Declaration officielle
Ce qu'il faut comprendre
Quelle est la différence entre Noindex dans robots.txt et la balise meta noindex ?
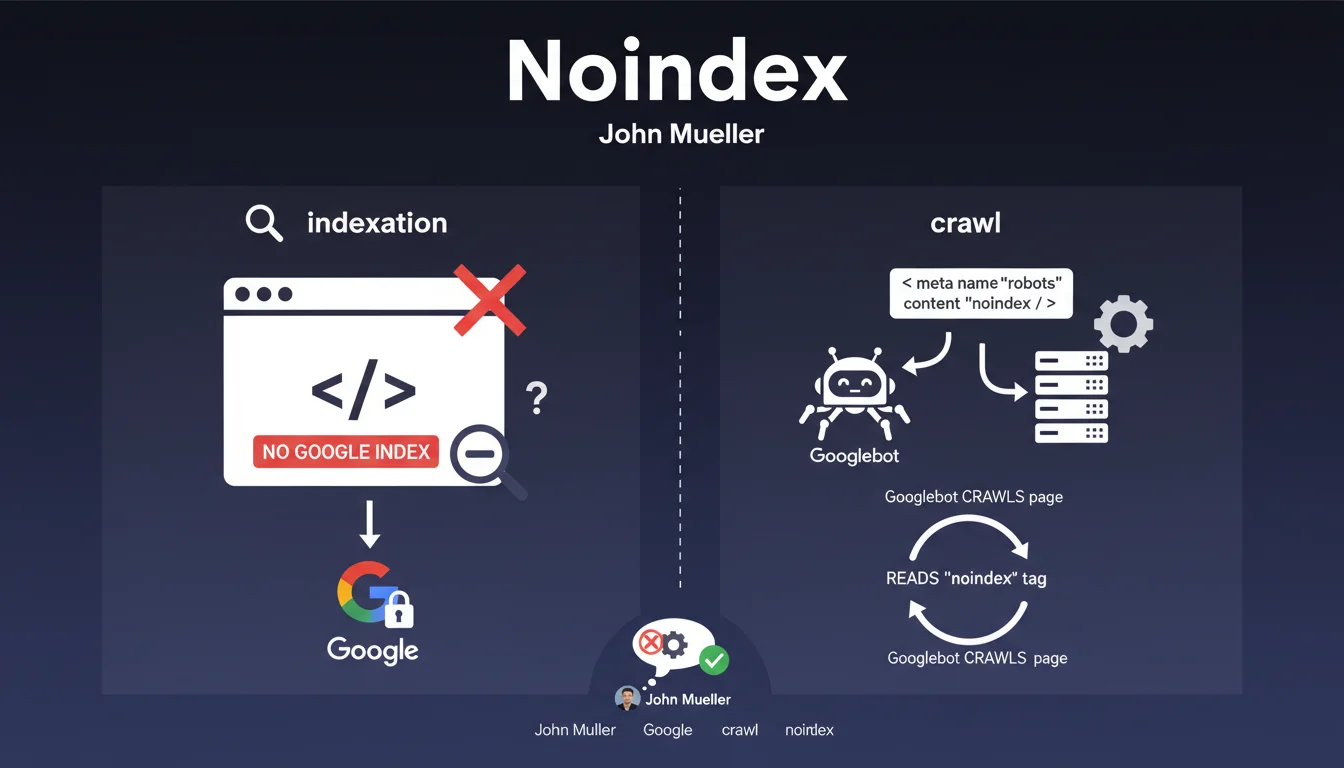
Il existe deux façons d'empêcher l'indexation d'une page : la balise meta noindex placée dans le code HTML de la page, et la directive Noindex: dans le fichier robots.txt. La première est la méthode officielle et recommandée par Google.
La directive Noindex: dans le robots.txt est une fonctionnalité non-documentée et non-maintenue par Google. Elle fonctionne actuellement, mais Google ne garantit absolument pas sa pérennité. C'est une syntaxe héritée du passé qui mélange deux concepts distincts.
- Le robots.txt est conçu pour gérer le crawl (exploration des pages)
- Les balises meta sont conçues pour gérer l'indexation (présence dans les résultats)
- La directive Noindex: dans robots.txt mélange ces deux fonctions, ce qui est conceptuellement incorrect
Pourquoi Google envisage-t-il de supprimer cette fonctionnalité ?
Gary Illyes a clairement exprimé que cette syntaxe n'est pas logique d'un point de vue architectural. Elle crée une confusion entre les outils de contrôle du crawl et ceux de contrôle de l'indexation.
Google privilégie une approche claire : chaque outil pour sa fonction spécifique. Le robots.txt bloque l'exploration, les balises meta contrôlent l'indexation. La suppression de cette directive pourrait intervenir à tout moment, sans préavis détaillé.
