Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Le HTML invalide nuit-il vraiment au référencement naturel ?
- □ Pourquoi vos métadonnées cassées sabotent-elles votre SEO sans bloquer l'indexation ?
- □ Faut-il encore utiliser la balise meta keywords en SEO ?
- □ Les commentaires HTML ont-ils un impact sur le référencement Google ?
- □ Votre thème WordPress sabote-t-il votre référencement sans que vous le sachiez ?
- □ Les Core Web Vitals sont-ils vraiment un levier de classement dans Google ?
- □ Comment vérifier que JavaScript ne bloque pas l'indexation de votre contenu ?
- □ Pourquoi l'API d'indexation Google reste-t-elle bloquée sur deux types de contenus ?
- □ Angular bénéficie-t-il d'un traitement de faveur chez Google ?
- □ Faut-il vraiment virer tous ces scripts Google de votre site ?
- □ La structure HTML sémantique est-elle vraiment un facteur de compréhension pour Google ?
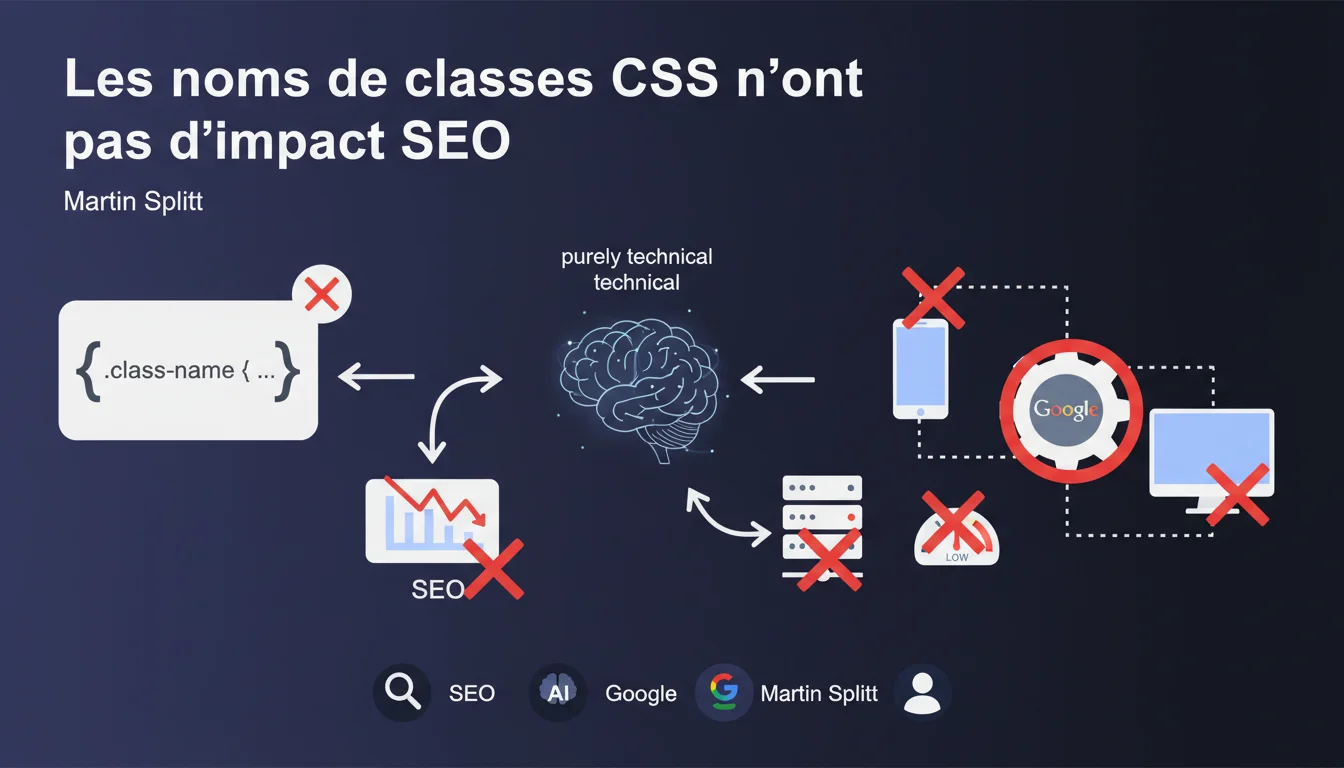
Google affirme que les noms de classes CSS n'ont aucun impact SEO et qu'il est inutile d'y insérer des mots-clés. Ces attributs sont considérés comme purement techniques, sans valeur sémantique pour l'algorithme. Une clarification bienvenue qui devrait mettre fin à une pratique obsolète encore répandue.
Ce qu'il faut comprendre
Pourquoi cette confusion persiste-t-elle encore ?
La tentation d'optimiser les noms de classes CSS avec des mots-clés remonte aux débuts du SEO, quand chaque bout de texte dans le code HTML semblait potentiellement exploitable. Certains praticiens pensaient que Google analysait ces attributs pour mieux comprendre le contexte sémantique d'une page.
Cette croyance s'est perpétuée par mimétisme et manque de documentation claire. Pendant des années, aucune déclaration officielle ne tranchait explicitement la question — jusqu'à cette mise au point de Martin Splitt.
Quelle est la position technique de Google sur les classes CSS ?
Google traite les noms de classes comme des informations purement techniques, au même titre que les identifiants ou les commentaires de développeurs. Leur fonction se limite à la mise en forme visuelle et à la manipulation JavaScript côté client.
L'algorithme de ranking ne crawle pas ces attributs pour en extraire du sens sémantique. Remplacer class="product-title" par class="abc123" n'aura strictement aucun impact sur votre positionnement.
