Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Google favorisait-il vraiment le HTML au détriment du JavaScript pour l'indexation ?
- □ Les spinners de chargement peuvent-ils vraiment bloquer l'indexation de vos pages JavaScript ?
- □ Pourquoi l'indexation JavaScript prend-elle 3 à 6 mois après le crawl ?
- □ Pourquoi vos liens JavaScript ralentissent-ils la découverte de vos pages par Google ?
- □ Le JavaScript peut-il vraiment être indexé plus vite que l'HTML ?
- □ Tous les frameworks JavaScript sont-ils vraiment égaux face au crawl de Google ?
- □ Google ment-il sur le rendu JavaScript ou simplifie-t-il juste la vérité ?
- □ Faut-il vraiment corriger la technique avant de miser sur le contenu et les backlinks ?
- □ Pourquoi Google recommande-t-il de tester en conditions réelles plutôt que de croire la documentation ?
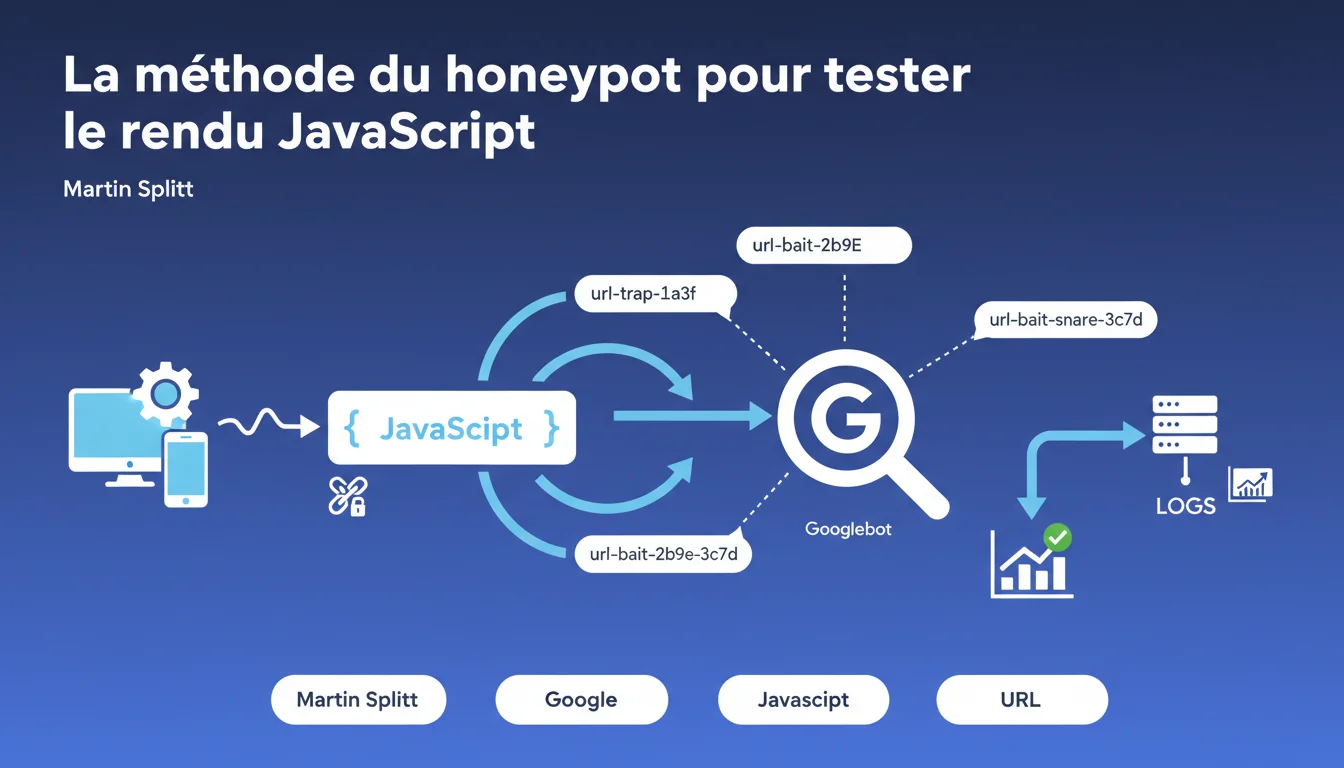
Google recommande de créer des liens uniquement accessibles via JavaScript qui pointent vers des URLs uniques, puis d'analyser les logs serveur pour confirmer que Googlebot accède bien à ces URLs cibles. Cette technique simple permet de vérifier concrètement si le rendu JavaScript fonctionne sans dépendre des outils officiels qui peuvent parfois être trompeurs.
