Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ Pourquoi Google bloque-t-il le JavaScript en cache et comment ça impacte votre crawl ?
- □ Pourquoi le cache Google de votre site JavaScript affiche-t-il une page vide ?
- □ Google indexe-t-il vraiment ce que l'utilisateur voit ou ce qui est dans le cache ?
- □ Google Search Console affiche-t-il vraiment le rendu JavaScript qu'il indexe ?
- □ JavaScript et SEO : Google indexe-t-il vraiment votre contenu dynamique ?
- □ Un cache vide signifie-t-il un problème d'indexation sur un site JavaScript ?
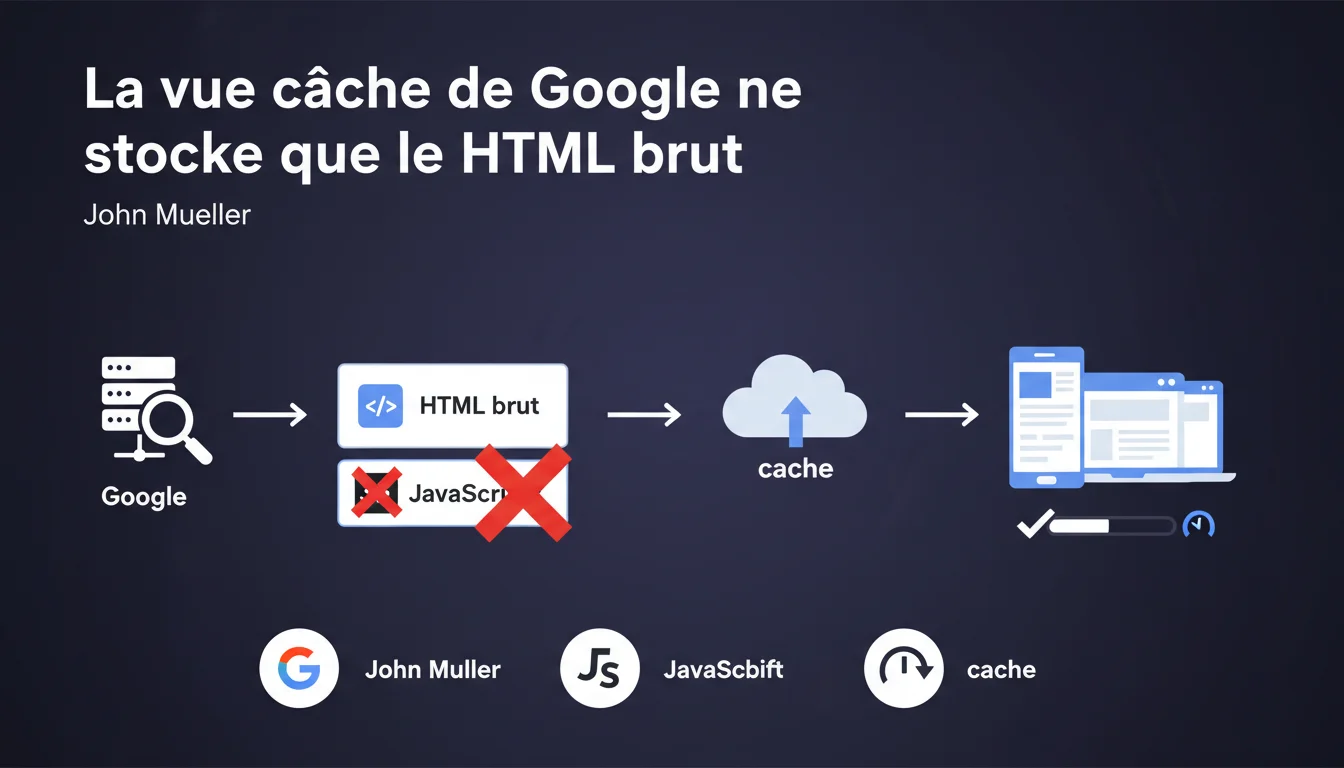
Google conserve uniquement le HTML brut dans sa vue cache, sans rendu JavaScript. Si votre contenu principal dépend de JS pour s'afficher, il n'apparaîtra pas dans la page en cache visible par les utilisateurs. Distinction cruciale : le cache utilisateur ≠ l'index de recherche.
Ce qu'il faut comprendre
Quelle est la différence entre cache utilisateur et index de recherche ?
Le cache Google accessible aux internautes (via l'option "En cache" dans les résultats) affiche uniquement le HTML brut récupéré lors du crawl. Pas de rendu JavaScript, pas de CSS appliqué, juste le code source initial.
