Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Google favorisait-il vraiment le HTML au détriment du JavaScript pour l'indexation ?
- □ Pourquoi l'indexation JavaScript prend-elle 3 à 6 mois après le crawl ?
- □ Pourquoi vos liens JavaScript ralentissent-ils la découverte de vos pages par Google ?
- □ Le JavaScript peut-il vraiment être indexé plus vite que l'HTML ?
- □ Comment vérifier si Google rend vraiment votre JavaScript avec la méthode du honeypot ?
- □ Tous les frameworks JavaScript sont-ils vraiment égaux face au crawl de Google ?
- □ Google ment-il sur le rendu JavaScript ou simplifie-t-il juste la vérité ?
- □ Faut-il vraiment corriger la technique avant de miser sur le contenu et les backlinks ?
- □ Pourquoi Google recommande-t-il de tester en conditions réelles plutôt que de croire la documentation ?
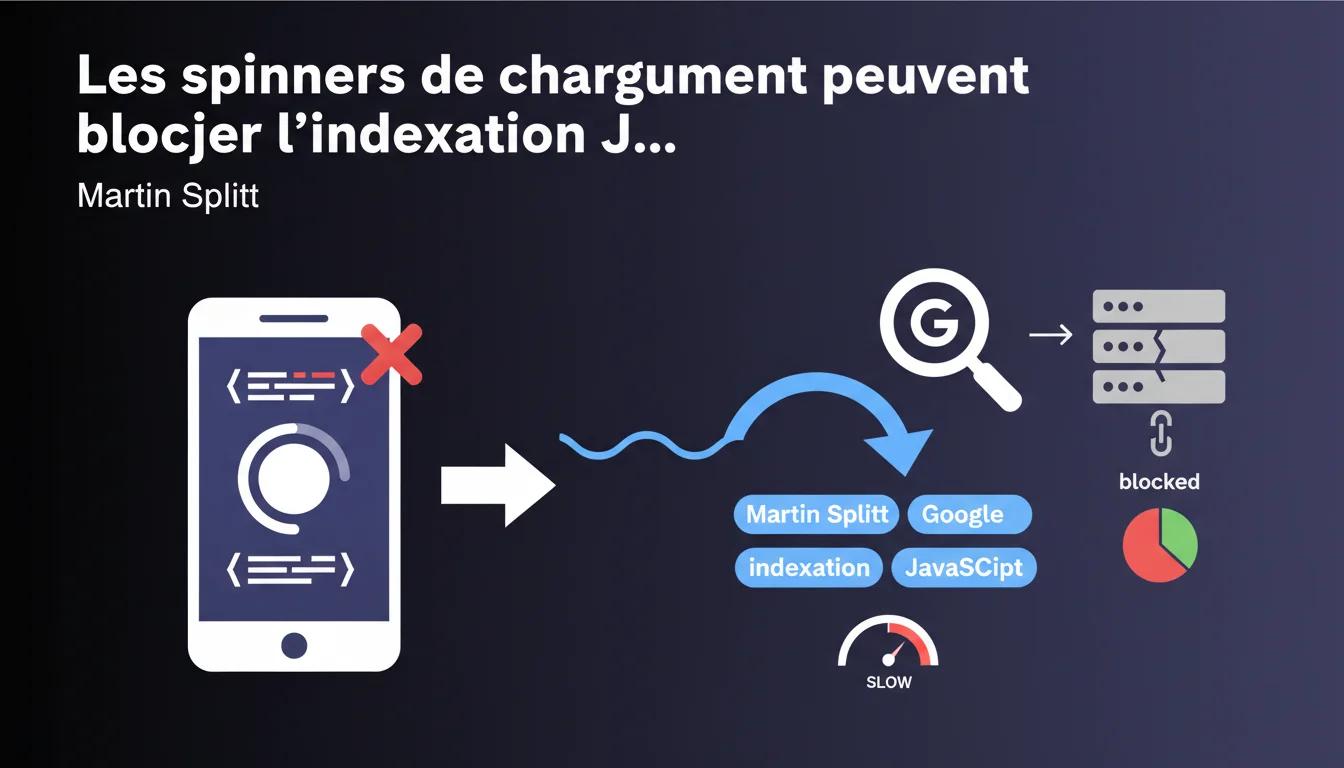
Les roues de chargement qui masquent le contenu pendant le rendu JavaScript peuvent empêcher Googlebot d'indexer vos pages, même si tout s'affiche correctement dans Chrome ou via l'outil Fetch as Google. Le bot n'attend pas indéfiniment qu'un spinner disparaisse — si le contenu reste masqué trop longtemps, il considère la page vide ou incomplète.
