Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Peut-on vraiment forcer Google à ré-indexer un site entier d'un coup ?
- □ Google réindexe-t-il automatiquement les changements majeurs sur un site ?
- □ Pourquoi une simple redirection 301 peut-elle faire toute la différence lors d'une refonte ?
- □ Faut-il vraiment utiliser un code 404 ou 410 pour les pages supprimées ?
- □ Faut-il vraiment lier ses nouvelles pages depuis les pages importantes pour accélérer l'indexation ?
- □ Pourquoi Google recommande-t-il d'afficher les changements critiques sur les pages existantes plutôt que de créer de nouvelles pages ?
- □ Pourquoi Google crawle-t-il certaines pages plus souvent que d'autres ?
- □ Les sitemaps XML sont-ils vraiment indispensables pour l'indexation de votre site ?
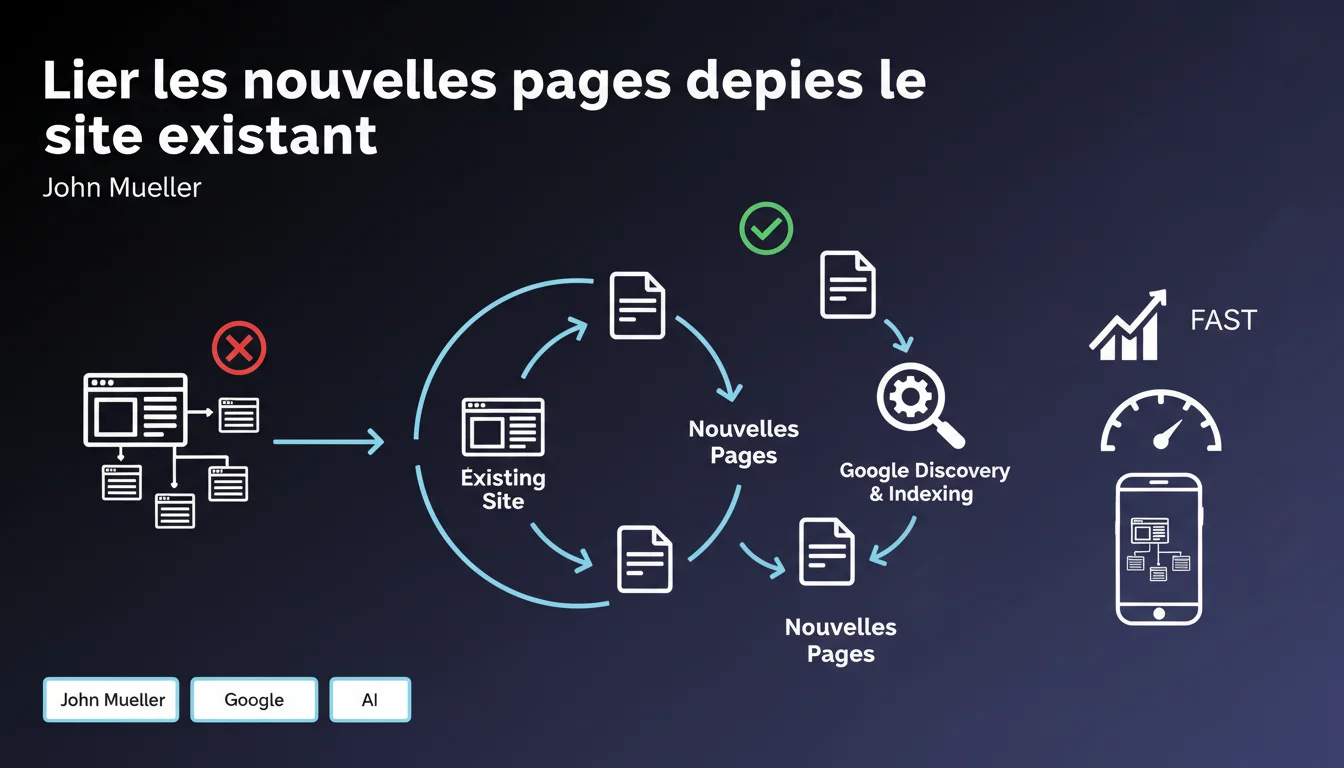
Google rappelle un fondamental souvent négligé : une nouvelle page doit être liée depuis votre site existant pour être découverte et indexée. Sans ce maillage interne, même la meilleure page risque de rester invisible pour Googlebot. C'est une condition sine qua non du crawl, avant même toute question de qualité ou de pertinence.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur le maillage interne pour découvrir les nouvelles pages ?
La déclaration de Mueller touche à la base même du fonctionnement de Googlebot : le crawl par liens. Google ne scanne pas magiquement toutes les URLs d'un site. Il suit des chemins — principalement les liens internes et externes.
Une page orpheline, même techniquement indexable, reste invisible si aucun lien ne la pointe. Le sitemap XML aide, certes, mais il ne garantit rien. Le lien interne, lui, est un signal fort de priorité : il dit à Google « cette page compte assez pour que je la mentionne depuis mon contenu existant ».
Est-ce que soumettre l'URL via Search Console suffit ?
Non. La soumission manuelle (outil d'inspection d'URL) accélère la découverte ponctuelle, mais elle ne remplace pas l'architecture. Google privilégie le crawl naturel par liens, car c'est lui qui détermine la fréquence de passage du bot et la profondeur d'exploration.
