Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Faut-il vraiment maîtriser le développement web pour faire du SEO ?
- □ Faut-il vraiment maîtriser le développement web pour faire du SEO technique ?
- □ Pourquoi Google insiste-t-il autant sur l'accessibilité, la vitesse et l'expérience utilisateur du web ?
- □ Faut-il vraiment éviter JavaScript pour améliorer ses performances SEO ?
- □ Pourquoi appliquer les mêmes recommandations SEO à tous les sites est-il une erreur stratégique ?
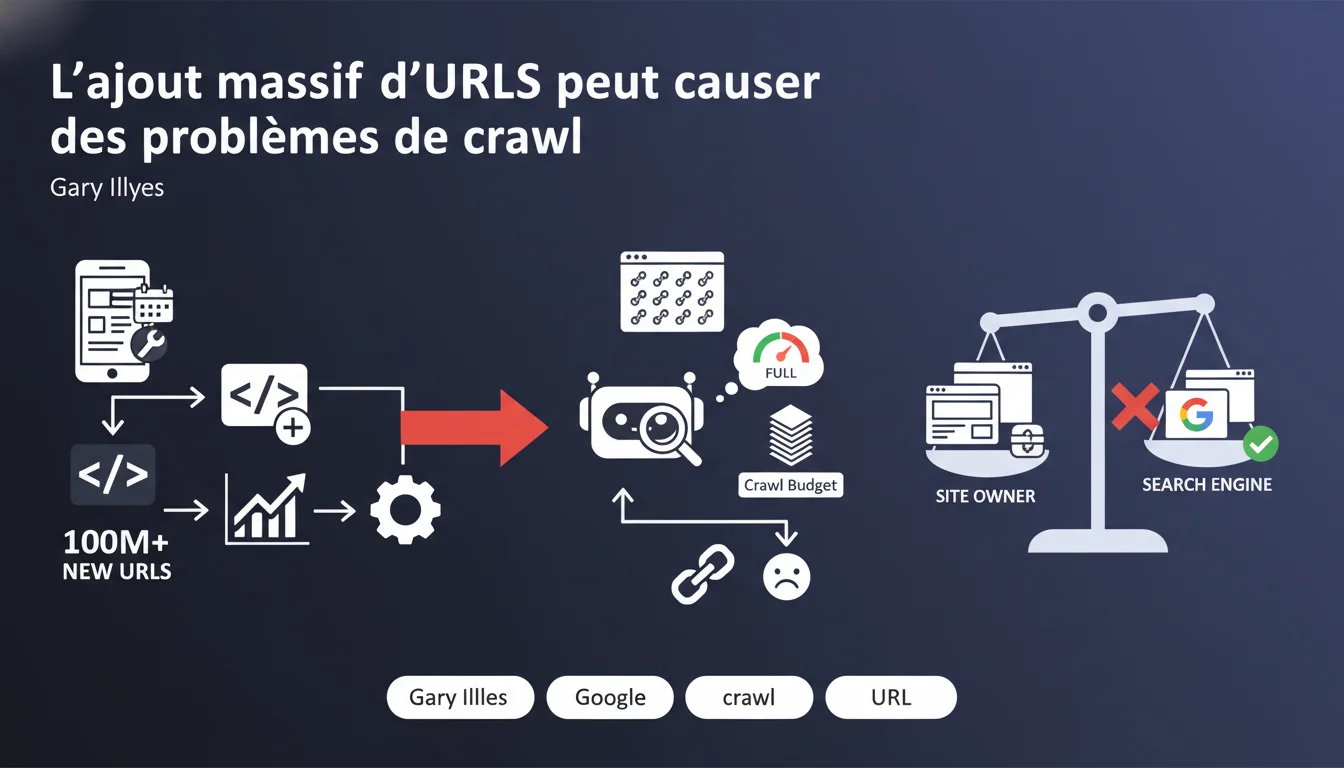
L'installation de plugins générant automatiquement des millions d'URLs (calendriers, filtres, archives) peut saturer votre budget de crawl. Googlebot tentera de crawler ces nouvelles URLs, au détriment des pages stratégiques. Google renvoie clairement la balle aux webmasters : c'est à vous de maîtriser ce qui est publié sur votre site.
Ce qu'il faut comprendre
Quels types de plugins provoquent cette explosion d'URLs ?
Gary Illyes cite explicitement les calendriers, mais le problème touche tout plugin générant des URLs paramétrées à l'infini. Les systèmes de filtrage produits (taille, couleur, prix, marque combinés), les archives par date (jour/mois/année), ou les systèmes de pagination mal configurés entrent dans cette catégorie.
Un site e-commerce peut passer de 10 000 URLs indexables à plusieurs millions en quelques clics — dès qu'un développeur active un module sans contrôle. Googlebot découvre ces URLs via le crawl exploratoire ou les sitemaps XML, et commence à les parcourir méthodiquement.
Que se passe-t-il concrètement quand le budget de crawl sature ?
Googlebot dispose d'un temps limité pour crawler votre site lors de chaque visite. Si ce temps est monopolisé par des URLs inutiles (filtres vides, pages de calendrier sans contenu), les pages stratégiques — fiches produits, articles récents, pages commerciales — sont crawlées moins souvent.
Résultat : vos nouvelles pages mettent plus de temps à être indexées, vos mises à jour ne sont pas détectées rapidement, et votre réactivité SEO s'effondre. Sur les gros sites, ce décalage peut atteindre plusieurs semaines.
Google assume-t-il une part de responsabilité ?
Non, et c'est le message clé de cette déclaration. Google renvoie la balle aux webmasters : si votre site génère 100 millions d'URLs, c'est votre problème, pas celui de Googlebot. Le crawler fait son travail — c'est à vous de contrôler ce que vous exposez.
