Official statement
Other statements from this video 4 ▾
- □ Can you really pay Google to improve your crawl frequency or search rankings?
- □ Does content quality alone really guarantee a strong Google ranking?
- □ Is indexation really the mechanism by which Google understands your pages?
- □ Can page attributes really boost your visibility in Google search results?
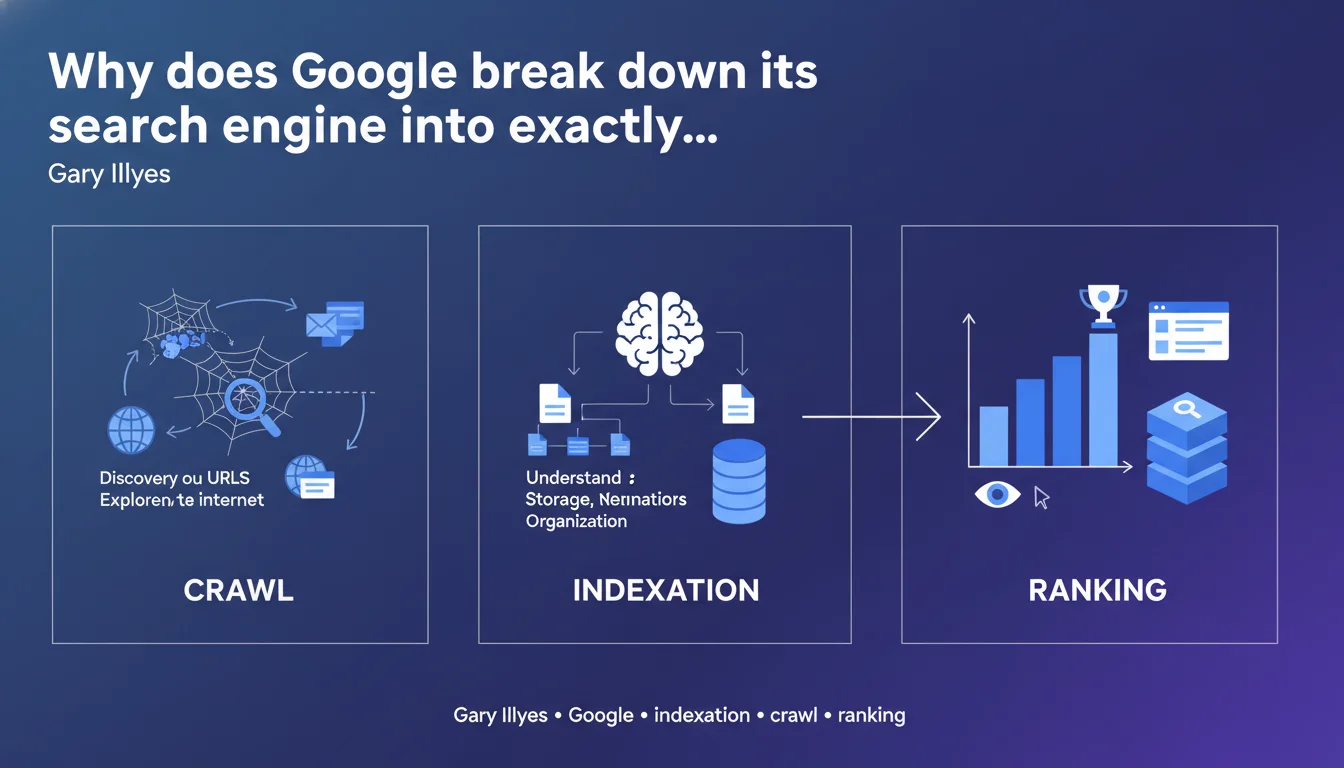
Google officially decomposes its search engine into three phases: crawl (discovery and exploration), indexation (analysis and storage), and ranking (display and classification). This separation is not trivial — it reflects the optimization levers to activate at each level to maximize organic visibility.
What you need to understand
Is this three-step division really as straightforward as it appears?
On paper, the framework is crystal clear: Google discovers your pages, analyzes and stores them, then ranks them for display. In reality, each step hides formidable technical complexity.
Crawl is not simply a visit — it depends on the budget allocated to your domain, the quality of your internal linking structure, server speed, freshness signals. Indexation is not binary: a page can be crawled without being indexed, or indexed partially. And ranking mobilizes several hundred signals weighted differently depending on queries.
What's the intention behind this official communication?
Google wants to simplify a system that, in reality, is not. This simplification aims to make Search's operations accessible to beginning webmasters, but it glosses over the critical nuances for a professional.
