Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi un site web bien conçu ne génère-t-il aucun trafic sans stratégie de découvrabilité ?
- □ JavaScript moderne : Google peut-il vraiment tout indexer ?
- □ Le Shadow DOM est-il un frein au référencement multi-moteurs ?
- □ Pourquoi votre SEO technique se dégrade-t-il sans maintenance continue ?
- □ Faut-il vraiment respecter la hiérarchie des balises Hn pour le SEO ?
- □ SEO et accessibilité : pourquoi Google insiste-t-il sur leur convergence ?
- □ La qualité finit-elle toujours par l'emporter dans les classements Google ?
- □ Pourquoi les Core Updates sabotent-elles vos tests SEO ?
- □ Faut-il vraiment privilégier l'utilisateur plutôt que l'optimisation technique en SEO ?
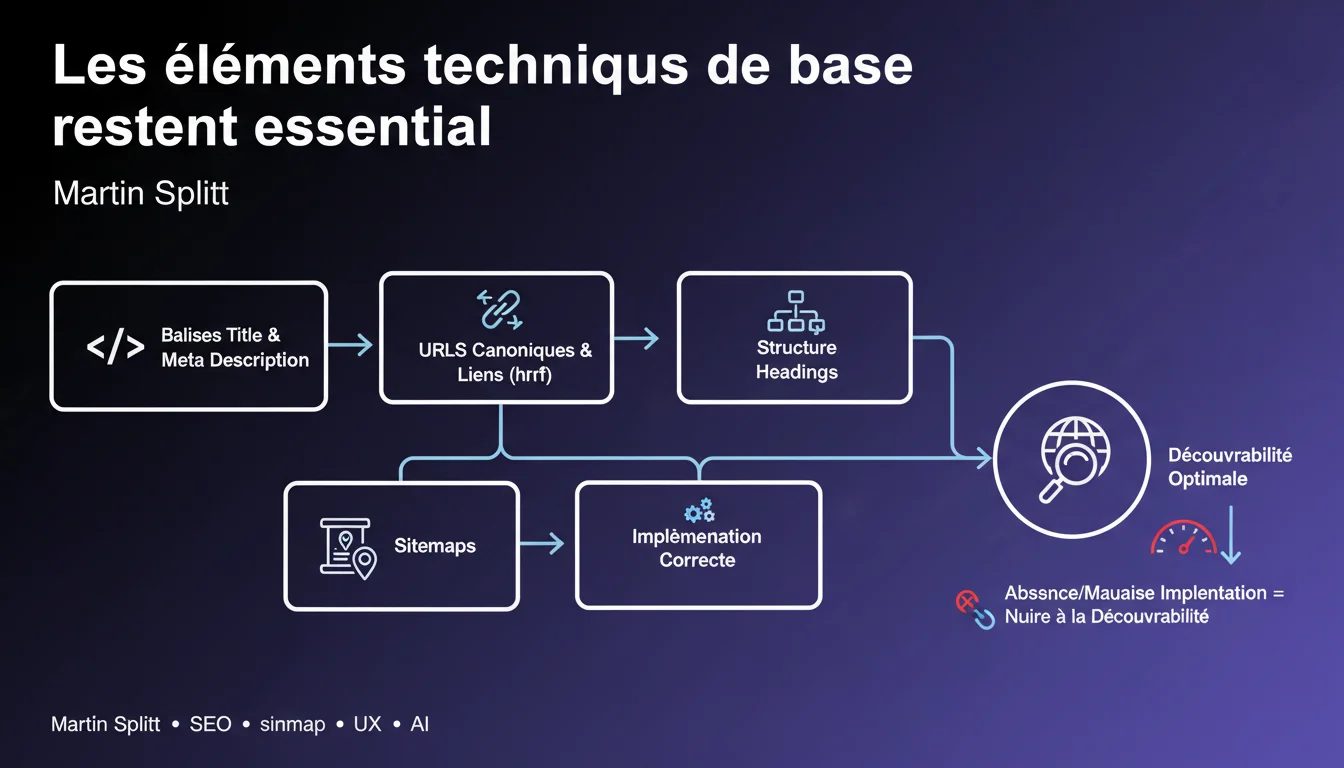
Martin Splitt rappelle que les bases techniques — balises title, meta description, URLs canoniques, liens href, headings et sitemaps — restent incontournables. Leur absence ou mauvaise implémentation nuit directement à la découvrabilité par Google. Pas de miracle sans fondations solides.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il encore sur ces éléments en 2025 ?
On pourrait croire qu'avec l'IA générative et les algorithmes de plus en plus sophistiqués, Google n'aurait plus besoin de ces marqueurs structurels basiques. Pourtant, Splitt le dit clairement : ces éléments techniques restent le socle sur lequel repose la découvrabilité d'un site.
La raison ? Le crawl et l'indexation demeurent des processus qui s'appuient sur des signaux explicites. Les balises title et meta description orientent la compréhension des pages. Les URLs canoniques évitent les duplications. Les liens avec attributs href permettent au bot de naviguer. Sans ça, Google tâtonne — ou passe son chemin.
Qu'est-ce que Splitt entend exactement par « découvrabilité » ?
Il ne parle pas de ranking, mais de la capacité de Google à trouver, comprendre et indexer vos pages. Une page invisible dans l'index ne peut pas ranker, aussi bon soit son contenu. C'est la différence entre « être vu » et « être bien classé ».