Cette position est cohérente avec la philosophie de Google sur le crawl : le moteur ne devrait pas avoir à deviner ce qui est important. C'est au site de structurer proprement son arborescence et ses directives.
- Les plugins générant des millions d'URLs (calendriers, filtres) saturent le budget de crawl
- Googlebot crawle ces nouvelles URLs au détriment des pages stratégiques
- Google refuse toute responsabilité — c'est au webmaster de maîtriser son architecture
- Le problème touche particulièrement les sites e-commerce et médias avec pagination complexe
Avis d'un expert SEO
Cette position est-elle cohérente avec les observations terrain ?
Totalement. On constate régulièrement dans les logs serveur que Googlebot passe un temps démesuré sur des URLs à faible valeur — filtres produits vides, pages d'archives sans contenu, variantes de tri inutiles. Sur un site client récemment audité, 73 % du crawl était consacré à des URLs générées par un plugin de filtrage mal configuré.
Le problème, c'est que Google ne fournit pas de seuil chiffré. À partir de combien d'URLs considère-t-on qu'il y a un problème ? 100 000 ? 1 million ? 10 millions ? Cette déclaration reste floue sur le seuil critique [À vérifier].
Googlebot ne pourrait-il pas mieux distinguer les URLs utiles ?
En théorie, oui — et Google y travaille. Les algorithmes de crawl intelligent sont censés identifier les patterns d'URLs inutiles et ajuster le budget. Mais dans la pratique, ce mécanisme est lent à réagir et souvent insuffisant sur les sites avec une architecture complexe.
Soyons honnêtes : attendre que Google comprenne seul votre architecture est une stratégie perdante. Si votre site génère des millions d'URLs parasites, vous devez intervenir activement — noindex, robots.txt, canonical, désactivation de fonctionnalités. Ne comptez pas sur la clémence de l'algo.
Y a-t-il des exceptions où cette règle ne s'applique pas strictement ?
Oui. Les très gros sites (type marketplace, agrégateurs) avec une autorité forte bénéficient d'un budget de crawl bien plus généreux. Google accepte de crawler plusieurs millions d'URLs si le site démontre une forte demande utilisateur et un contenu diversifié.
Mais attention : même sur ces mastodontes, l'explosion incontrôlée d'URLs reste problématique. La différence, c'est qu'ils ont les ressources techniques pour monitorer et ajuster en continu. Pour un site standard, la marge de manœuvre est bien plus étroite.
Impact pratique et recommandations
Comment identifier si votre site est concerné par ce problème ?
Première étape : analysez vos logs serveur sur 30 jours minimum. Identifiez les patterns d'URLs les plus crawlées. Si Googlebot passe 60 % de son temps sur des URLs de filtrage, de pagination ou d'archives, vous avez un problème structurel.
Deuxième vérification : comparez le nombre d'URLs soumises dans votre sitemap avec le nombre d'URLs réellement stratégiques. Si vous envoyez 500 000 URLs alors que seules 20 000 ont une réelle valeur SEO, vous polluez votre propre crawl budget.
Quelles actions correctives appliquer immédiatement ?
Désactivez ou configurez strictement tout plugin générant des URLs paramétrées. Pour les filtres produits, utilisez du JavaScript côté client ou des canonical vers la page mère. Pour les calendriers, bloquez les URLs dynamiques via robots.txt si elles n'apportent aucune valeur.
Ensuite, nettoyez votre sitemap XML. Ne soumettez que les URLs à forte valeur SEO — fiches produits actives, articles récents, pages commerciales. Supprimez toutes les variantes, filtres, tris, et archives automatiques.
Quelles erreurs éviter absolument ?
Ne comptez pas sur le noindex seul pour résoudre le problème. Une balise noindex n'empêche pas le crawl — Googlebot visite quand même l'URL pour lire la directive. Si vous avez 10 millions d'URLs en noindex, vous gaspillez toujours du crawl budget.
Autre erreur fréquente : activer des plugins sans vérifier leur impact sur l'arborescence. Un module de calendrier peut générer des milliers d'URLs en quelques heures. Testez toujours en staging avant de déployer en production.
- Auditez vos logs serveur pour identifier les URLs sur-crawlées
- Comparez le volume d'URLs soumises vs. URLs stratégiques
- Désactivez ou reconfigurez les plugins générant des URLs infinies
- Utilisez canonical, robots.txt, ou JavaScript pour contrôler les variantes
- Nettoyez votre sitemap XML — seules les pages à valeur SEO
- Bloquez le crawl des URLs inutiles via robots.txt, pas seulement noindex
- Testez tout nouveau plugin en environnement de staging
La gestion du budget de crawl exige une vigilance constante et une maîtrise technique fine de votre architecture. Entre l'analyse des logs, le nettoyage des sitemaps, la configuration avancée de plugins et la gestion des directives robots, ces optimisations peuvent rapidement devenir complexes à orchestrer seul. Si votre site présente une architecture technique élaborée ou un volume d'URLs conséquent, il peut être judicieux de vous appuyer sur une agence SEO spécialisée pour un diagnostic approfondi et un plan d'action personnalisé qui préservera votre budget de crawl sans compromettre vos objectifs business.
❓ Questions frequentes
Le noindex suffit-il à économiser du budget de crawl ?
Combien d'URLs peut générer un plugin de filtrage produit ?
Les canonical résolvent-ils le problème de crawl des variantes ?
Comment savoir si mon budget de crawl est saturé ?
Un gros site a-t-il un budget de crawl illimité ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/06/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.