Ce qu'il faut comprendre
Pourquoi un spinner afficherait-il du contenu dans Chrome mais pas pour Googlebot ?
Le navigateur humain attend patiemment que le JavaScript finisse son travail. Googlebot, lui, fonctionne avec des timeouts stricts — si votre spinner tourne encore après quelques secondes, le bot capture ce qu'il voit à cet instant précis.
Concrètement ? Si votre contenu principal n'apparaît qu'après disparition du spinner, et que ce spinner met trop de temps à disparaître, Googlebot indexe une page vide. L'outil Fetch as Google peut montrer un rendu correct parce qu'il attend plus longtemps ou capture un état différent — c'est là tout le piège.
Qu'est-ce qui déclenche ce problème de timing ?
Plusieurs scénarios classiques : appels API lents, ressources JavaScript bloquées ou ralenties par le serveur, logique de rendu conditionnelle mal calibrée. Le spinner reste affiché tant que le fetch() n'a pas terminé, et si ce fetch prend 8 secondes, vous perdez Googlebot en route.
Les frameworks modernes (React, Vue, Next.js) gèrent souvent le rendu côté serveur (SSR) pour éviter ce problème. Mais dès qu'on bascule en client-side rendering pur avec des spinners d'attente, on redevient vulnérable.
- Googlebot n'attend pas indéfiniment — il a un budget temps par page
- Les outils de test (Fetch as Google, Chrome DevTools) peuvent donner une fausse impression de sécurité
- Le contenu masqué par un spinner reste invisible pour le bot si le timing dépasse ses seuils
- Ce n'est pas un bug — c'est une limitation structurelle du crawl JavaScript à grande échelle
Quels types de spinners posent le plus de risques ?
Les spinners qui masquent complètement le contenu HTML via CSS (display:none, opacity:0, z-index négatif) sont les plus problématiques. Si le DOM contient déjà le texte mais qu'il est visuellement caché en attendant le JavaScript, Googlebot peut parfois le voir — mais c'est imprévisible.
Les spinners en overlay plein écran, très courants sur les SPA, sont particulièrement dangereux. Ils bloquent littéralement tout jusqu'à ce que l'application soit « prête ». Si cette phase d'initialisation traîne, l'indexation est compromise.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Absolument. J'ai vu des dizaines de cas où Google Search Console affichait des pages indexées avec un contenu vide ou partiel, alors que le site fonctionnait parfaitement côté utilisateur. Le pattern est toujours le même : un spinner ou un skeleton screen qui persiste trop longtemps, et Googlebot qui passe à autre chose.
Ce qui surprend encore certains praticiens, c'est la variance du comportement. Une page peut être correctement indexée un jour et vide le lendemain, simplement parce que le serveur API était plus lent ou que Googlebot a crawlé à un moment de forte charge. Cette instabilité rend le diagnostic difficile sans monitoring continu.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si vous faites du Server-Side Rendering (SSR) ou du Static Site Generation (SSG), vous envoyez déjà du HTML complet à Googlebot — pas de spinner, pas de problème. Next.js, Nuxt, SvelteKit en mode SSR contournent cette limitation par design.
Même en CSR pur, si votre spinner apparaît après que le contenu principal soit déjà dans le DOM (par exemple pour charger un module secondaire), l'impact reste marginal. C'est quand le spinner bloque le contenu critique qu'on entre en zone rouge.
Quelles nuances faut-il apporter à cette déclaration ?