Ce qu'il faut comprendre
Pourquoi Google propose-t-il cette méthode plutôt que d'utiliser Search Console ?
Parce que les outils officiels ne reflètent pas toujours la réalité du terrain. Search Console et l'outil d'inspection d'URL montrent un instantané idéalisé, pas forcément ce que Googlebot fait en production. Les temps de rendu, les ressources bloquées, les erreurs intermittentes — tout ça peut passer inaperçu.
La méthode du honeypot contourne ce problème : elle teste le comportement réel de Googlebot dans son environnement naturel. Si le lien apparaît dans vos logs, c'est que le JavaScript a bien été exécuté et le lien découvert. Pas d'interprétation, juste des faits.
Comment fonctionne concrètement cette technique ?
Vous injectez via JavaScript un lien vers une URL unique — genre /test-js-render-abc123 — qui n'existe nulle part ailleurs sur le site. Pas dans le HTML source, pas dans le sitemap. Uniquement généré côté client.
Ensuite, vous surveillez vos logs serveur. Si Googlebot requête cette URL, c'est la preuve irréfutable qu'il a exécuté le JavaScript, construit le DOM complet et suivi le lien. Simple, élégant, fiable.
Quels sont les pièges à éviter avec cette approche ?
Premier piège : créer une URL qui pourrait être découverte autrement. Si elle traîne dans un fichier JavaScript accessible, dans le cache, ou qu'un bot tiers la trouve, vous aurez un faux positif. L'URL doit être véritablement unique et générée à la volée.
Deuxième piège : oublier que le crawl n'est pas instantané. Googlebot ne passera pas forcément le jour même. Il faut de la patience et vérifier les logs sur plusieurs semaines pour tirer des conclusions solides.
- Technique validée directement par Google pour tester le rendu JavaScript en production
- Repose sur l'analyse des logs serveur, pas sur des outils qui peuvent masquer certains problèmes
- Nécessite de créer des URLs véritablement uniques, jamais exposées ailleurs
- Le délai de crawl peut être long — ne vous attendez pas à des résultats immédiats
- Permet de détecter les cas où le JavaScript est partiellement ou mal exécuté
Avis d'un expert SEO
Cette méthode est-elle vraiment fiable sur tous les types de sites ?
Sur le papier, oui. Dans la pratique ? Ça dépend de votre architecture. Si votre site repose sur un framework SPA complexe avec du code-splitting agressif, du lazy-loading conditionnel et des dépendances externes, Googlebot peut foirer le rendu sans que vous le sachiez.
La méthode du honeypot détecte si un lien est crawlé, mais elle ne garantit pas que tout le contenu JavaScript est correctement indexé. Un lien peut passer alors que des blocs entiers de texte ou des composants restent invisibles. C'est un bon test de fumée, pas un audit exhaustif. [A vérifier] sur des sites à forte dépendance JavaScript.
Pourquoi Google ne fournit-il pas un outil officiel pour ça ?
Bonne question. Ils ont l'outil d'inspection, le rapport de couverture, le Mobile-Friendly Test — mais rien pour valider le rendu JS en conditions réelles. Cette recommandation DIY montre que même Google reconnaît les limites de ses propres outils.
