Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi un site web bien conçu ne génère-t-il aucun trafic sans stratégie de découvrabilité ?
- □ Le Shadow DOM est-il un frein au référencement multi-moteurs ?
- □ Les fondamentaux techniques du SEO sont-ils vraiment aussi critiques qu'on le prétend ?
- □ Pourquoi votre SEO technique se dégrade-t-il sans maintenance continue ?
- □ Faut-il vraiment respecter la hiérarchie des balises Hn pour le SEO ?
- □ SEO et accessibilité : pourquoi Google insiste-t-il sur leur convergence ?
- □ La qualité finit-elle toujours par l'emporter dans les classements Google ?
- □ Pourquoi les Core Updates sabotent-elles vos tests SEO ?
- □ Faut-il vraiment privilégier l'utilisateur plutôt que l'optimisation technique en SEO ?
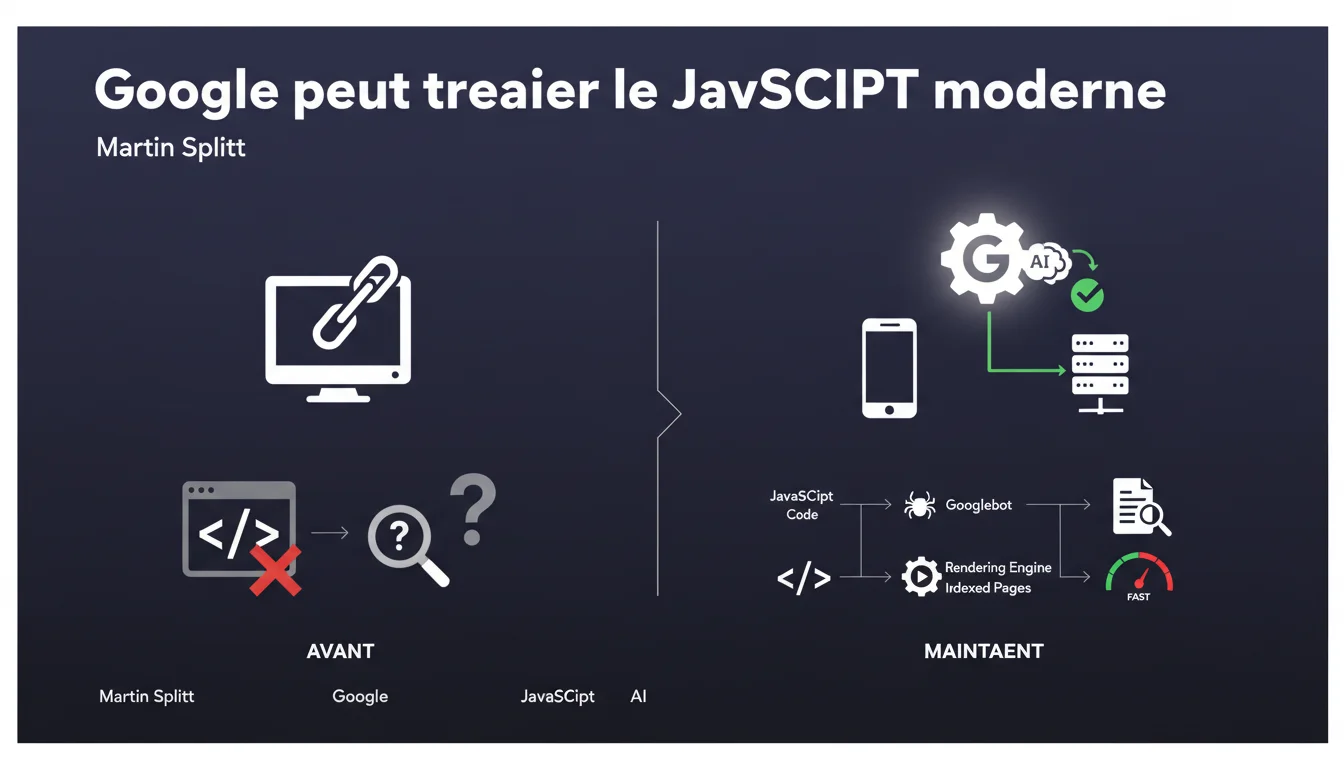
Google affirme traiter correctement le JavaScript moderne, balayant d'un revers de main les craintes héritées d'il y a 5 à 10 ans. Le crawling et l'indexation de contenus JS ne seraient donc plus un obstacle — une déclaration qui mérite d'être confrontée aux observations terrain, car tous les frameworks ne se valent pas.
Ce qu'il faut comprendre
Pourquoi cette déclaration maintenant ?
Martin Splitt, Search Relations Lead chez Google, prend position contre une idée reçue persistante : JavaScript bloquerait l'accès au contenu pour le moteur de recherche. Cette croyance, justifiée il y a une décennie, ne refléterait plus les capacités actuelles de Googlebot.
Le message sous-jacent ? Google veut rassurer les développeurs : adopter des frameworks JS modernes (React, Vue, Angular) ne condamne pas un site à l'invisibilité. Le moteur exécute désormais JavaScript et indexe le contenu rendu.
Qu'est-ce qui a changé techniquement chez Google ?
Googlebot s'appuie sur une version récente de Chromium pour rendre les pages. Contrairement aux premières années où le moteur se contentait du HTML brut, il exécute aujourd'hui le code client-side et accède au DOM final.