Un site bien maillé permet à Googlebot de découvrir rapidement les nouvelles pages et de les re-crawler régulièrement. Sans lien, même une URL soumise manuellement peut ne jamais être re-crawlée après sa première indexation.
Quels types de liens internes comptent vraiment ?
Tous les liens HTML standards comptent, mais leur poids varie. Un lien depuis la homepage, une page catégorie ou un article récent à fort trafic transmet plus de « jus de crawl » qu'un lien enfoui dans un footer ou une page profonde.
Les liens JavaScript sont désormais suivis par Google, mais ils restent moins fiables. Privilégiez le HTML pur pour les nouvelles pages critiques.
- Lien interne = signal de découverte ET de priorité pour Googlebot
- Le sitemap XML complète mais ne remplace jamais le maillage interne
- Les liens depuis des pages fortes (trafic, PageRank interne) accélèrent l'indexation
- Les pages orphelines risquent de ne jamais être crawlées, même si techniquement accessibles
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Absolument. On observe régulièrement des sites avec des centaines de pages non indexées, simplement parce qu'elles sont orphelines ou trop profondes dans l'arborescence. Le crawl budget n'est pas infini, surtout pour les sites moyens ou récents.
Mueller ne dit rien de nouveau ici — il rappelle un basique. Mais c'est justement parce que ce basique est trop souvent négligé. Les équipes techniques publient des pages via CMS, oublient le maillage, puis s'étonnent de l'absence d'indexation. Le sitemap seul ne suffit pas, surtout si le site a déjà des problèmes de crawl budget.
Quelles nuances faut-il apporter à cette recommandation ?
Premier point : tous les liens internes ne se valent pas. Un lien depuis une page déjà bien crawlée (homepage, catégorie principale) a plus d'impact qu'un lien depuis une page enfouie à 5 clics de profondeur. La position du lien compte aussi — un lien dans le contenu éditorial pèse plus qu'un lien dans un footer générique.
Deuxième nuance : le timing. Si vous ajoutez 500 nouvelles pages d'un coup sans architecture solide, Google ne crawlera pas tout instantanément. Il faut prioriser les pages stratégiques en les liant depuis des points forts du site.
Quelle est la limite entre optimisation et sur-optimisation du maillage interne ?
Google n'a jamais donné de chiffre précis sur le nombre maximal de liens internes par page. [A vérifier] mais l'observation terrain suggère qu'au-delà de 150-200 liens sur une page, l'impact se dilue. La logique est simple : plus il y a de liens, moins chacun compte individuellement.
Le vrai risque n'est pas la pénalité, mais l'inefficacité. Un maillage trop dense sans logique éditoriale ou sémantique ne fait que gaspiller du crawl budget. Mieux vaut 10 liens pertinents et contextuels que 100 liens génériques dans un footer.
Impact pratique et recommandations
Que faut-il faire concrètement lors de la publication d'une nouvelle page ?
Avant même de publier, identifiez 3 à 5 pages existantes depuis lesquelles vous allez créer un lien vers la nouvelle page. Choisissez des pages thématiquement proches, déjà bien crawlées, et avec du trafic.
Intégrez le lien dans le contenu éditorial, avec une ancre descriptive (pas de « cliquez ici »). Évitez les blocs de liens en masse — un lien naturel dans un paragraphe a plus de poids qu'un lien dans une liste de 50 URLs.
Comment auditer les pages orphelines sur un site existant ?
Utilisez un crawler type Screaming Frog ou Oncrawl pour comparer les URLs crawlées depuis la homepage avec celles présentes dans votre sitemap XML. Les URLs présentes dans le sitemap mais non découvertes par le crawler sont probablement orphelines.
Vérifiez ensuite dans Search Console : les pages « Découvertes – actuellement non indexées » ou « Explorées – actuellement non indexées » peuvent indiquer un problème de maillage interne ou de crawl budget insuffisant.
Quelles erreurs éviter dans la stratégie de maillage pour les nouvelles pages ?
Ne vous contentez pas d'ajouter un lien dans le footer ou un menu secondaire. Google suit ces liens, certes, mais ils ont un poids faible. Privilégiez les liens éditoriaux dans le corps de texte.
Évitez aussi de créer des « hubs de liens » artificiels — des pages fourre-tout sans valeur éditoriale qui listent 200 URLs. Google les crawlera, mais sans garantie de valorisation.
- Identifier 3-5 pages existantes fortes pour créer des liens vers chaque nouvelle page
- Intégrer les liens dans le contenu éditorial, pas dans les zones génériques (footer, sidebar)
- Utiliser des ancres descriptives et contextuelles
- Crawler le site régulièrement pour détecter les pages orphelines
- Croiser les données sitemap XML vs crawl réel pour repérer les URLs non découvertes
- Prioriser les nouvelles pages stratégiques en les liant depuis la homepage ou les catégories principales
- Surveiller Search Console pour repérer les pages « Découvertes – non indexées » liées à un manque de liens internes
❓ Questions frequentes
Est-ce que soumettre une nouvelle page via le sitemap XML suffit pour l'indexer ?
Combien de liens internes faut-il créer vers une nouvelle page ?
Les liens dans le footer ou le menu comptent-ils autant que les liens éditoriaux ?
Comment savoir si mes nouvelles pages sont orphelines ?
Une page orpheline peut-elle finir par être indexée avec le temps ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 23/01/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.