Declaration officielle
Ce qu'il faut comprendre
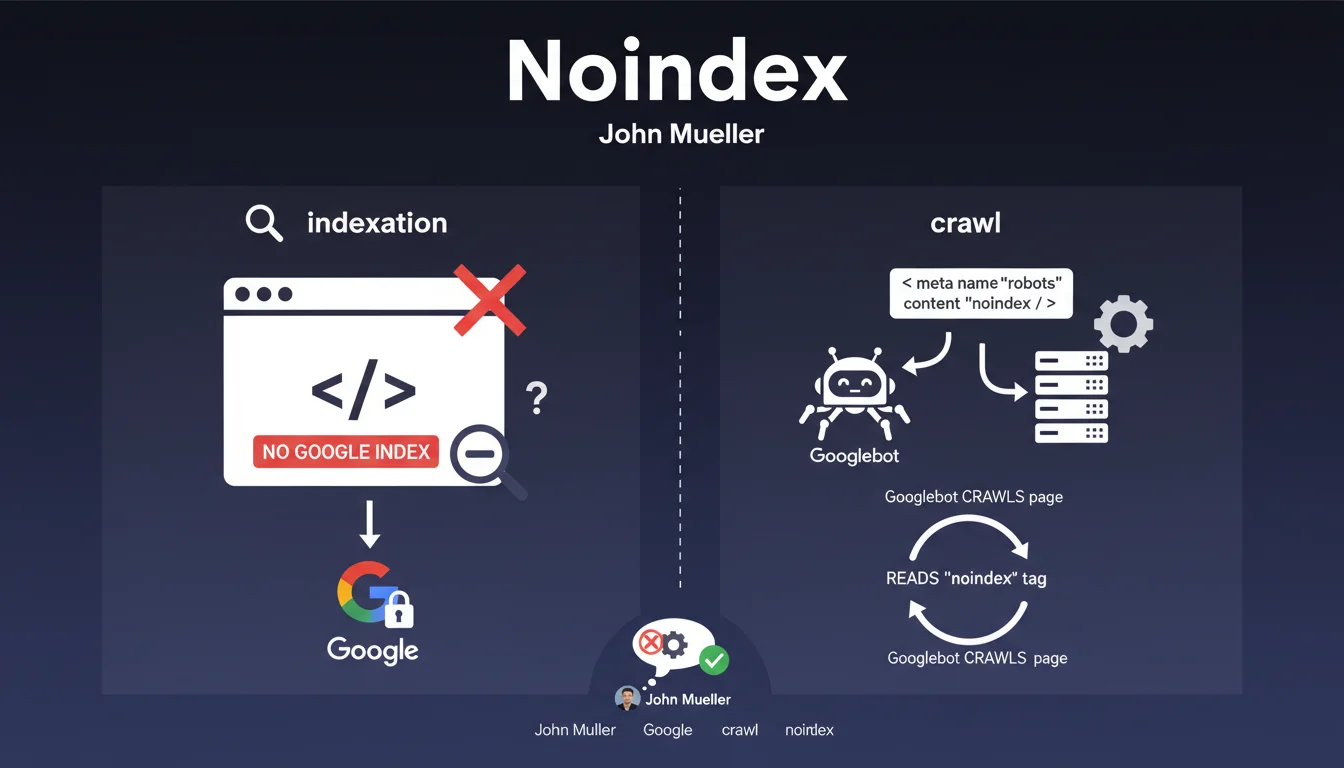
Quelle est la différence entre indexation et crawl ?
L'indexation désigne l'ajout d'une page dans l'index de Google, c'est-à-dire sa base de données des pages susceptibles d'apparaître dans les résultats de recherche. Le crawl, lui, correspond à la visite et l'exploration d'une page par Googlebot.
Cette distinction est fondamentale : le robot doit d'abord crawler la page pour découvrir et lire la balise meta robots noindex. Il ne peut donc pas savoir qu'il ne doit pas indexer une page sans l'avoir d'abord visitée.
Comment fonctionne réellement la balise noindex ?
La balise meta robots noindex indique à Google de ne pas inclure la page dans son index. Googlebot va visiter la page, lire les directives, puis exclure le contenu de ses résultats de recherche.
Cette balise est efficace pour gérer l'indexation, mais elle n'empêche absolument pas le crawl initial. Le robot continuera même à revisiter périodiquement ces pages noindexées pour vérifier si la directive est toujours présente.