No mention here of filtering layers (spam, duplication, quality), index compression systems, or multiple parallel processing pipelines. The motor's operational reality is far more segmented.
How do these three steps concretely articulate with each other?
The boundaries are not as sharp as Gary Illyes suggests. Crawl can be influenced by signals from ranking (underperforming pages = reduced crawl). Indexation depends on qualitative criteria that borrow from ranking algorithms.
There exist feedback loops between the steps. A well-ranked page generates more clicks, which reinforces behavioral signals, which can modify crawl frequency. The linear model presented is a pedagogical mindset, not a technically faithful description.
- Crawl: discovery via sitemaps, internal/external links, redirects, server logs
- Indexation: HTML parsing, semantic extraction, thematic classification, compressed storage
- Ranking: multi-criteria scoring, personalization, filtering, SERP display
- Each step has its own bottlenecks and specific optimization levers
- The three phases are not hermetic — they communicate via cross-signals
SEO Expert opinion
Does this statement really reflect how things work in the field?
Yes and no. The three-phase breakdown is conceptually correct, but it masks gray areas that cause daily problems. For example: a page crawled but not indexed without explanation in Search Console, or a page indexed but invisible for certain relevant queries.
Edge cases are numerous. Pages with soft 404 status, content crawled via JavaScript but poorly interpreted, URLs force-canonicalized without apparent reason. The clean separation between phases doesn't hold when you audit thousands of real pages.
What are the practical limitations of this simplified model?
It completely omits pre-filtering systems. Before even indexation, Google applies anti-spam filters, duplicate content detection, quick quality assessments. A page can be crawled, judged "useless" in 200 ms, and never reach full indexation stage.
The model also ignores multiple indexes. Google doesn't have a single monolithic index, but several layers (primary index, secondary index, freshness index, mobile-first index). Saying "we index then we rank" is a misleading simplification. [To verify]: some pages appear indexed but never surface, probably confined to a second-tier index.
In which cases does this schema not fully apply?
Real-time content (news, events) follows an accelerated pipeline that partially bypasses standard indexation. High-authority sites benefit from near-instant crawling and prioritized indexation — the process is not the same for an average website.
Rich results (featured snippets, knowledge panels, carousels) mobilize third-party databases and structured extractions that don't go through traditional ranking. The "crawl > index > rank" schema describes only part of the Search ecosystem.
Practical impact and recommendations
How do you optimize each of these three steps specifically?
For crawl: control allocated budget by cleaning unnecessary URLs (facets, parameters, duplicates), optimize server speed, structure internal linking to push strategic pages, submit segmented XML sitemaps, monitor logs to identify ignored zones.
For indexation: work on semantic quality (unique, structured, rich content), implement canonical tags properly, avoid duplicate or thin content, ensure clean JavaScript rendering, verify meta robots and HTTP directives.
For ranking: strengthen authority (qualified backlinks), optimize UX signals (Core Web Vitals, click-through rate, time on page), align content with search intent, work on semantic relevance, test different formats (lists, FAQs, videos).
What frequent mistakes block one or another of these phases?
Crawl side: misconfigured robots.txt, too many chained redirects, orphaned pages without internal links, server response time > 500 ms, CSS/JS files blocked preventing full rendering.
Indexation side: unintentional noindex tags (inherited from dev environment), content too thin (< 300 words), massive duplication, forced canonicalization to wrong URL, undetected soft 404 pages.
Ranking side: mismatch intent (you optimize for "purchase" while Google ranks "informational"), catastrophic UX signals (80% immediate bounce), complete lack of backlinks, outdated content never updated.
How do you verify your site passes these three steps correctly?
- Analyze server logs to map Googlebot's actual behavior (frequency, depth, HTTP codes)
- Cross-reference Search Console (coverage, sitemaps) and Screaming Frog crawl to identify gaps between internal and Google crawl
- Verify real indexation through targeted "site:" queries and the URL inspection tool
- Test JavaScript rendering with Google's rich results tester to confirm what the engine actually sees
- Track positions and organic traffic by page type to detect unexplained visibility losses
- Measure Core Web Vitals in real conditions (CrUX) and fix threshold breaches
- Regularly audit backlinks to identify losses or toxic signals
❓ Frequently Asked Questions
Une page peut-elle être crawlée sans jamais être indexée ?
Le ranking influence-t-il le crawl et l'indexation en retour ?
Comment savoir à quelle étape mon problème se situe ?
Google utilise-t-il un seul index ou plusieurs ?
Pourquoi Google simplifie-t-il autant son fonctionnement dans ces communications ?
🎥 From the same video 4
Other SEO insights extracted from this same Google Search Central video · published on 15/02/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.