Cela signifie que les contenus générés dynamiquement — titres, textes, liens — peuvent être découverts et indexés. La limite résidait dans la file d'attente de rendu : certaines pages attendaient des jours avant d'être traitées. Cette contrainte s'est atténuée, selon Google.
Quels sont les points essentiels à retenir ?
- Le JavaScript moderne n'est plus un frein absolu à l'indexation, contrairement aux anciennes versions de Googlebot
- Google utilise un moteur de rendu basé sur Chromium pour exécuter le JS côté client
- Les contenus générés dynamiquement (titres, textes, liens) sont désormais accessibles au crawl
- La file d'attente de rendu reste un facteur, mais son impact a diminué selon Google
- Tous les frameworks JS ne se comportent pas de la même façon — certains facilitent le travail de Googlebot, d'autres compliquent l'indexation
Avis d'un expert SEO
Cette déclaration colle-t-elle à la réalité terrain ?
En partie. Google a effectivement progressé, c'est indéniable. Les sites React ou Vue bien conçus s'indexent correctement — on le constate tous les jours. Mais la nuance compte : « JavaScript moderne » ne signifie pas « tous les usages de JavaScript ».
Un site qui charge le contenu principal après plusieurs secondes, qui multiplie les appels API asynchrones ou qui utilise des SPA mal configurées rencontre encore des problèmes. Google peut traiter le JS, oui — mais dans des conditions optimales. Dès qu'on s'éloigne du cas d'école, les ratés apparaissent.
Où cette généralisation devient-elle problématique ?
Splitt ne précise pas les limites de tolérance : combien de temps Googlebot attend-il avant d'abandonner le rendu ? Quelle charge JS reste acceptable ? Quel impact sur le crawl budget pour un site de 10 000 pages ? [A vérifier] : ces zones grises obligent à tester plutôt qu'à se fier aveuglément à la déclaration.
Certains patterns restent toxiques : les infinite scroll mal implémentés, les contenus derrière un clic utilisateur obligatoire, les frameworks qui régénèrent le DOM à chaque navigation interne. Google peut traiter le JS — il ne veut pas faire de miracles pour compenser des choix d'architecture médiocres.
Faut-il abandonner le rendu côté serveur pour autant ?
Absolument pas. Le SSR ou le pré-rendu restent les solutions les plus robustes pour garantir l'indexation. Moins de dépendance au moteur de rendu de Google, moins de latence, meilleur contrôle du HTML initial — bref, moins de risques.
Cette déclaration ne dit pas « utilisez du JS sans limite », elle dit « le JS bien implémenté ne bloque plus l'indexation ». Nuance. Si tu peux livrer du HTML prêt à l'emploi, tu gardes la main. Si tu te reposes sur l'exécution client-side, tu dépends de la bonne volonté et des ressources de Googlebot.
Impact pratique et recommandations
Que faut-il vérifier concrètement sur son site ?
Commence par tester le rendu réel de tes pages dans la Search Console : URL Inspection Tool > Afficher la page explorée. Compare le HTML source et le HTML rendu. Si des éléments critiques (titres, contenus, liens internes) n'apparaissent que dans le rendu, tu dépends du moteur JS de Google.
Vérifie ensuite les logs serveur : combien de temps Googlebot passe-t-il sur tes pages ? Repasse-t-il plusieurs fois pour compléter l'indexation ? Un délai anormal entre le crawl initial et l'indexation finale signale un problème de rendu.
Quelles erreurs éviter absolument ?
Ne bloque jamais les ressources JS/CSS dans le robots.txt — Google en a besoin pour rendre correctement. Évite les SPA pures sans fallback HTML : si le contenu principal n'existe qu'après exécution du JS, tu joues avec le feu.
Méfie-toi aussi des contenus chargés après interaction utilisateur (clic, scroll infini) : Googlebot ne scrolle pas, ne clique pas sur les boutons « Voir plus ». Si un contenu stratégique se cache derrière ces mécanismes, il risque l'invisibilité.
Comment s'assurer que l'implémentation tient la route ?
- Tester chaque template critique avec l'outil d'inspection d'URL de la Search Console pour vérifier le rendu côté Google
- Comparer le HTML source et le HTML rendu : les contenus stratégiques doivent être présents dans les deux ou au minimum dans le rendu
- Analyser les logs serveur pour détecter les crawls incomplets ou les passages multiples de Googlebot sur les mêmes pages
- Mesurer les Core Web Vitals : un JS lourd ralentit le chargement et impacte le référencement indirect
- Privilégier le SSR, le pré-rendu ou l'hydratation pour les pages stratégiques plutôt que le rendu 100 % client-side
- Éviter les contenus cachés derrière des interactions utilisateur (clics, scroll infini) que Googlebot ne peut pas simuler
- Monitorer l'indexation réelle : une baisse du taux d'indexation peut signaler un problème de rendu JS
❓ Questions frequentes
Google indexe-t-il aussi bien le contenu JS que le contenu HTML statique ?
Tous les frameworks JavaScript modernes se valent-ils pour le SEO ?
Faut-il encore utiliser le pré-rendu ou le SSR si Google gère le JS ?
Comment vérifier que Googlebot exécute bien mon JavaScript ?
Quels types de contenus JS restent problématiques pour Google ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 09/02/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.