Declaration officielle
Ce qu'il faut comprendre
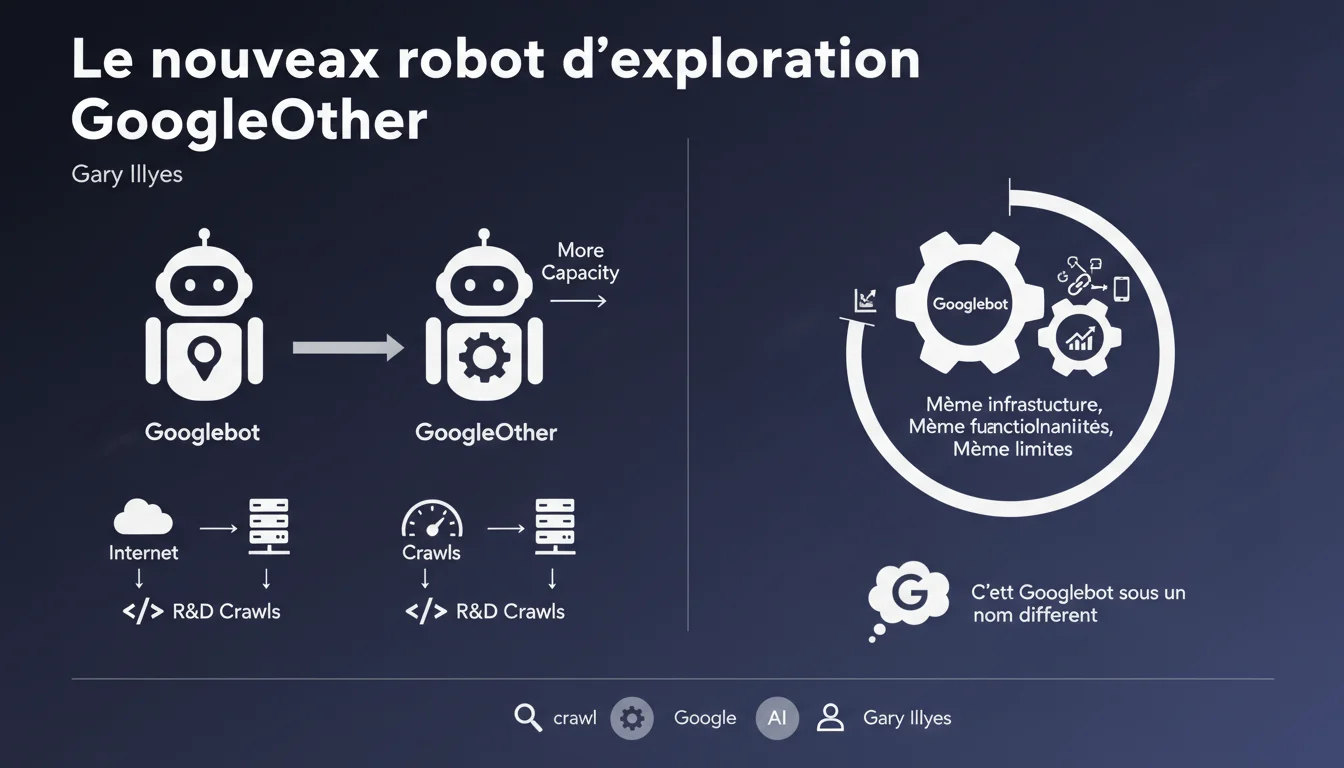
Google a introduit un nouveau robot d'exploration appelé GoogleOther, qui vient s'ajouter à l'écosystème des crawlers de Google. Contrairement à ce que son nom pourrait suggérer, ce bot n'est pas destiné à des tâches de recherche et développement au sens traditionnel.
GoogleOther est en réalité un crawler à usage général qui prend en charge toutes les tâches de crawl qui ne concernent pas directement l'indexation pour le moteur de recherche Google. Il s'agit essentiellement de Googlebot sous une autre identité, partageant la même infrastructure technique et les mêmes capacités.
L'objectif principal de cette séparation est de libérer de la capacité de crawl pour Googlebot, permettant ainsi au robot principal de se concentrer exclusivement sur l'exploration et l'indexation des contenus pour les résultats de recherche. GoogleOther gère donc toutes les autres nécessités de crawl de Google.
- GoogleOther utilise exactement la même technologie que Googlebot (même infrastructure, mêmes fonctionnalités)
- Il ne sert pas à indexer des pages pour la recherche Google
- Son rôle est de soulager Googlebot en prenant en charge d'autres types de crawls
- Cette séparation améliore l'allocation des ressources de crawl de Google
- Il respecte les mêmes règles robots.txt et les mêmes limitations que Googlebot
Avis d'un expert SEO
Cette décision de Google est parfaitement cohérente avec l'évolution de leur infrastructure. Au fil des années, Google a développé de nombreux services annexes nécessitant du crawl : vérification de la Search Console, analyse de sécurité, détection de spam, collecte de données pour l'IA, etc. Regrouper toutes ces activités sous un même bot permet une meilleure traçabilité et gestion des ressources.
D'un point de vue technique, cette séparation est logique et sans danger pour les sites web. GoogleOther respecte les mêmes règles que Googlebot, ce qui signifie que vos directives robots.txt et vos paramètres de crawl existants continuent de fonctionner. Il n'y a aucune raison de bloquer spécifiquement ce nouveau crawler.
Impact pratique et recommandations
- Ne bloquez pas GoogleOther dans votre robots.txt – il utilise la même infrastructure que Googlebot et respecte déjà vos règles existantes
- Mettez à jour vos outils d'analyse de logs si vous surveillez le crawl budget : séparez GoogleOther de Googlebot dans vos rapports pour une vision plus précise
- Concentrez-vous sur Googlebot pour les optimisations de crawl – c'est lui seul qui impacte votre indexation et votre SEO
- Vérifiez que GoogleOther apparaît dans vos logs comme preuve que Google explore activement votre site pour divers services (bon signe d'activité)
- Ne modifiez pas votre stratégie de crawl budget – les principes restent identiques, seule la répartition interne de Google change
- Documentez ce changement dans vos procédures si vous avez des processus de monitoring automatisés qui identifient les bots
Cette évolution illustre la complexité croissante de l'écosystème Google et la nécessité d'une veille technique permanente. L'analyse fine des logs de crawl, la distinction entre différents bots et l'optimisation du crawl budget deviennent des compétences pointues qui requièrent expertise et outils spécialisés. Pour les sites à fort volume ou à enjeux stratégiques importants, cette technicité croissante justifie souvent l'accompagnement par une agence SEO spécialisée, capable d'interpréter ces données complexes et d'ajuster finement les paramètres techniques pour maximiser votre visibilité.
💬 Commentaires (0)
Soyez le premier à commenter.