Les développeurs peuvent-ils ignorer totalement le SEO dans leurs conventions de nommage ?
Absolument. Les équipes front-end sont libres d'adopter n'importe quelle méthodologie — BEM, Atomic CSS, Tailwind, CSS-in-JS — sans se soucier d'une quelconque répercussion SEO. La maintenabilité du code et la cohérence interne priment.
Cela dit, une architecture CSS propre facilite indirectement le SEO en permettant une meilleure organisation du contenu HTML, une hiérarchie claire et des temps de chargement optimisés. Mais c'est un effet de bord, pas une corrélation directe.
- Les noms de classes CSS ne sont pas indexés ni analysés par Google pour le ranking
- Aucun avantage SEO à bourrer des mots-clés dans vos attributs
class - Concentrez vos efforts d'optimisation sur les balises sémantiques HTML5 et le contenu visible
- Les méthodologies CSS modernes (BEM, Tailwind) sont parfaitement compatibles avec les bonnes pratiques SEO
- L'impact indirect se limite à la qualité globale du code et aux performances de rendu
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Totalement. Aucun test A/B sérieux n'a jamais démontré qu'optimiser les noms de classes impactait le ranking. Les cas isolés où une corrélation semblait apparaître relevaient en réalité d'autres facteurs — refonte globale du HTML, amélioration de la structure sémantique, meilleure hiérarchie des titres.
Les outils d'audit SEO qui signalent encore les classes CSS comme opportunité d'optimisation sont simplement obsolètes. Ils appliquent des heuristiques datées qui n'ont plus aucun fondement technique.
Faut-il pour autant négliger complètement l'architecture CSS ?
Non, et c'est là qu'une nuance s'impose. Si les noms de classes n'ont pas d'impact direct, une architecture CSS désastreuse peut provoquer des effets collatéraux mesurables : fichiers CSS surchargés qui ralentissent le rendu, prolifération de styles inline qui gonflent le HTML, surcharge de JavaScript pour compenser une mauvaise structure.
Ces problèmes dégradent les Core Web Vitals (LCP, CLS) et l'expérience utilisateur — deux facteurs qui, eux, comptent réellement. Une CSS propre contribue donc indirectement à un meilleur SEO technique, même si les noms d'attributs restent neutres.
Existe-t-il des exceptions où les classes CSS pourraient jouer un rôle ?
En théorie, non. En pratique, une seule situation mérite attention : les données structurées injected via classes. Certains frameworks JavaScript utilisent des noms de classes pour déclencher l'injection de rich snippets ou de JSON-LD côté client.
Dans ce cas précis, ce n'est pas le nom de classe lui-même qui compte pour Google, mais le code JavaScript qu'il déclenche et les données structurées qu'il génère. Le vrai enjeu reste donc le rendu final côté Googlebot. [A vérifier] : Google n'a pas fourni de documentation détaillée sur le crawl des classes utilisées comme sélecteurs pour l'hydratation de contenu dynamique.
Impact pratique et recommandations
Que faut-il faire concrètement avec vos conventions CSS actuelles ?
Rien. Si votre équipe utilise déjà une méthodologie cohérente (BEM, SMACSS, Tailwind), ne changez absolument rien sous prétexte d'optimisation SEO. Vous perdriez du temps pour zéro gain mesurable.
Si par contre vous aviez adopté des conventions lourdes spécifiquement pour le SEO — comme préfixer chaque classe par un mot-clé cible — vous pouvez simplifier drastiquement votre code sans crainte. Cela allègera vos fichiers CSS, améliorera la lisibilité pour les développeurs et réduira potentiellement le poids des pages.
Quelles erreurs éviter désormais ?
Ne perdez plus de temps à optimiser vos noms de classes pour Google. C'est du cargo cult SEO — une pratique héritée qui n'a jamais eu de fondement réel.
Évitez aussi de confondre classes CSS et balises sémantiques HTML5. Remplacer <article> par <div class="article"> reste une erreur SEO majeure, même si la classe elle-même n'est pas analysée. Google comprend les balises natives, pas vos conventions de nommage.
Comment vérifier que votre architecture CSS ne nuit pas indirectement au SEO ?
Concentrez-vous sur les métriques qui comptent vraiment : temps de chargement des CSS, nombre de requêtes HTTP, poids total des feuilles de style, impact sur les Core Web Vitals. Ces éléments ont un effet mesurable sur le ranking.
Utilisez les outils classiques — Google PageSpeed Insights, Chrome DevTools, WebPageTest — pour identifier les goulots d'étranglement. Si votre CSS bloque le rendu ou génère un CLS élevé, là vous avez un vrai problème SEO à corriger.
- Continuez d'utiliser vos conventions CSS habituelles sans arrière-pensée SEO
- Supprimez les préfixes de mots-clés inutiles si vous en aviez implémentés
- Privilégiez une architecture CSS légère et maintenable (moins de fichiers, meilleure compression)
- Auditez l'impact de vos CSS sur les Core Web Vitals, pas sur les noms d'attributs
- Assurez-vous que le contenu critique s'affiche même si les CSS ne chargent pas (progressive enhancement)
- Vérifiez que Googlebot reçoit bien le rendu complet si vous utilisez du JavaScript qui s'appuie sur des classes
- Documentez clairement vos conventions pour les équipes — la cohérence interne vaut mieux qu'une optimisation fantôme
❓ Questions frequentes
Puis-je utiliser Tailwind CSS sans craindre un impact SEO négatif ?
Les classes CSS jouent-elles un rôle pour l'accessibilité détectée par Google ?
Faut-il supprimer les anciennes classes optimisées pour le SEO ?
Les data-attributes ont-ils le même statut que les classes CSS ?
Une refonte CSS peut-elle indirectement améliorer mon SEO ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 26/06/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.