Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi Google ignore-t-il vos balises meta placées dans le <body> ?
- □ Pourquoi Google refuse-t-il les balises canonical placées dans le <body> ?
- □ Les balises hreflang dans le <body> sont-elles vraiment ignorées par Google ?
- □ Le code HTML valide W3C améliore-t-il vraiment le référencement ?
- □ Pourquoi modifier les canonicals en JavaScript crée-t-il des signaux contradictoires pour Google ?
- □ Faut-il optimiser les hints de préchargement pour Googlebot ?
- □ Le markup sémantique HTML5 est-il vraiment inutile pour le SEO ?
- □ La performance web améliore-t-elle vraiment votre référencement naturel ?
- □ Pourquoi Googlebot ignore-t-il vos hints de préchargement des ressources ?
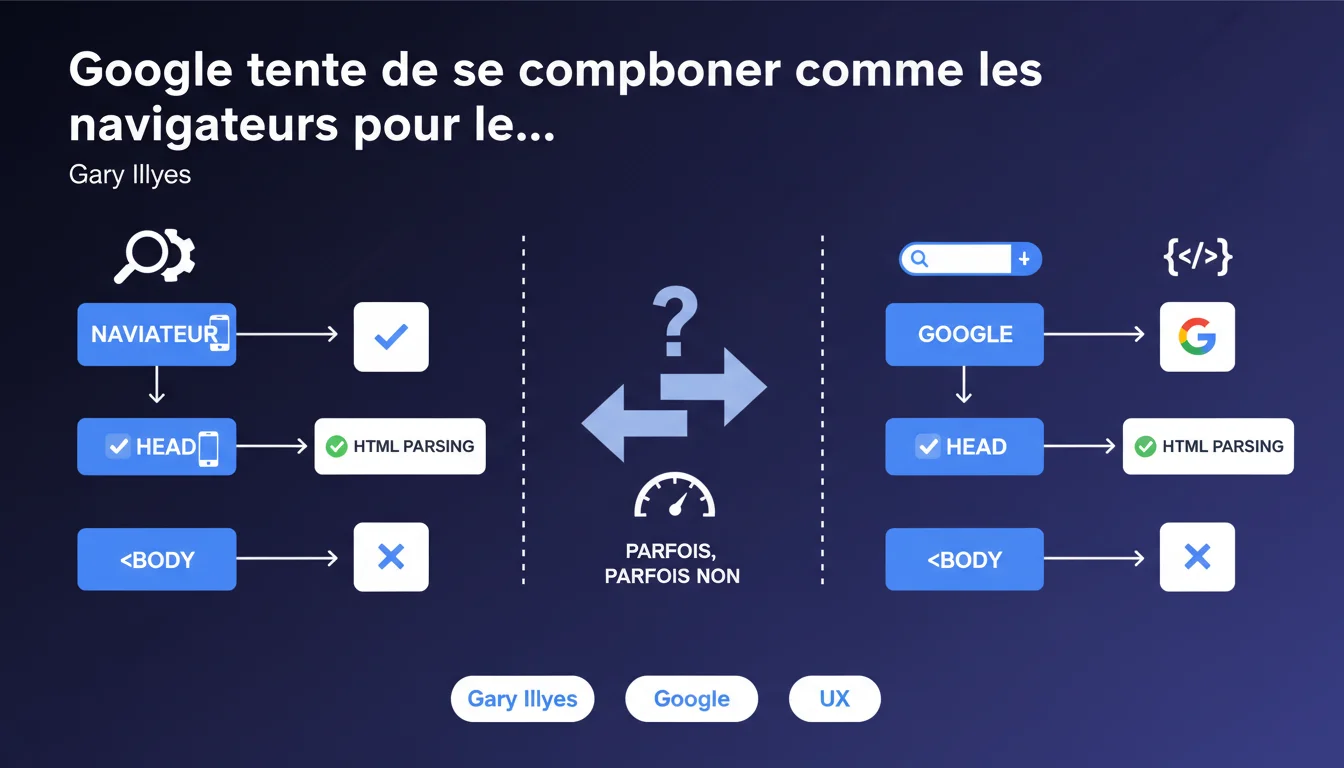
Google tente d'imiter le comportement des navigateurs lors du parsing HTML, mais n'y parvient pas toujours. Concrètement : les balises de métadonnées placées dans le <body> au lieu du <head> ne seront pas prises en compte par le moteur, même si le HTML5 tolère techniquement cette pratique.
Ce qu'il faut comprendre
Pourquoi Google cherche-t-il à imiter les navigateurs ?
L'objectif de Google est de comprendre les pages web telles qu'elles sont réellement affichées aux utilisateurs. Les navigateurs modernes (Chrome, Firefox, Safari) appliquent des règles de parsing HTML qui corrigent certaines erreurs de balisage et réorganisent le DOM.
Si Googlebot parsait le HTML différemment des navigateurs, il risquerait de mal interpréter le contenu ou de manquer des informations cruciales pour le classement. Cette approche vise donc la cohérence entre ce que voit l'utilisateur et ce qu'indexe le moteur.
Où se situe la limite de cette imitation ?
Gary Illyes l'admet sans détour : ça ne fonctionne pas toujours. Les moteurs de recherche ne reproduisent pas à 100% le comportement d'un navigateur — notamment pour des raisons de performance et de sécurité.
Le cas des balises de métadonnées illustre parfaitement cette limite. Alors que le standard HTML5 est permissif et que certains navigateurs acceptent des balises meta mal placées, Google applique une règle stricte : seules celles situées dans le <head> sont prises en compte.
