Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Les noms de classes CSS ont-ils un impact sur votre référencement naturel ?
- □ Pourquoi Google exige-t-il que vos fichiers CSS soient crawlables ?
- □ Le contenu CSS ::before et ::after est-il vraiment invisible pour Google ?
- □ Pourquoi Google ignore-t-il les hashtags ajoutés en CSS ::before ?
- □ Pourquoi vos images en background CSS ne sont-elles jamais indexées par Google Images ?
- □ Pourquoi séparer strictement HTML et CSS peut-il sauver votre indexation ?
- □ Le 100vh pose-t-il vraiment un problème d'indexation pour vos images hero ?
- □ Pourquoi Google exige-t-il des balises <img> pour les images de stock ?
- □ Le CSS peut-il nuire au SEO comme JavaScript ?
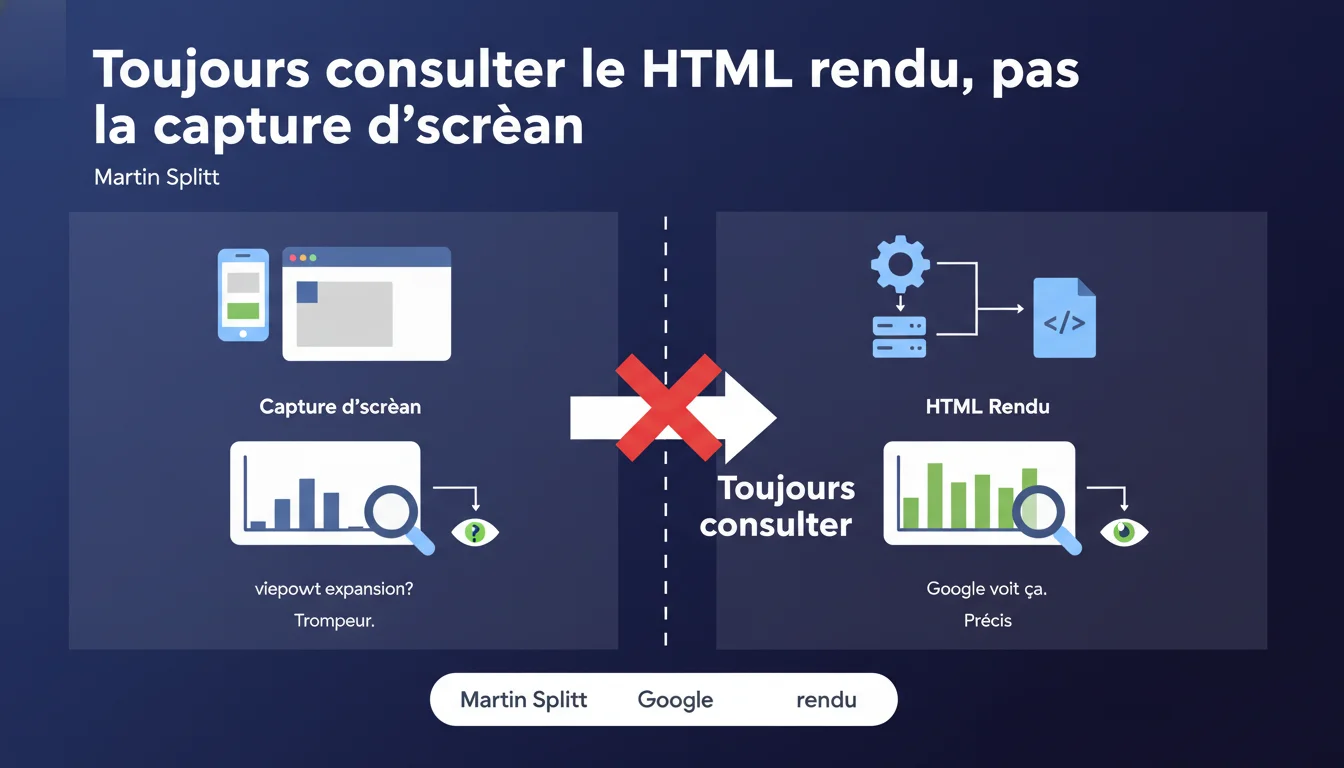
Google utilise une technique appelée viewport expansion qui rend ses captures d'écran potentiellement trompeuses. Pour vérifier réellement comment Googlebot interprète une page, il faut systématiquement consulter le HTML rendu via l'outil d'inspection d'URL, pas se fier à l'aperçu visuel.
Ce qu'il faut comprendre
Qu'est-ce que le viewport expansion et pourquoi Google l'utilise-t-il ?
Le viewport expansion est une technique utilisée par Google pour capturer des pages dans un format visuel étendu. Concrètement, le moteur génère des captures d'écran qui montrent parfois plus de contenu que ce que le crawler voit réellement lors de l'indexation.
Cette divergence crée un problème : ce que vous observez dans la capture d'écran de Search Console ne correspond pas forcément à ce que Googlebot a effectivement interprété et indexé. Et c'est là que ça coince pour le diagnostic.
