Declaration officielle
Ce qu'il faut comprendre
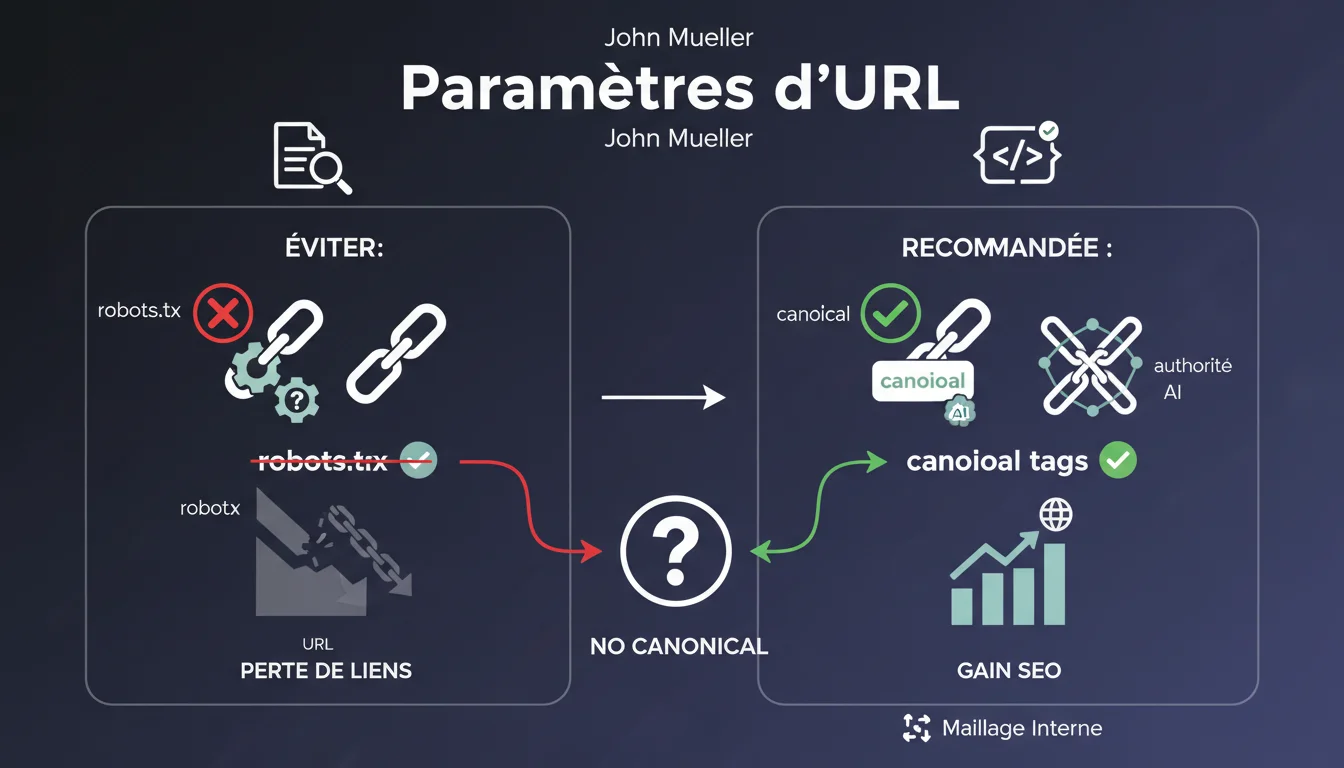
Pourquoi ne devrait-on pas bloquer les URLs à paramètres via robots.txt ?
Lorsqu'une URL à paramètres est bloquée dans le fichier robots.txt, Google ne peut pas la crawler. Le moteur ne peut donc pas découvrir les backlinks qui pointent vers cette URL.
Sans crawler ces pages, Google ne peut pas transférer la valeur SEO de ces liens vers la version canonique de la page. Vous perdez ainsi du jus de lien précieux que ces URLs paramétrées auraient pu transmettre.
Comment Google gère-t-il la canonicalisation des URLs à paramètres ?
Pour que Google puisse consolider les signaux de différentes versions d'une même page, il doit pouvoir crawler toutes ces versions. C'est seulement en les explorant qu'il peut identifier les balises canonical et comprendre quelle est la version principale.