Quelles sont les conséquences de cette confusion ?
Beaucoup de praticiens SEO croient à tort qu'ajouter du noindex permet d'économiser le budget crawl. C'est une erreur fréquente qui peut conduire à des décisions inappropriées dans la gestion technique d'un site.
- Le noindex contrôle l'indexation, pas le crawl
- Googlebot doit crawler une page pour lire la directive noindex
- Les pages noindexées continuent d'être crawlées périodiquement
- Le noindex n'optimise pas directement le budget crawl
- Pour contrôler le crawl, il faut utiliser d'autres méthodes (robots.txt, codes HTTP)
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Absolument. Les analyses de logs serveur confirment systématiquement ce constat : les pages marquées noindex continuent de recevoir des visites régulières de Googlebot. La fréquence peut même rester élevée si ces pages bénéficient de liens internes.
J'observe régulièrement que des sites ajoutent massivement du noindex en pensant réduire leur charge serveur ou optimiser leur crawl. Résultat : aucun impact positif sur le budget crawl, mais une perte de visibilité si des pages stratégiques ont été noindexées par erreur.
Quelles sont les vraies solutions pour contrôler le crawl ?
Si votre objectif est réellement de limiter le crawl de certaines pages, plusieurs outils sont à votre disposition. Le fichier robots.txt permet de bloquer l'accès à des sections entières, mais attention : les URL peuvent rester indexées si elles reçoivent des liens externes.
Les codes HTTP comme le 410 (Gone) ou le 404 sont plus radicaux et indiquent que la ressource n'existe plus. Pour les pages à faible valeur, supprimer les liens internes qui y pointent réduit naturellement leur crawl sans directive explicite.
Dans quels cas la balise noindex reste-t-elle pertinente ?
Le noindex demeure l'outil approprié pour les contenus de faible qualité que vous souhaitez conserver accessibles aux utilisateurs mais exclure des résultats de recherche. Pages de résultats de recherche interne, filtres à facettes, pages de tags peu qualitatives en sont des exemples typiques.
Elle est aussi utile pour les pages temporaires (événements passés, promotions expirées) que vous gardez en ligne pour l'historique mais qui n'ont plus de valeur SEO. Dans ces cas, accepter que le crawl continue n'est pas problématique.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl de son site ?
Commencez par analyser vos logs serveur pour identifier les sections de votre site qui consomment le plus de budget crawl. Vous découvrirez souvent que Googlebot passe du temps sur des pages sans valeur SEO.
Ensuite, utilisez les bons outils selon vos objectifs : robots.txt pour bloquer des sections entières, suppression des liens internes pour réduire naturellement le crawl, codes 404/410 pour les pages supprimées définitivement.
Pour les pages à conserver mais à désindexer, le noindex reste approprié, mais ne comptez pas sur lui pour réduire le crawl. Acceptez que ces pages continuent d'être visitées par Googlebot.
Quelles erreurs faut-il absolument éviter ?
L'erreur la plus critique consiste à bloquer dans le robots.txt des pages noindexées. Cette combinaison est contradictoire : vous empêchez Google de lire la directive qui lui indique de ne pas indexer, ce qui peut paradoxalement maintenir l'URL dans l'index.
Autre piège fréquent : ajouter du noindex sur des pages stratégiques par erreur ou par confusion avec d'autres directives. Un audit régulier de vos balises meta robots est indispensable, surtout sur les sites avec de nombreux contributeurs.
- Analysez régulièrement vos logs serveur pour comprendre le comportement de Googlebot
- Utilisez le noindex uniquement pour contrôler l'indexation, pas le crawl
- Ne bloquez jamais dans robots.txt une URL que vous souhaitez noindexer
- Pour réduire le crawl, supprimez les liens internes ou utilisez robots.txt
- Auditez mensuellement vos directives meta robots pour éviter les erreurs
- Documentez votre stratégie de crawl et d'indexation pour toute l'équipe
- Mesurez l'impact de vos modifications via les rapports de couverture Search Console
Comment s'assurer d'une gestion optimale à long terme ?
La gestion du budget crawl et de l'indexation nécessite une surveillance continue et une expertise technique pointue. Les interactions entre robots.txt, noindex, codes HTTP et architecture de liens sont complexes et une erreur peut avoir des conséquences importantes sur votre visibilité.
💬 Commentaires (0)
Soyez le premier à commenter.