Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ La vue cache de Google stocke-t-elle vraiment tout votre contenu ?
- □ Pourquoi Google bloque-t-il le JavaScript en cache et comment ça impacte votre crawl ?
- □ Pourquoi le cache Google de votre site JavaScript affiche-t-il une page vide ?
- □ Google Search Console affiche-t-il vraiment le rendu JavaScript qu'il indexe ?
- □ JavaScript et SEO : Google indexe-t-il vraiment votre contenu dynamique ?
- □ Un cache vide signifie-t-il un problème d'indexation sur un site JavaScript ?
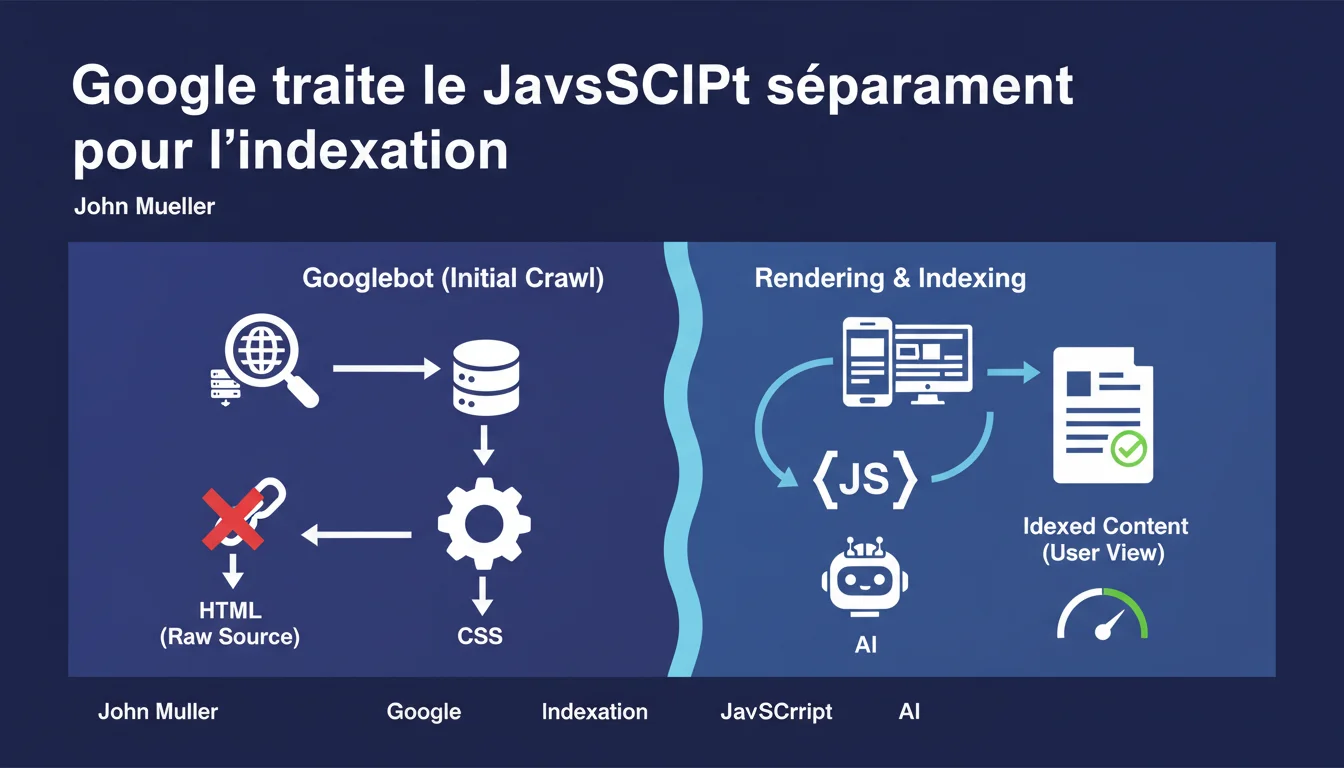
Google traite le JavaScript séparément lors de l'indexation et cherche à indexer ce qu'un visiteur réel verrait, pas forcément ce qui apparaît dans la vue cache. Cette distinction technique implique que le rendu côté client peut différer de ce que Googlebot enregistre initialement, avec des implications directes sur le taux d'indexation de contenus dynamiques.
Ce qu'il faut comprendre
Pourquoi Google sépare-t-il le traitement du JavaScript ?
Googlebot fonctionne en deux phases distinctes. D'abord, il crawle et indexe le HTML brut. Ensuite, il met en file d'attente les pages contenant du JavaScript pour un rendu ultérieur dans un navigateur headless (généralement basé sur Chromium).
Cette séparation crée un décalage temporel — parfois de quelques heures, parfois de plusieurs jours — entre la capture initiale et le rendu final. Durant ce laps de temps, Google travaille avec une version incomplète de votre page.
Que signifie concrètement "ce qu'un utilisateur verrait" ?
Mueller affirme que Google tente d'indexer la version rendue, celle qu'un visiteur découvre réellement. Mais "tente" est le mot-clé ici. Le succès de ce rendu dépend de multiples facteurs : temps d'exécution du JS, erreurs console, ressources bloquées, timeouts.