Le processus de canonicalisation nécessite que Googlebot accède aux URLs alternatives pour détecter les directives canonical et transférer l'autorité des liens vers l'URL de référence.
Quelle est l'approche recommandée pour gérer ces URLs ?
La méthode préconisée combine l'utilisation de balises canonical et un maillage interne cohérent. Chaque URL à paramètres doit pointer vers sa version canonique via la balise rel=canonical.
Le maillage interne doit systématiquement privilégier les URLs sans paramètres dans les liens. Cette combinaison permet à Google de crawler les variantes tout en comprenant clairement la hiérarchie.
- Ne jamais bloquer dans robots.txt les URLs que vous souhaitez canonicaliser
- Implémenter des balises canonical sur toutes les versions paramétrées
- Créer un maillage interne pointant vers les URLs canoniques
- Laisser Google découvrir et consolider les signaux de toutes les variantes
Avis d'un expert SEO
Cette recommandation est-elle toujours applicable dans tous les contextes ?
La directive de John Mueller est techniquement correcte mais mérite d'être nuancée selon le contexte de chaque site. Sur un petit site avec peu de pages, elle s'applique parfaitement sans contrainte.
Cependant, sur des sites de grande envergure avec des millions d'URLs paramétrées (e-commerce, petites annonces, sites de filtres), cette approche peut devenir problématique. Le budget crawl devient alors une ressource critique à optimiser.
Quand le blocage robots.txt peut-il être justifié malgré tout ?
Dans certains cas, bloquer des URLs à paramètres reste la meilleure stratégie. Par exemple, pour des paramètres de tracking (utm_source, etc.) ou de session qui ne génèrent aucune valeur ajoutée et diluent le crawl.
Si vos URLs à paramètres ne reçoivent aucun backlink externe significatif, le risque de perte de jus est négligeable. L'analyse de votre profil de liens doit guider cette décision.
Comment arbitrer entre ces deux approches contradictoires ?
L'arbitrage doit se faire sur la base de données concrètes. Analysez vos logs serveur pour identifier quels paramètres consomment du budget crawl sans apporter de valeur.
Évaluez également le volume de backlinks pointant vers vos URLs paramétrées. Si ce volume est significatif, privilégiez la canonicalisation. Si ces URLs sont rarement liées mais massivement crawlées, le blocage sélectif peut être pertinent.
Impact pratique et recommandations
Que faut-il faire concrètement pour gérer efficacement ces URLs ?
Commencez par un audit complet de vos paramètres d'URL. Identifiez ceux qui créent du contenu dupliqué, ceux qui sont purement techniques, et ceux qui peuvent recevoir des backlinks.
Implémentez ensuite une stratégie différenciée : canonical pour les paramètres à valeur SEO (filtres produits, pagination), et blocage robots.txt pour les paramètres purement techniques (tracking, sessions).
Configurez Google Search Console pour indiquer comment traiter chaque type de paramètre. Cet outil permet de guider Google sur le comportement attendu sans bloquer le crawl.
Quelles erreurs éviter absolument dans cette gestion ?
Ne jamais bloquer dans robots.txt des URLs qui reçoivent des backlinks externes sans avoir d'abord vérifié leur volume et qualité. Vous perdriez définitivement cette autorité.
Évitez également de mélanger les signaux : une URL bloquée en robots.txt ne devrait pas avoir de balise canonical. C'est contradictoire et Google ne pourra pas la lire de toute façon.
Ne négligez pas le maillage interne. Même avec des canonicals parfaites, si vos liens internes pointent massivement vers les versions paramétrées, vous diluez vos signaux.
- Auditer l'ensemble de vos paramètres d'URL et leur utilisation
- Analyser les logs pour identifier les paramètres consommant du budget crawl
- Vérifier les backlinks pointant vers les URLs paramétrées
- Implémenter des balises canonical sur toutes les variantes à conserver
- Configurer robots.txt uniquement pour les paramètres sans valeur SEO
- Optimiser le maillage interne vers les URLs canoniques
- Utiliser Google Search Console pour guider le traitement des paramètres
- Monitorer régulièrement l'évolution du crawl dans vos logs serveur
💬 Commentaires (0)
Soyez le premier à commenter.