Declaration officielle
Ce qu'il faut comprendre
Quelle est la position officielle de Google sur les serveurs indisponibles ?
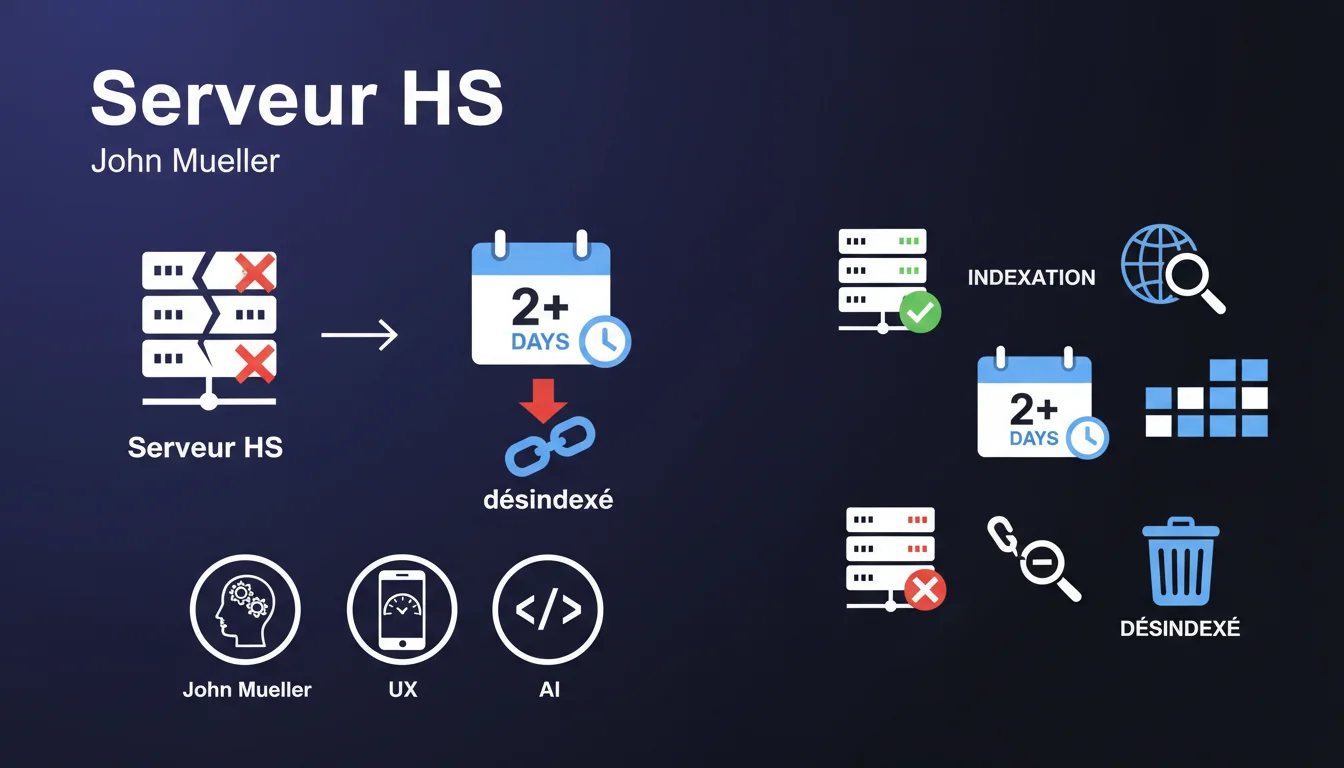
Google a clarifié sa politique concernant les sites web inaccessibles pour cause de serveur défaillant. Selon cette déclaration officielle, un site peut être désindexé si l'indisponibilité dure plusieurs jours, précisément au-delà de deux jours consécutifs.
Cette position marque une évolution importante dans la manière dont Google traite les erreurs serveur prolongées. Le moteur de recherche ne se contente plus d'attendre indéfiniment qu'un site redevienne accessible.
Pourquoi cette limite de deux jours est-elle critique ?
Google crawle le web en permanence et alloue un budget de crawl à chaque site. Lorsqu'un serveur est indisponible, Googlebot rencontre des erreurs répétées qui consomment ce budget sans résultat.
Au-delà de 48 heures d'indisponibilité, Google interprète cette situation comme un problème structurel majeur plutôt qu'un incident temporaire. Le moteur prend alors la décision de retirer les pages de son index pour éviter de proposer des résultats inaccessibles aux utilisateurs.
Comment le code HTTP 503 peut-il protéger votre indexation ?
Le code de statut HTTP 503 (Service Unavailable) joue un rôle crucial dans cette équation. Il indique explicitement aux moteurs de recherche qu'il s'agit d'une maintenance temporaire et non d'une disparition définitive.
Lorsque Google reçoit un code 503, il comprend que l'indisponibilité est planifiée ou accidentelle mais temporaire. Cela lui permet d'adapter son comportement et de préserver l'indexation pendant la période d'interruption.
