Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Les noms de classes CSS ont-ils un impact sur votre référencement naturel ?
- □ Pourquoi Google exige-t-il que vos fichiers CSS soient crawlables ?
- □ Le contenu CSS ::before et ::after est-il vraiment invisible pour Google ?
- □ Pourquoi Google ignore-t-il les hashtags ajoutés en CSS ::before ?
- □ Pourquoi vos images en background CSS ne sont-elles jamais indexées par Google Images ?
- □ Le 100vh pose-t-il vraiment un problème d'indexation pour vos images hero ?
- □ Pourquoi la capture d'écran de Google Search Console peut-elle vous induire en erreur ?
- □ Pourquoi Google exige-t-il des balises <img> pour les images de stock ?
- □ Le CSS peut-il nuire au SEO comme JavaScript ?
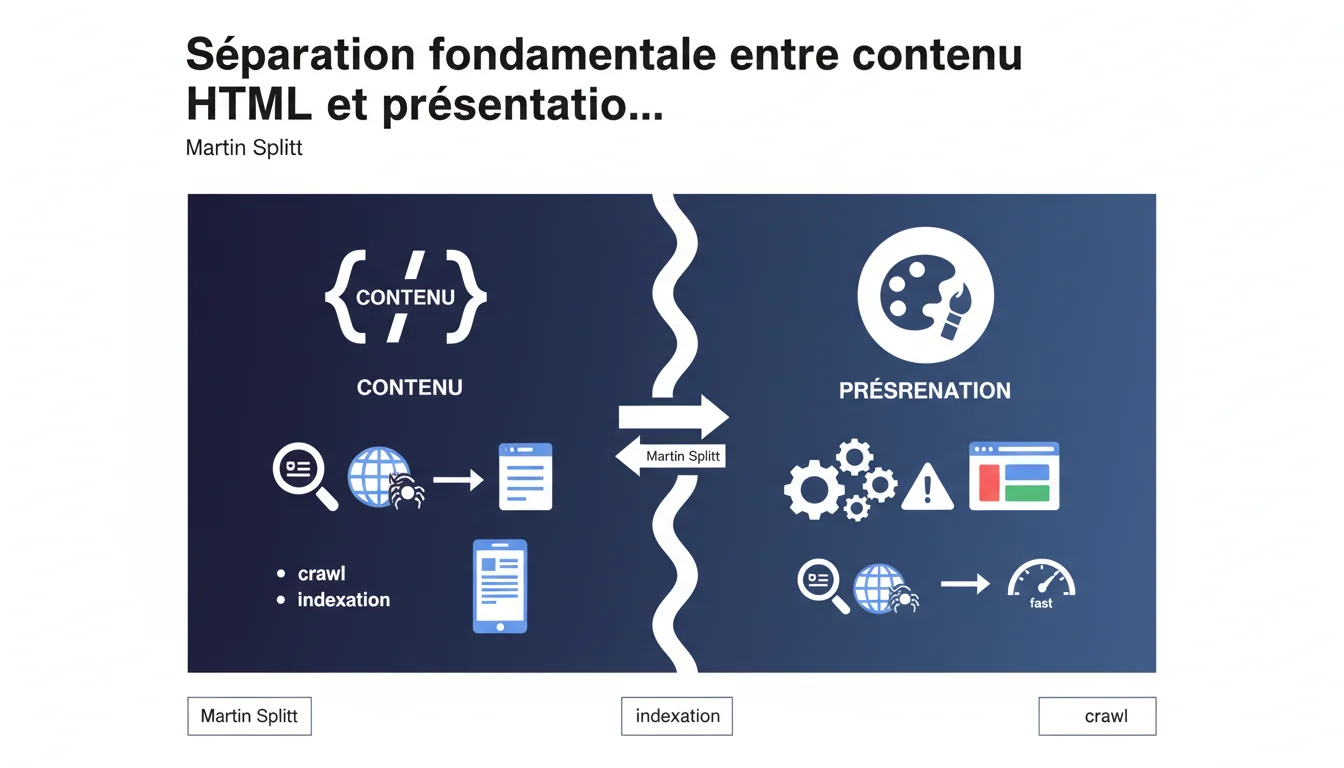
Google rappelle un principe fondamental souvent négligé : le contenu doit être dans le HTML, la présentation dans le CSS. Les crawlers et outils d'accessibilité parsent uniquement le HTML pour extraire le contenu. Utiliser du CSS pour injecter du contenu (via ::before, ::after, ou content) peut empêcher l'indexation correcte de vos pages.
Ce qu'il faut comprendre
Que signifie vraiment cette séparation HTML/CSS pour Googlebot ?
Googlebot lit le HTML, pas le CSS. Il extrait le contenu depuis les balises HTML standard : paragraphes, titres, listes, tableaux. Le CSS sert à mettre en forme ce contenu, à définir couleurs, positions, espacements.