Les sitemaps facilitent l'exploration. Les headings structurent le contenu pour l'algorithme. Les liens internes avec href créent un graphe navigable. Ces éléments ne garantissent pas un bon positionnement, mais leur absence vous exclut de la course.
Cette déclaration est-elle une révélation ou un rappel ?
Soyons honnêtes : rien de nouveau sous le soleil. Splitt ne fait que rappeler ce que tout SEO sait depuis quinze ans. Mais le fait qu'il le réaffirme en dit long sur la persistance des erreurs terrain.
Beaucoup de sites, notamment en JavaScript ou sur des CMS mal configurés, négligent encore ces bases. Le rappel de Google n'est pas anodin — il cible probablement une réalité observée à grande échelle dans leurs crawls.
- Les balises title et meta description restent des signaux de compréhension et d'affichage essentiels
- Les URLs canoniques évitent les duplications et clarifient la version préférée
- Les liens avec href permettent au bot de naviguer efficacement
- La structure des headings aide Google à comprendre la hiérarchie du contenu
- Les sitemaps accélèrent la découverte, surtout pour les gros sites
- L'absence ou la mauvaise implémentation de ces éléments nuit directement à l'indexation
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, sans réserve. Les audits SEO révèlent régulièrement des sites avec des titles dupliqués, des canoniques mal configurées, ou pire : des liens JavaScript sans href. Ces sites peinent à être crawlés correctement, même quand leur contenu est solide.
Ce qui surprend, c'est que Google doive encore le marteler. Mais dans les faits, beaucoup de développeurs — surtout ceux qui bossent sur des frameworks front-end — ignorent ces contraintes. Ils pensent que le SEO, c'est du contenu et des backlinks. Faux. Sans structure technique, vous êtes invisible.
Quelles nuances faut-il apporter à cette déclaration ?
Splitt parle de « découvrabilité », pas de ranking. C'est crucial. Avoir des balises title parfaites ne vous fera pas monter dans les SERPs si votre contenu est médiocre ou votre autorité nulle. Ces éléments sont nécessaires, pas suffisants.
Autre nuance : la meta description. Google la réécrit souvent, on le sait. Mais son absence ou son inconsistance envoie un signal de négligence éditoriale. C'est moins un facteur de ranking qu'un marqueur de qualité globale du site. [A vérifier] : l'impact direct de la meta description sur le CTR reste difficile à isoler des autres facteurs SERP.
Dans quels cas ces règles peuvent-elles être assouplies ?
Rarement, pour être franc. Même les sites à fort budget crawl doivent respecter ces fondamentaux. Le seul cas limite concerne les sites ultra-autoritaires (type Amazon, Wikipedia) où Google compense les lacunes techniques par la force brute du crawl et de l'autorité.
Mais pour 99 % des sites, tenter de contourner ces bases, c'est se tirer une balle dans le pied. Les sitemaps, par exemple, ne sont « optionnels » que pour les très petits sites avec un maillage parfait — autant dire jamais.
Impact pratique et recommandations
Que faut-il vérifier en priorité sur son site ?
Commence par un crawl complet avec Screaming Frog ou un outil similaire. Identifie les pages sans title, avec des titles dupliqués, ou sans meta description. Ces erreurs sont fréquentes et faciles à corriger — mais encore faut-il les détecter.
Ensuite, vérifie tes URLs canoniques. Beaucoup de sites ont des canonical qui pointent vers des pages 404, ou des boucles de canonicalisation. Google Search Console te signalera ces problèmes dans la section « Couverture ».
Enfin, teste tes liens internes. Si tu utilises du JavaScript pour générer des liens, assure-toi qu'ils ont un attribut href réel. Le test : désactive JavaScript dans ton navigateur et clique sur tes liens. S'ils ne fonctionnent plus, Googlebot ne les suivra probablement pas.
Quelles erreurs éviter absolument ?
Ne laisse jamais de pages importantes sans balise title. C'est le signal le plus basique que Google utilise pour comprendre de quoi parle une page. Un title manquant ou générique (« Page sans titre », « Accueil ») est un suicide SEO.
Évite aussi les canoniques en cascade : page A → canonical vers B → canonical vers C. Google peut suivre, mais c'est inefficient et source d'erreurs. Pointe toujours directement vers la version canonique finale.
Et surtout, ne néglige pas les sitemaps sur les gros sites. Beaucoup pensent qu'un bon maillage suffit. Faux. Les sitemaps accélèrent la découverte et permettent à Google de prioriser le crawl des pages importantes.
Comment s'assurer que tout est conforme ?
- Crawl complet du site avec Screaming Frog ou Sitebulb pour identifier les titles/metas manquants ou dupliqués
- Audit des URLs canoniques via Google Search Console, section « Couverture »
- Test des liens internes : désactiver JavaScript et vérifier la navigation
- Validation de la structure des headings (H1 unique par page, hiérarchie logique H2-H3)
- Vérification des sitemaps XML : présence, validité, soumission dans GSC
- Monitoring régulier des erreurs 404 et des redirections vers des canoniques
- Contrôle du rendu côté serveur pour les frameworks JavaScript (SSR ou pré-rendu)
❓ Questions frequentes
Les meta descriptions sont-elles encore utiles si Google les réécrit souvent ?
Un site en JavaScript pur peut-il ranker sans SSR ou pré-rendu ?
Faut-il absolument un sitemap XML même pour un petit site ?
Peut-on utiliser des canoniques cross-domain en toute sécurité ?
Les headings H2-H6 ont-ils encore un poids SEO significatif ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 09/02/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.