurs éviter absolument ?
Ne cachez jamais du contenu essentiel (descriptions, spécifications produit, paragraphes de texte) derrière un bouton « Voir plus » qui charge en AJAX. Google ne cliquera pas.
Évitez l'infinite scroll sans pagination HTML alternative. Si votre liste de produits charge au fur et à mesure du scroll, prévoyez des liens <a href> vers des pages paginées crawlables. Google doit pouvoir accéder à tous les produits via des URLs classiques.
- Vérifiez le rendu Googlebot dans Search Console pour chaque template critique
- Assurez-vous que tout contenu important est présent dans le HTML initial (SSR ou prerender)
- Utilisez
loading="lazy"natif pour les images, pas de scripts custom au scroll - Si vous utilisez des accordéons ou onglets, préchargez le contenu dans le DOM (masqué en CSS si besoin)
- Fournissez des URLs paginées classiques en complément de l'infinite scroll
- Testez vos pages JavaScript désactivé — ce qui reste visible est ce que Google indexe en priorité
- Documentez les patterns UX à risque avec vos équipes front pour anticiper les impacts SEO
❓ Questions frequentes
Google peut-il indexer du contenu chargé en AJAX après un clic ?
Le lazy loading natif (loading="lazy") pose-t-il problème pour le SEO ?
Les accordéons nuisent-ils au référencement si le contenu est masqué en CSS ?
Comment savoir si Google voit tout mon contenu ?
L'infinite scroll est-il compatible avec le SEO ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 03/02/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.