- Seuil critique : Désindexation possible après 2 jours d'indisponibilité continue
- Code 503 obligatoire : Indispensable pour signaler une maintenance temporaire aux moteurs
- Budget de crawl : Les erreurs répétées épuisent rapidement votre quota d'exploration
- Réindexation possible : Le retour à la normale peut être relativement rapide une fois le serveur rétabli
- Impact utilisateur : Google privilégie l'expérience de recherche en retirant les sites inaccessibles
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Cette position de Google correspond effectivement aux observations des professionnels SEO depuis plusieurs années. Les cas de désindexation rapide suite à des pannes serveur prolongées sont documentés et récurrents.
Cependant, la notion de "quelques jours" reste volontairement floue et contextuelle. En pratique, certains sites à forte autorité ou avec un historique stable peuvent bénéficier d'une tolérance légèrement supérieure, tandis que des sites récents ou moins établis risquent une désindexation plus rapide.
Quelles nuances faut-il apporter à cette règle des deux jours ?
Le délai de deux jours n'est pas une limite absolue mais plutôt un seuil indicatif. Plusieurs facteurs influencent la décision de Google : la fréquence habituelle de crawl du site, son autorité globale, et la nature des erreurs rencontrées.
Il faut également distinguer les pannes totales des ralentissements. Un serveur qui répond lentement (timeouts fréquents) sans être complètement HS peut également subir des pénalités d'indexation, mais selon une logique différente liée au Core Web Vitals et à l'expérience utilisateur.
Dans quels cas le retour à la normale est-il vraiment rapide ?
La déclaration mentionne que la réindexation peut être plus rapide après rétablissement. Cette affirmation doit être nuancée : elle concerne principalement les sites avec un bon historique et une infrastructure solide habituellement.
Dans la réalité, si votre site a été complètement désindexé, le processus de réindexation complète peut prendre plusieurs jours à plusieurs semaines selon la taille du site. Google ne réindexe pas instantanément toutes les pages dès que le serveur redevient accessible, il reprend son crawl progressivement.
Impact pratique et recommandations
Que faut-il mettre en place immédiatement pour se protéger ?
La première action critique consiste à configurer un système de monitoring serveur robuste avec alertes en temps réel. Vous devez être prévenu dans les 5 minutes suivant une indisponibilité, pas après plusieurs heures.
Ensuite, assurez-vous que votre infrastructure est capable de servir automatiquement un code 503 en cas de maintenance planifiée ou de détection d'une défaillance. Cette configuration doit être testée régulièrement, idéalement tous les trimestres.
Enfin, établissez un plan de reprise d'activité documenté avec des procédures claires et des responsables identifiés. Le temps de réaction est crucial : chaque heure compte lorsque votre site est inaccessible.
Quelles erreurs critiques faut-il absolument éviter ?
L'erreur la plus fréquente est de laisser le serveur renvoyer des codes 500 ou des timeouts sans action corrective. Ces erreurs sont interprétées plus négativement qu'un code 503 bien configuré.
Autre piège : utiliser une page de maintenance en JavaScript qui renvoie un code 200. Google crawle principalement le HTML brut et considérera la page comme accessible alors qu'elle ne l'est pas réellement pour les utilisateurs sans JavaScript.
Ne négligez jamais la communication vers Google Search Console. Si une panne survient, documentez-la et surveillez les rapports de couverture pour détecter rapidement tout problème d'indexation.
Comment vérifier et maintenir la conformité de votre infrastructure ?
Mettez en place des tests automatisés réguliers qui simulent des indisponibilités et vérifient que les codes HTTP corrects sont bien renvoyés. Ces tests doivent couvrir différents scénarios : panne serveur, maintenance planifiée, surcharge temporaire.
Auditez votre infrastructure d'hébergement au minimum trimestriellement : vérifiez les SLA de votre hébergeur, testez vos sauvegardes, et assurez-vous que vos procédures de basculement fonctionnent réellement.
- Configurer un monitoring avec alertes instantanées (SMS/email) pour toute indisponibilité
- Implémenter le renvoi automatique du code HTTP 503 en cas de maintenance ou panne détectée
- Tester la configuration 503 tous les 3 mois minimum en environnement de staging
- Documenter un plan de reprise d'activité avec objectif de remise en ligne sous 4 heures maximum
- Mettre en place des tests automatisés quotidiens de disponibilité serveur
- Vérifier que votre hébergeur garantit un uptime minimum de 99,9% dans son SLA
- Configurer des sauvegardes automatiques quotidiennes avec tests de restauration mensuels
- Surveiller Google Search Console hebdomadairement pour détecter les erreurs d'exploration
- Prévoir une infrastructure de basculement (failover) pour les sites critiques
- Former plusieurs membres de l'équipe aux procédures d'urgence serveur
💬 Commentaires (0)
Soyez le premier à commenter.