Declaration officielle
Autres déclarations de cette vidéo 4 ▾
- □ Peut-on vraiment payer Google pour améliorer son crawl ou son classement ?
- □ La qualité du contenu suffit-elle vraiment à garantir un bon positionnement Google ?
- □ L'indexation est-elle vraiment le mécanisme par lequel Google comprend vos pages ?
- □ Les attributs de page augmentent-ils vraiment la visibilité dans Google ?
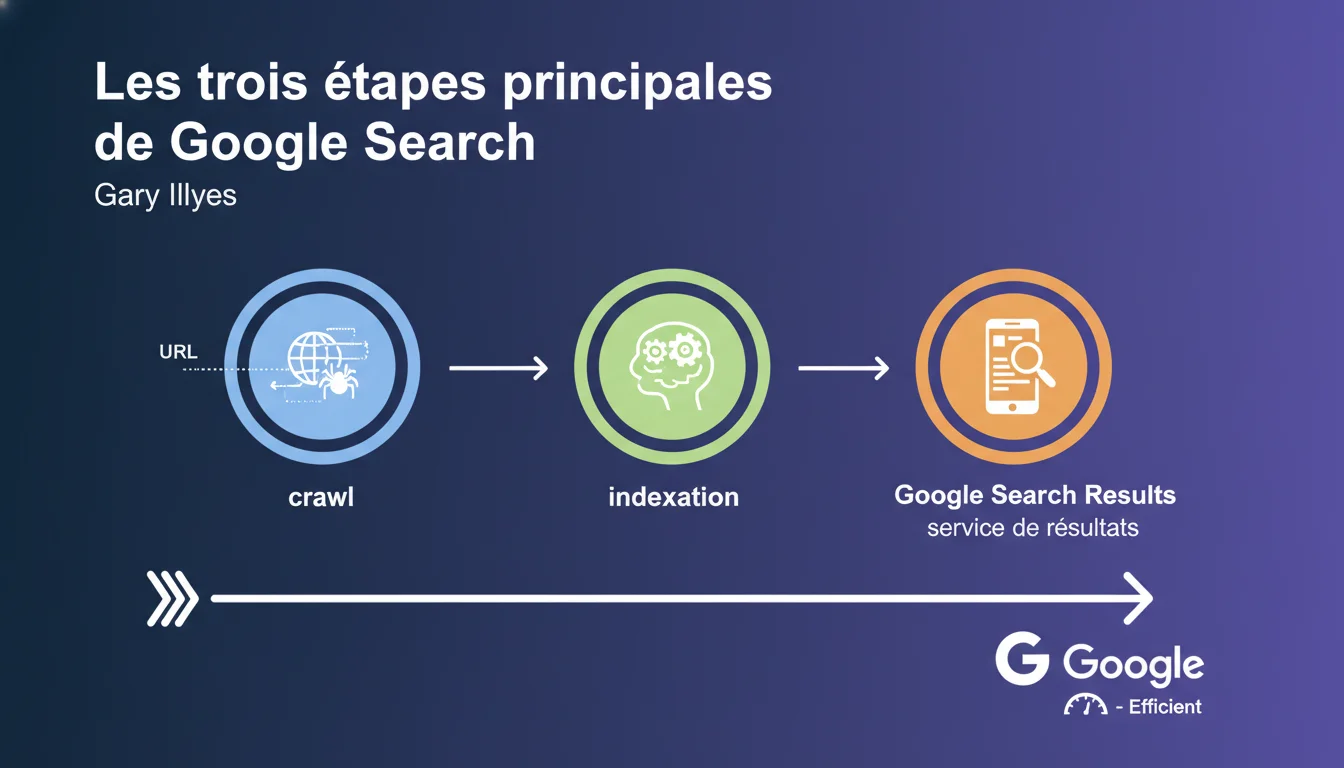
Google décompose officiellement son moteur de recherche en trois phases : crawl (découverte et exploration), indexation (analyse et stockage), et ranking (affichage et classement). Cette séparation n'est pas anodine — elle reflète les leviers d'optimisation à actionner à chaque niveau pour maximiser la visibilité organique.
Ce qu'il faut comprendre
Cette division en trois étapes est-elle vraiment aussi simple qu'elle en a l'air ?
Sur le papier, le schéma est limpide : Google découvre vos pages, les analyse et les stocke, puis les classe pour les afficher. Dans les faits, chaque étape cache une complexité technique redoutable.
Le crawl ne se résume pas à une simple visite — il dépend du budget alloué à votre domaine, de la qualité de votre maillage interne, de la vitesse serveur, des signaux de fraîcheur. L'indexation n'est pas binaire : une page peut être crawlée sans être indexée, ou indexée partiellement. Et le ranking mobilise plusieurs centaines de signaux pondérés différemment selon les requêtes.
Quelle est l'intention derrière cette communication officielle ?
Google veut simplifier un système qui, en réalité, ne l'est pas. Cette vulgarisation vise à rendre accessible le fonctionnement de Search aux webmasters débutants, mais elle gomme les nuances critiques pour un professionnel.
Aucune mention ici des couches de filtrage (spam, duplication, qualité), des systèmes de compression d'index, ou des multiples pipelines de traitement parallèles. La réalité opérationnelle du moteur est autrement plus segmentée.
Comment ces trois étapes s'articulent-elles concrètement entre elles ?
Les frontières ne sont pas aussi nettes que le suggère Gary Illyes. Le crawl peut être influencé par des signaux issus du ranking (pages peu performantes = crawl réduit). L'indexation dépend de critères qualitatifs qui empruntent aux algorithmes de classement.