Quand vous injectez du texte via CSS (propriété content, pseudo-éléments ::before ou ::after), ce texte n'existe pas dans le DOM HTML. Googlebot ne le voit pas. Les lecteurs d'écran non plus — ce qui crée aussi un problème d'accessibilité.
Pourquoi ce principe est-il si souvent violé ?
Les développeurs utilisent parfois le CSS pour ajouter des icônes, des labels, des mentions textuelles sans modifier le HTML. C'est pratique pour la maintenance, mais ça contourne la séparation fondamentale.
Résultat : des éléments visuellement présents sur la page mais invisibles pour les crawlers. Un titre complété par une mention « Nouveau » en CSS ? Google ne la verra jamais.
Quelles sont les conséquences concrètes sur l'indexation ?
Si du contenu essentiel est injecté via CSS — un titre complet, une description de produit, un CTA important — il ne sera pas indexé. La page semblera incomplète ou moins pertinente pour Google.
Les outils d'accessibilité rencontrent le même problème. Une page inaccessible envoie un signal négatif pour le référencement.
- Le contenu doit être dans le HTML : paragraphes, titres, listes, liens.
- Le CSS sert uniquement à la présentation : couleurs, espacements, typographie.
- Éviter d'injecter du texte via content, ::before, ::after si ce texte a une valeur sémantique.
- Impact double : indexation ET accessibilité compromises.
Avis d'un expert SEO
Cette règle est-elle toujours respectée par Google lui-même ?
Soyons honnêtes : Google a évolué. Googlebot exécute le JavaScript, rend le CSS, comprend certains contenus dynamiques. Mais il reste un principe : le HTML est le socle de référence.
Les cas limites existent. Des tests montrent que certains pseudo-éléments CSS peuvent être rendus dans le cache Google. Mais ce n'est pas garanti — et ça reste fragile. [À vérifier] selon les versions du crawler et les configurations serveur.
Quand cette séparation devient-elle un vrai problème ?
Le problème surgit quand du contenu sémantiquement important est injecté via CSS. Un label « Promo », une icône décorative, un séparateur visuel ? Pas critique. Un titre complet, une description de produit, un CTA principal ? Là, ça coince.
En pratique, on voit souvent des sites e-commerce qui ajoutent des badges (« Nouveau », « -20% ») via CSS. Si ces badges complètent un titre de produit, Google indexe une version incomplète.
Cette directive est-elle cohérente avec les pratiques observées ?
Oui. Les audits terrain confirment : les pages qui respectent la séparation HTML/CSS s'indexent mieux et plus rapidement. Les crawlers n'ont pas à interpréter du CSS complexe.
Attention toutefois : cette règle n'excuse pas un HTML surchargé. Un HTML propre et structuré reste la base, mais bourrer le HTML de contenu inutile pour « faire du SEO » reste une mauvaise pratique.
Impact pratique et recommandations
Comment vérifier que votre site respecte cette séparation ?
Première étape : désactiver le CSS dans votre navigateur. Le contenu reste-t-il compréhensible ? Les titres, descriptions, CTA sont-ils tous visibles ? Si non, vous avez un problème.
Deuxième étape : utiliser l'outil d'inspection de Google Search Console. Comparez le rendu HTML et le rendu visuel. Les éléments injectés via CSS apparaissent-ils dans le HTML récupéré par Googlebot ?
Quelles erreurs éviter absolument ?
Ne jamais utiliser content dans le CSS pour du texte sémantique. Réservez-le aux éléments purement décoratifs (icônes, séparateurs visuels).
Évitez les titres ou descriptions complétés par ::before ou ::after. Si un élément textuel a du sens pour l'utilisateur, il doit être dans le HTML.
Attention aux frameworks CSS qui génèrent du contenu automatiquement. Vérifiez leur sortie HTML finale.
Que faut-il faire concrètement ?
- Auditer les pages clés pour repérer les contenus injectés via CSS
- Migrer tout texte sémantique (titres, descriptions, CTA) vers le HTML
- Utiliser le CSS uniquement pour la présentation visuelle
- Tester l'accessibilité avec un lecteur d'écran (NVDA, VoiceOver)
- Valider le HTML récupéré par Googlebot via Search Console
- Former les développeurs à ce principe fondamental
❓ Questions frequentes
Google indexe-t-il vraiment ZÉRO contenu injecté via CSS ?
Les pseudo-éléments ::before et ::after sont-ils toujours problématiques ?
Comment savoir si mon contenu CSS pose problème pour l'indexation ?
Cette règle s'applique-t-elle aussi aux images de fond CSS ?
Pourquoi cette séparation impacte-t-elle aussi l'accessibilité ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 24/07/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.