Martin Splitt parle de « masquer le contenu », mais il faut préciser : le problème n'est pas le spinner en soi, c'est le timing. Si votre contenu s'affiche en 500 ms et que le spinner disparaît aussitôt, vous n'aurez jamais de souci.
Le vrai enjeu, c'est l'absence de fallback. Si le JavaScript échoue ou met trop de temps, que voit Googlebot ? Un spinner éternel et rien d'autre. Les sites robustes affichent au minimum un titre H1 et une méta description dans le HTML initial, avant même que le JS ne charge quoi que ce soit. [À vérifier] : Google n'a jamais publié de timeout officiel pour le rendu JavaScript — on parle de 5 secondes en pratique, mais c'est empirique.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter ce problème ?
Priorité absolue : réduire le temps d'affichage du contenu principal. Si votre application dépend d'un appel API pour afficher le texte, passez en SSR ou utilisez du pre-rendering pour les pages critiques (catégories, fiches produits, articles).
Si le CSR est incontournable, affichez un squelette de contenu sémantique dès le HTML initial : balises H1, premiers paragraphes, titres de section. Le spinner peut tourner pendant que le reste charge, mais au moins Googlebot voit quelque chose d'indexable.
- Mesurer le temps réel de disparition du spinner avec Lighthouse ou WebPageTest — viser moins de 2 secondes
- Tester l'indexation avec Mobile-Friendly Test et l'outil d'inspection d'URL (Search Console) — jamais se fier uniquement à Chrome
- Implémenter du SSR ou SSG pour les pages stratégiques SEO (catégories, landing pages, articles)
- Ajouter un fallback HTML dans le document initial : titre, description, premiers éléments de contenu
- Monitorer les erreurs de rendu dans Search Console (onglet Couverture, filtrer « Indexée, non envoyée dans le sitemap » et « Explorée, actuellement non indexée »)
- Auditer les dépendances JavaScript critiques — tout ce qui bloque l'affichage du contenu doit être optimisé ou différé
Comment vérifier que mon site est conforme ?
Utilisez l'outil Inspection d'URL dans Google Search Console — il vous montre exactement ce que Googlebot voit après rendu. Si vous voyez votre spinner ou un écran vide, c'est que le contenu n'est pas accessible au bot.
Comparez systématiquement le HTML brut (view-source:) et le DOM final après JavaScript. Si 100 % du contenu dépend du JS, vous êtes en danger. Un bon ratio : au moins 60-70 % du texte indexable doit être présent dans le HTML initial.
Quelles erreurs éviter absolument ?
Ne masquez jamais le contenu principal avec display:none ou visibility:hidden en attendant le JavaScript. Googlebot peut ignorer ce contenu même s'il est dans le DOM. Préférez un skeleton screen visible qui affiche des placeholders, puis remplacez-les dynamiquement.
Autre piège classique : faire confiance à Fetch as Google comme unique validation. Cet outil peut montrer un rendu correct alors que le crawl réel échoue — les conditions ne sont pas identiques (ressources réseau, timeouts, cache).
L'optimisation du rendu JavaScript et la gestion des spinners nécessitent une approche technique pointue : SSR, pre-rendering, monitoring Search Console, tests multi-environnements. Si votre stack est complexe (React, Vue, Angular en mode SPA), ces ajustements peuvent vite devenir chronophages.
Faire appel à une agence SEO spécialisée en JavaScript SEO peut accélérer le diagnostic et la mise en conformité — notamment pour implémenter du SSR sans refondre toute l'architecture, ou pour auditer finement les timeouts de rendu. Un accompagnement expert vous évite les allers-retours avec les développeurs et garantit que les correctifs soient SEO-compatibles dès la première itération.
❓ Questions frequentes
Googlebot attend-il vraiment moins longtemps que Chrome pour afficher une page ?
Un spinner qui tourne 3 secondes pose-t-il systématiquement problème ?
L'outil Mobile-Friendly Test suffit-il pour valider le rendu ?
Le SSR résout-il définitivement ce problème ?
Peut-on masquer un spinner avec CSS tout en gardant le contenu indexable ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 01/02/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.