Il existe des boucles de rétroaction entre les étapes. Une page bien classée génère plus de clics, ce qui renforce les signaux comportementaux, ce qui peut modifier la fréquence de crawl. Le modèle linéaire présenté est une vue d'esprit pédagogique, pas une description technique fidèle.
- Le crawl : découverte via sitemaps, liens internes/externes, redirections, logs serveur
- L'indexation : parsing HTML, extraction sémantique, classification thématique, stockage compressé
- Le ranking : scoring multi-critères, personnalisation, filtrage, affichage SERP
- Chaque étape possède ses propres goulots d'étranglement et leviers d'optimisation spécifiques
- Les trois phases ne sont pas hermétiques — elles communiquent via des signaux croisés
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment le fonctionnement observé sur le terrain ?
Oui et non. Le découpage en trois phases est conceptuellement exact, mais il masque les zones grises qui posent problème au quotidien. Par exemple : une page crawlée mais non indexée sans explication dans la Search Console, ou une page indexée mais invisible pour certaines requêtes pourtant pertinentes.
Les cas limites sont nombreux. Pages en soft 404, contenus crawlés via JavaScript mais mal interprétés, URLs canonicalisées de force sans raison apparente. La séparation nette entre les étapes ne tient pas quand on audite des milliers de pages réelles.
Quelles sont les limites pratiques de ce modèle simplifié ?
Il omet complètement les systèmes de pré-filtrage. Avant même l'indexation, Google applique des filtres anti-spam, des détections de contenu dupliqué, des évaluations qualitatives rapides. Une page peut être crawlée, jugée « inutile » en 200 ms, et jamais atteindre l'étape d'indexation complète.
Le modèle ignore aussi les index multiples. Google ne possède pas un seul index monolithique, mais plusieurs couches (index principal, index secondaire, index freshness, index mobile-first). Dire « on indexe puis on classe » est une simplification trompeuse. [À vérifier] : certaines pages semblent indexées mais ne remontent jamais, probablement cantonnées à un index de second rang.
Dans quels cas ce schéma ne s'applique-t-il pas totalement ?
Les contenus temps réel (actualités, événements) suivent un pipeline accéléré qui court-circuite partiellement l'indexation classique. Les sites à très forte autorité bénéficient d'un crawl quasi-instantané et d'une indexation prioritaire — le processus n'est pas le même pour un site lambda.
Les résultats enrichis (featured snippets, knowledge panels, carrousels) mobilisent des bases de données tierces et des extractions structurées qui ne passent pas par le ranking traditionnel. Le schéma « crawl > index > rank » ne décrit qu'une partie de l'écosystème Search.
Impact pratique et recommandations
Comment optimiser spécifiquement chacune de ces trois étapes ?
Pour le crawl : contrôlez le budget alloué en nettoyant les URLs inutiles (facettes, paramètres, doublons), optimisez la vitesse serveur, structurez le maillage interne pour pousser les pages stratégiques, soumettez des sitemaps XML segmentés, surveillez les logs pour identifier les zones ignorées.
Pour l'indexation : travaillez la qualité sémantique (contenu unique, structuré, riche), implémentez les balises canoniques proprement, évitez le contenu dupliqué ou trop fin, assurez-vous que le rendu JavaScript est propre, vérifiez les meta robots et les directives HTTP.
Pour le ranking : renforcez l'autorité (backlinks qualifiés), optimisez les signaux UX (Core Web Vitals, taux de clic, temps de visite), alignez le contenu sur l'intention de recherche, travaillez la pertinence sémantique, testez différents formats (listes, FAQ, vidéos).
Quelles erreurs fréquentes bloquent l'une ou l'autre de ces phases ?
Côté crawl : robots.txt mal configuré, trop de redirections en chaîne, pages orphelines sans liens internes, temps de réponse serveur > 500 ms, fichiers CSS/JS bloqués empêchant le rendu complet.
Côté indexation : balises noindex involontaires (héritées d'un environnement de dev), contenu trop léger (< 300 mots), duplication massive, canonicalisation forcée vers une mauvaise URL, pages en soft 404 non détectées.
Côté ranking : intention mal ciblée (vous optimisez pour « achat » alors que Google classe du « info »), signaux UX catastrophiques (80% de rebond immédiat), absence totale de backlinks, contenu obsolète jamais mis à jour.
Comment vérifier que votre site passe correctement ces trois étapes ?
- Analysez les logs serveur pour cartographier le comportement réel de Googlebot (fréquence, profondeur, codes HTTP)
- Croisez Search Console (couverture, sitemaps) et un crawl Screaming Frog pour identifier les écarts entre crawl interne et crawl Google
- Vérifiez l'indexation réelle via des requêtes « site: » ciblées et l'outil d'inspection d'URL
- Testez le rendu JavaScript avec le testeur d'URL enrichie de Google pour confirmer ce que voit réellement le moteur
- Suivez les positions et le trafic organique par typologie de page pour détecter les pertes de visibilité inexpliquées
- Mesurez les Core Web Vitals en conditions réelles (CrUX) et corrigez les dépassements de seuils
- Auditez régulièrement les backlinks pour identifier les pertes ou les signaux toxiques
❓ Questions frequentes
Une page peut-elle être crawlée sans jamais être indexée ?
Le ranking influence-t-il le crawl et l'indexation en retour ?
Comment savoir à quelle étape mon problème se situe ?
Google utilise-t-il un seul index ou plusieurs ?
Pourquoi Google simplifie-t-il autant son fonctionnement dans ces communications ?
🎥 De la même vidéo 4
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 15/02/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.