Soyons honnêtes : si Search Console était fiable à 100%, personne n'aurait besoin de bidouiller des honeypots. Le fait que Martin Splitt conseille cette technique prouve que les discordances entre l'outil d'inspection et le crawl réel sont courantes.
Quelles nuances faut-il apporter à cette recommandation ?
Première nuance : cette méthode confirme que Googlebot peut rendre le JavaScript, pas qu'il le fera systématiquement. Le budget crawl, les priorités d'indexation, les erreurs sporadiques — tout ça influence le comportement réel.
Deuxième nuance : un lien crawlé ne signifie pas que le contenu est indexé ni qu'il ranke. Vous aurez validé le rendu, pas la qualité du contenu ou sa pertinence aux yeux de Google. Ne confondez pas crawl, indexation et classement — trois étapes distinctes.
Impact pratique et recommandations
Comment mettre en place ce test honeypot concrètement ?
Choisissez une page représentative de votre site — idéalement une page qui reçoit déjà du crawl régulier. Injectez via JavaScript un lien vers une URL unique, par exemple /honeypot-test-[timestamp]. Assurez-vous que cette URL ne renvoie pas une 404 mais une 200 avec un contenu minimal.
Configurez vos logs serveur pour capturer les requêtes vers cette URL. Si vous utilisez un CDN ou un reverse proxy, vérifiez que les logs incluent bien le user-agent pour distinguer Googlebot des autres bots. Attendez quelques semaines et analysez.
Quelles erreurs courantes faut-il éviter ?
Erreur classique : utiliser une URL déjà crawlée ou présente dans le sitemap. Ça invalide tout le test. L'URL doit être strictement générée côté client, jamais exposée ailleurs.
Autre piège : ne pas vérifier que le lien est bien dans le DOM après exécution du JavaScript. Utilisez l'outil d'inspection pour contrôler que le lien apparaît dans le rendu HTML final — sinon, même si Googlebot exécute le JS, il ne trouvera rien.
Troisième erreur : conclure trop vite. Si Googlebot ne crawle pas l'URL honeypot en une semaine, ça ne veut pas dire qu'il n'exécute pas le JavaScript. Peut-être que la page n'est pas prioritaire, ou que le budget crawl est saturé. Laissez tourner au moins un mois.
Que faire si Googlebot ne crawle jamais l'URL honeypot ?
Plusieurs hypothèses. Soit le JavaScript ne s'exécute pas correctement — erreurs console, ressources bloquées par robots.txt, timeout. Soit la page n'est pas assez crawlée pour que Googlebot découvre le lien. Soit le lien est techniquement présent mais pas assez visible dans le DOM.
Commencez par vérifier les erreurs JavaScript dans la vraie Search Console (pas l'outil d'inspection). Ensuite, testez avec l'outil de test d'optimisation mobile. Si tout semble OK mais que le honeypot ne fonctionne toujours pas, creusez du côté du budget crawl et de la profondeur de page.
- Créer une URL honeypot unique, jamais exposée ailleurs (sitemap, HTML source, liens internes classiques)
- Injecter le lien via JavaScript uniquement, sur une page déjà régulièrement crawlée
- Configurer les logs serveur pour capturer les requêtes avec user-agent Googlebot
- Vérifier avec l'outil d'inspection que le lien apparaît bien dans le DOM rendu
- Attendre au minimum 3-4 semaines avant de tirer des conclusions
- Croiser les résultats avec d'autres outils (Search Console, logs de rendu, tests Lighthouse)
- Si le test échoue, auditer les erreurs JavaScript, le robots.txt et le budget crawl
❓ Questions frequentes
Cette méthode fonctionne-t-elle aussi pour tester le rendu JavaScript sur mobile ?
Combien de temps faut-il attendre pour que Googlebot crawle l'URL honeypot ?
Peut-on utiliser cette technique pour tester le rendu de contenu dynamique complexe ?
Faut-il supprimer l'URL honeypot après le test ou la laisser en place ?
Cette méthode peut-elle détecter les problèmes de rendu liés à des ressources tierces bloquées ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 01/02/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.