La vue cache — accessible via cache:votresite.com — ne reflète pas toujours fidèlement ce qui a été indexé. C'est une représentation approximative, pas une source de vérité absolue pour diagnostiquer des problèmes d'indexation JavaScript.
Quelle différence avec le HTML statique classique ?
Avec du HTML pur, ce que Googlebot voit = ce qu'il indexe. Immédiatement. Pas de file d'attente, pas de rendu différé, pas d'incertitude.
Avec du JavaScript, vous introduisez une couche de complexité et d'aléas. Google doit allouer des ressources de calcul pour exécuter votre code — et si votre JS est mal optimisé ou trop lourd, le rendu peut échouer partiellement ou complètement.
- Le HTML brut est crawlé en premier, avant tout rendu JavaScript
- Le rendu JS intervient après, avec un délai variable selon le crawl budget
- La vue cache n'est pas fiable pour diagnostiquer ce qui est réellement indexé
- Des erreurs JS peuvent bloquer l'indexation de contenus pourtant visibles pour les utilisateurs
- Le SSR ou le pre-rendering éliminent cette dépendance au rendu différé
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui et non. Google tente effectivement de rendre le JavaScript, c'est documenté et observable via les outils de test de rendu dans Search Console. Mais dire qu'il indexe "ce qu'un utilisateur verrait" est optimiste.
Sur le terrain, on constate régulièrement des cas où du contenu parfaitement visible côté client n'apparaît jamais dans l'index. Raisons fréquentes : timeouts trop courts (Google n'attend pas indéfiniment), erreurs console non détectées en développement mais critiques pour Googlebot, ressources externes qui échouent à charger dans l'environnement de rendu.
Quelles nuances faut-il apporter à cette affirmation ?
Mueller ne précise pas quand ce rendu intervient ni combien de temps Google alloue pour exécuter votre JavaScript. Ces paramètres varient selon votre crawl budget — un site à forte autorité bénéficiera d'un rendu plus rapide et plus généreux qu'un nouveau blog.
La formulation "tente d'indexer" est aussi révélatrice. Google essaie, mais ne garantit rien. Si votre JS dépend de cookies, de localStorage, d'interactions utilisateur ou d'APIs tierces capricieuses, le rendu peut échouer silencieusement. [À vérifier] : Google ne publie pas de logs d'erreurs accessibles pour diagnostiquer ces échecs.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre contenu critique est généré uniquement côté client via du JavaScript complexe — par exemple, des frameworks SPA mal configurés — Google peut indexer une coquille vide même après le rendu. J'ai vu des sites React/Vue où Googlebot indexait littéralement juste la balise <div id="app"></div>.
Autre cas problématique : les contenus chargés après interaction (clic, scroll infini, tabs). Google ne simule pas ces interactions. Si votre produit phare est dans un onglet caché par défaut, il ne sera jamais indexé, peu importe le rendu JS.
Impact pratique et recommandations
Que faut-il faire concrètement pour sécuriser l'indexation ?
D'abord, auditez votre dépendance au JavaScript. Identifiez quel contenu est généré côté client : titres, descriptions, body principal, liens internes. Si des éléments critiques pour le SEO sont dans cette liste, vous avez un problème potentiel.
Ensuite, implémentez du Server-Side Rendering (SSR) ou du pre-rendering. Next.js, Nuxt, Angular Universal — ces outils existent justement pour servir du HTML complet dès la requête initiale. Googlebot indexe immédiatement, sans attendre un hypothétique rendu ultérieur.
Quelles erreurs éviter absolument ?
Ne bloquez jamais les ressources JavaScript ou CSS via robots.txt. Google en a besoin pour rendre la page correctement. Je vois encore trop de sites qui bloquent /assets/js/ par réflexe — erreur critique.
Évitez les frameworks JS mal configurés qui servent une page blanche avant le chargement complet. Le premier HTML doit contenir au minimum une structure sémantique de base, pas juste un loader animé.
N'utilisez pas de techniques de cloaking involontaire : si votre JS détecte un user-agent et sert du contenu différent à Googlebot, vous risquez une pénalité manuelle. Google veut voir exactement ce que voit un utilisateur Chrome standard.
Comment vérifier que mon site est conforme ?
- Testez chaque template clé avec l'outil "Inspection d'URL" dans Search Console
- Comparez le HTML brut (view-source) et le HTML rendu (outil Google) — les contenus critiques doivent apparaître dans les deux
- Vérifiez la console JavaScript dans l'outil de test : zéro erreur rouge tolérée
- Activez le rendu dynamique (dynamic rendering) si vous ne pouvez pas migrer vers du SSR immédiatement
- Monitorer le taux d'indexation via l'API Indexing ou des outils tiers — une baisse soudaine signale souvent un problème JS
- Auditez les Core Web Vitals : un LCP dégradé par du JS bloquant impacte aussi le crawl budget
❓ Questions frequentes
La vue cache Google reflète-t-elle ce qui est réellement indexé ?
Combien de temps Google attend-il pour rendre le JavaScript d'une page ?
Le rendu dynamique (dynamic rendering) est-il toujours acceptable pour Google ?
Si mon contenu apparaît dans l'outil de test d'URL, est-il forcément indexé ?
Les Single Page Applications (SPA) sont-elles incompatibles avec le SEO ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 06/04/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.