- La fonctionnalité pourrait disparaître sans avertissement préalable
- Google considère cette syntaxe comme un "marteau pour visser"
- Aucun engagement de maintien à moyen ou long terme
Quel est le risque immédiat pour les sites utilisant cette directive ?
Les sites qui s'appuient sur Noindex: dans leur robots.txt pour bloquer l'indexation de certaines pages prennent un risque opérationnel majeur. Si Google supprime cette fonctionnalité du jour au lendemain, ces pages pourraient soudainement être indexées.
Ce risque est particulièrement critique pour les pages sensibles, les contenus en double, les pages de test ou les sections privées. Une indexation non souhaitée pourrait avoir des conséquences SEO négatives immédiates.
- Indexation soudaine de contenus non destinés aux moteurs de recherche
- Pollution potentielle de l'index avec du contenu de faible qualité
- Risque de duplicate content si ces pages étaient volontairement exclues
Avis d'un expert SEO
Cette annonce est-elle cohérente avec l'évolution générale des outils pour webmasters ?
Absolument. Google suit depuis plusieurs années une stratégie de clarification et de simplification de ses directives. La suppression des fonctionnalités non-standard ou redondantes s'inscrit dans cette logique.
Nous avons déjà vu Google supprimer ou déprécier des syntaxes obsolètes au profit de standards clairs. Cette décision concernant Noindex: dans robots.txt est parfaitement cohérente avec cette approche. Google préfère maintenir moins de fonctionnalités, mais avec une documentation et un support de qualité.
Quelles sont les nuances importantes à considérer dans cette situation ?
Il faut distinguer les sites qui utilisent intentionnellement cette directive de ceux qui l'ont héritée d'anciennes configurations. Certains CMS ou plugins SEO obsolètes ont pu générer automatiquement cette syntaxe il y a quelques années.
La vraie question n'est pas tant "si" Google va supprimer cette fonctionnalité, mais "quand". Avec un risque estimé à 50% de suppression imminente, la prudence impose d'agir maintenant plutôt que d'attendre une mauvaise surprise.
Dans quels cas cette problématique est-elle particulièrement critique ?
Les sites de grande envergure avec des dizaines de milliers de pages sont les plus exposés. Identifier toutes les pages concernées par cette directive peut être complexe, et la migration vers des balises meta demande du temps.
Les sites e-commerce avec de nombreuses pages paramétrées, pages de filtres ou variations sont également à risque. Beaucoup utilisaient Noindex: dans robots.txt pour gérer massivement ces exclusions. La transition vers une gestion page par page via balises meta représente un chantier technique significatif.
Impact pratique et recommandations
Que faut-il faire concrètement dès maintenant ?
La première étape consiste à auditer votre fichier robots.txt pour détecter toute utilisation de la directive Noindex:. Téléchargez votre fichier et recherchez cette syntaxe spécifique.
Si vous l'utilisez, identifiez toutes les URLs concernées et préparez un plan de migration. L'objectif est de basculer vers des balises meta noindex dans le code HTML de chaque page concernée. Cette migration doit être testée en environnement de développement avant déploiement.
- Télécharger et analyser votre fichier robots.txt actuel
- Rechercher toute occurrence de "Noindex:" dans le fichier
- Lister toutes les URLs ou patterns d'URLs concernés
- Vérifier si votre CMS a généré automatiquement ces directives
- Documenter la raison initiale de ces exclusions d'indexation
Quelles erreurs faut-il absolument éviter lors de la migration ?
Ne supprimez jamais la directive Noindex: du robots.txt avant d'avoir implémenté les balises meta noindex correspondantes. Vous créeriez une fenêtre temporelle où les pages seraient indexables, ce qui pourrait polluer votre index.
Attention également à ne pas confondre Disallow et Noindex. Bloquer le crawl avec Disallow empêche Google de voir la balise meta noindex sur la page. Il faut autoriser le crawl pour que Google puisse lire et respecter la directive noindex dans le HTML.
- Ne jamais bloquer le crawl (Disallow) d'une page avec meta noindex
- Tester chaque modification en environnement de pré-production
- Vérifier que les balises meta sont bien présentes dans le code source
- Utiliser Google Search Console pour valider le bon fonctionnement
- Monitorer l'évolution de l'indexation après la migration
Comment vérifier que la transition est réussie et sécurisée ?
Utilisez Google Search Console pour tester votre robots.txt après suppression de la directive Noindex:. L'outil de test vous confirmera que le fichier est valide et fonctionnel sans cette syntaxe.
Effectuez ensuite une vérification avec l'outil Inspection d'URL pour chaque page concernée. Google doit indiquer "Page exclue par la balise noindex" et non "Bloquée par le robots.txt". C'est la confirmation que votre migration est correctement implémentée.
💬 Commentaires (0)
Soyez le premier à commenter.