Quelle différence entre la capture d'écran et le HTML rendu ?
La capture d'écran est une représentation visuelle générée après coup, potentiellement modifiée par le viewport expansion. Le HTML rendu, lui, est le code source exact tel que traité par le moteur d'indexation — incluant les modifications JavaScript post-chargement.
Quand vous diagnostiquez un problème d'indexation ou de rendu, c'est ce HTML rendu qui fait foi. La capture peut vous montrer un contenu parfaitement affiché alors que le crawler n'a pas pu y accéder correctement.
Dans quels cas cette confusion pose-t-elle problème ?
Les situations critiques concernent principalement les sites JavaScript-heavy où le contenu est injecté dynamiquement. Si vous vous fiez à la capture pour valider que Google voit vos contenus, vous risquez de passer à côté de balises manquantes, de contenus non rendus ou de structures HTML mal interprétées.
Typiquement : un menu déroulant visible sur la capture mais absent du DOM final, des lazy-loaded images non détectées, ou des Schema.org injectés en JS qui ne passent pas.
- Le viewport expansion crée un décalage entre capture visuelle et réalité d'indexation
- Le HTML rendu est la seule source fiable pour diagnostiquer comment Google interprète une page
- Les sites JavaScript sont particulièrement exposés à cette confusion
- La capture d'écran peut montrer du contenu que le crawler n'a jamais vu
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même un point que beaucoup de SEO sous-estiment. On voit régulièrement des diagnostics foireux parce que quelqu'un s'est contenté de vérifier la capture. Le problème, c'est que Google ne communique pas assez clairement sur cette distinction — beaucoup d'utilisateurs de Search Console ignorent encore que la capture n'est pas fiable.
En pratique, les écarts sont rares sur des sites statiques classiques, mais deviennent critiques dès qu'on touche à du JavaScript moderne (React, Vue, Angular). Sur ces architectures, on observe régulièrement des différences entre ce que montre la capture et ce qui apparaît dans le HTML rendu.
Quelles nuances faut-il apporter ?
Première nuance : tous les éléments visuels ne sont pas nécessairement cruciaux pour le référencement. Un décalage sur une image décorative ou un élément UI n'impacte pas forcément l'indexation du contenu textuel principal. Soyons honnêtes — il faut prioriser.
Deuxième point : le HTML rendu lui-même a ses limites. Il capture un état à un instant T, mais ne reflète pas toujours les interactions utilisateur ou les variations de contenu selon le contexte. [À vérifier] : Google ne précise pas si ce HTML rendu correspond au premier passage du crawler ou à un état ultérieur après re-crawl.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre site est 100% statique (HTML pur sans JavaScript), la distinction capture/HTML rendu a peu d'importance — les deux devraient être quasi identiques. C'est aussi vrai pour du WordPress classique avec peu de personnalisations JS.
Impact pratique et recommandations
Que faut-il faire concrètement pour vérifier le rendu côté Google ?
Utilisez systématiquement l'outil d'inspection d'URL de Google Search Console, puis cliquez sur "Afficher la page explorée" et sélectionnez l'onglet HTML. C'est ce code qui compte, pas l'aperçu visuel.
Comparez ce HTML rendu avec votre code source initial pour identifier ce qui a été modifié par JavaScript. Les différences vous indiquent exactement ce que Google indexe — ou pas.
Quelles erreurs éviter lors du diagnostic ?
Ne jamais se contenter de la capture d'écran pour valider qu'un contenu est bien crawlé. C'est l'erreur classique qui fait perdre des heures en diagnostic fantôme.
Évitez aussi de supposer que "si ça s'affiche dans mon navigateur, Google le voit". Le rendu côté Googlebot peut différer — timeouts JavaScript, ressources bloquées par robots.txt, exécution incomplète. Testez, ne supposez pas.
Comment intégrer cette vérification dans vos audits SEO ?
Intégrez le contrôle du HTML rendu dans votre checklist d'audit systématique, particulièrement sur les pages stratégiques (homepage, catégories principales, fiches produits phares). Documentez les écarts observés entre source et rendu.
- Toujours vérifier le HTML rendu via l'outil d'inspection d'URL de Search Console
- Comparer le code source initial et le HTML rendu pour identifier les transformations JavaScript
- Prioriser les pages stratégiques dans vos vérifications (homepage, catégories, produits phares)
- Documenter systématiquement les écarts entre capture et HTML rendu
- Ne jamais diagnostiquer un problème d'indexation sans consulter le HTML rendu
- Vérifier que les balises Schema.org injectées en JS apparaissent bien dans le rendu final
❓ Questions frequentes
Pourquoi Google ne montre-t-il pas directement le HTML rendu au lieu de la capture ?
Le viewport expansion affecte-t-il l'indexation ou seulement l'affichage de la capture ?
Faut-il vérifier le HTML rendu sur toutes les pages de mon site ?
Comment savoir si mon site est concerné par des problèmes de rendu JavaScript ?
Le HTML rendu dans Search Console correspond-il exactement à ce que voit Googlebot au moment de l'indexation ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 24/07/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.