L'index de recherche, lui, intègre le contenu rendu après exécution du JavaScript — c'est ce que Google utilise pour le classement. Ces deux entités fonctionnent indépendamment.
Pourquoi Google ne stocke-t-il que le HTML brut dans le cache ?
Question de ressources serveur et de complexité. Stocker une version rendue de chaque page crawlée demanderait une capacité de calcul phénoménale.
Le cache utilisateur sert principalement à consulter une page quand le site d'origine est temporairement inaccessible. Pour cet usage, le HTML brut suffit largement — même s'il n'affiche qu'une structure squelettique.
Cela signifie-t-il que mon contenu JS n'est pas indexé ?
Non. Cette déclaration ne concerne que la vue cache présentée aux utilisateurs, pas l'indexation. Google exécute bien le JavaScript pour indexer votre contenu — c'est documenté depuis des années.
Mais si votre contenu principal n'apparaît que via JS, les utilisateurs consultant la version cache ne verront qu'une coquille vide. Problème d'accessibilité, pas de ranking direct.
- Le cache utilisateur affiche uniquement le HTML brut récupéré par Googlebot
- L'index de recherche traite le contenu après rendu JavaScript
- Un contenu invisible dans le cache peut être parfaitement indexé et classé
- La vue cache sert aux utilisateurs pour consulter des pages temporairement indisponibles
Avis d'un expert SEO
Cette distinction cache/index est-elle vraiment nouvelle ?
Absolument pas. Les praticiens SEO l'observent depuis que Google a commencé à crawler le JavaScript — soit depuis 2015 environ.
Ce qui est intéressant ici, c'est que Mueller formalise explicitement ce que beaucoup avaient compris empiriquement. Moins d'ambiguïté, c'est toujours bon à prendre.
Pourquoi clarifier ce point maintenant ?
Soyons honnêtes : cette déclaration répond probablement à des confusions récurrentes dans la Search Console Community ou sur les forums. Beaucoup de webmasters paniquent en voyant leur cache vide alors que leur site rank correctement.
Mueller coupe court : le cache utilisateur n'est pas un indicateur de ce que Google indexe réellement. Point final.
Y a-t-il des nuances que Google omet ici ?
Oui — et c'est là que ça coince. Google ne précise pas combien de temps s'écoule entre le crawl HTML initial et le rendu JavaScript dans l'index. Ce délai peut varier de quelques heures à plusieurs jours selon votre crawl budget.
Pendant cette fenêtre, votre contenu JS existe techniquement mais peut ne pas être encore indexé. [À vérifier] : Google ne publie aucune métrique officielle sur ce décalage temporel, alors qu'il impacte directement la fraîcheur de l'index pour les sites dynamiques.
Impact pratique et recommandations
Faut-il abandonner le JavaScript côté client pour le SEO ?
Non. Mais il faut architecturer intelligemment. Si votre contenu critique (titres, paragraphes principaux, données structurées) dépend entièrement de JS, vous prenez un risque inutile.
Le SSR (Server-Side Rendering) ou la génération statique garantissent que le HTML initial contient déjà l'essentiel. Google indexe plus vite, et en bonus, vos utilisateurs voient quelque chose dans le cache.
Comment vérifier ce que Google voit réellement ?
Utilisez l'outil Inspection d'URL dans la Search Console. Comparez le HTML brut et la version rendue — si un écart massif existe, c'est un signal d'alerte.
Testez aussi avec un navigateur en mode « JavaScript désactivé ». Si votre page ressemble à un désert, les utilisateurs consultant le cache auront la même expérience.
Quelles actions concrètes mettre en place ?
- Auditer vos pages stratégiques : comparez HTML source vs rendu final dans la Search Console
- Prioriser le SSR ou la génération statique pour le contenu critique (landing pages, fiches produits, articles)
- Garder le JS côté client pour les interactions secondaires (carrousels, filtres dynamiques, animations)
- Vérifier que vos données structurées schema.org sont présentes dans le HTML initial, pas injectées uniquement via JS
- Monitorer le délai entre publication et indexation effective sur les contenus temps-réel
- Documenter les choix techniques pour justifier les arbitrages performance vs SEO
❓ Questions frequentes
Si mon contenu n'apparaît pas dans le cache Google, est-il quand même indexé ?
Le cache Google influence-t-il le classement de mes pages ?
Dois-je éviter les frameworks JavaScript comme React ou Vue pour le SEO ?
Pourquoi Google ne stocke-t-il pas la version rendue dans le cache utilisateur ?
Comment savoir si Google a du mal à indexer mon contenu JavaScript ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 06/04/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.