Qu'est-ce que cela change pour le crawl et l'indexation ?
Cette déclaration rappelle que la position des balises meta compte. Une balise meta description ou meta robots dans le <body> sera tout simplement ignorée par Google, même si la page s'affiche correctement dans le navigateur.
C'est un piège courant avec les CMS mal configurés ou les frameworks JavaScript qui injectent dynamiquement des balises sans respecter la structure HTML canonique.
- Google tente de parser le HTML comme les navigateurs modernes, mais avec des limitations assumées
- Les balises de métadonnées doivent impérativement être dans le
<head>, pas dans le<body> - Le standard HTML5 tolère certaines erreurs que Google ne pardonne pas
- Les frameworks JavaScript et CMS peuvent générer des structures HTML non conformes aux attentes de Googlebot
Avis d'un expert SEO
Cette règle est-elle appliquée de manière cohérente par Google ?
Oui, sur ce point précis. Les tests terrain confirment que les balises meta placées hors du <head> sont systématiquement ignorées. Ce n'est pas une approximation — c'est un comportement documenté et stable depuis des années.
Ce qui est intéressant, c'est que Gary Illyes reconnaît ouvertement les limites du parsing de Google. Cette transparence tranche avec le flou habituel sur le fonctionnement interne du moteur. Mais attention — dire "ça fonctionne parfois, parfois non" reste délibérément vague sur les cas précis où le parsing échoue.
Quelles situations posent problème en pratique ?
Les frameworks JavaScript modernes (React, Vue, Angular) génèrent souvent du HTML dynamique qui peut déplacer ou dupliquer des balises meta lors du rendu. Si le SSR (Server-Side Rendering) est mal configuré, ces balises peuvent se retrouver dans le corps du document.
Autre cas fréquent : les plugins WordPress ou les systèmes de tag management qui injectent des balises meta via JavaScript après le chargement initial. Google peut crawler la page avant que ces modifications n'aient été appliquées au DOM.
Faut-il s'inquiéter des autres différences de parsing ?
La vraie question que cette déclaration soulève sans y répondre : quels autres écarts existent entre le parsing de Google et celui des navigateurs ? Gary Illyes ne donne aucun exemple concret au-delà des balises meta.
On sait par expérience que Google gère différemment certains attributs HTML5, que le support du JavaScript reste imparfait malgré les progrès, et que le rendu des CSS n'est pas toujours fiable. Mais Google reste délibérément flou sur ces zones grises. [À vérifier] au cas par cas selon vos configurations techniques.
Impact pratique et recommandations
Comment vérifier que mes balises meta sont correctement placées ?
Première étape : inspecter le code source HTML brut (Ctrl+U dans Chrome). Ne vous fiez pas à l'inspecteur d'éléments qui affiche le DOM après modifications JavaScript — vous devez voir ce que Googlebot reçoit initialement.
Utilisez l'outil "Inspection d'URL" dans Google Search Console pour afficher le HTML tel que Google le crawle. Vérifiez que toutes vos balises <meta> (description, robots, canonical, Open Graph, Twitter Cards) sont bien dans la section <head>.
Que faire si mon CMS ou framework génère du HTML non conforme ?
Pour les sites en JavaScript (React, Next.js, Nuxt), assurez-vous que le Server-Side Rendering ou le Static Site Generation est correctement configuré. Le HTML initial envoyé au serveur doit contenir toutes les balises meta critiques.
Avec WordPress, vérifiez que vos plugins SEO (Yoast, Rank Math, SEOPress) injectent bien les balises dans le <head>. Certains thèmes mal codés ou constructeurs de pages peuvent déplacer ces balises — auditez le rendu final après activation de tous vos plugins.
Quelles erreurs éviter absolument ?
Ne comptez jamais sur JavaScript côté client pour injecter des balises meta critiques (robots, canonical, hreflang). Même si Google exécute le JavaScript, il peut crawler la page avant que ces modifications ne soient appliquées.
Évitez les configurations où les balises meta sont dupliquées entre le <head> et le <body>. En cas de duplication, Google peut ignorer les deux ou privilégier celle du <head> — le comportement n'est pas documenté officiellement.
- Auditer le code source HTML brut de vos pages stratégiques
- Vérifier le rendu dans l'outil "Inspection d'URL" de Google Search Console
- Configurer correctement le SSR/SSG pour les frameworks JavaScript
- Tester le placement des balises meta après chaque modification de thème ou plugin
- Éviter l'injection de balises meta critiques via JavaScript côté client
- Documenter les exceptions et cas particuliers propres à votre stack technique
<head> reste une règle fondamentale que Google applique strictement. Même si le HTML5 tolère certaines libertés, Googlebot ne les accepte pas. Cette exigence peut sembler triviale, mais elle cache des enjeux techniques complexes selon votre architecture (JavaScript, CMS, CDN, tag management). Si vous identifiez des non-conformités ou souhaitez sécuriser votre implémentation technique, l'accompagnement d'une agence SEO spécialisée peut vous faire gagner un temps précieux et éviter des erreurs coûteuses en visibilité.❓ Questions frequentes
Les balises Open Graph et Twitter Cards doivent-elles aussi être dans le <head> ?
Google peut-il corriger automatiquement les balises meta mal placées ?
Comment savoir si mes balises meta sont prises en compte par Google ?
Les balises canonical et hreflang sont-elles concernées par cette règle ?
Un validateur HTML qui accepte ma page garantit-il que Google la parsera correctement ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 26/02/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.