Declaration officielle
Ce qu'il faut comprendre
À quel moment Google détecte-t-il le duplicate content ?
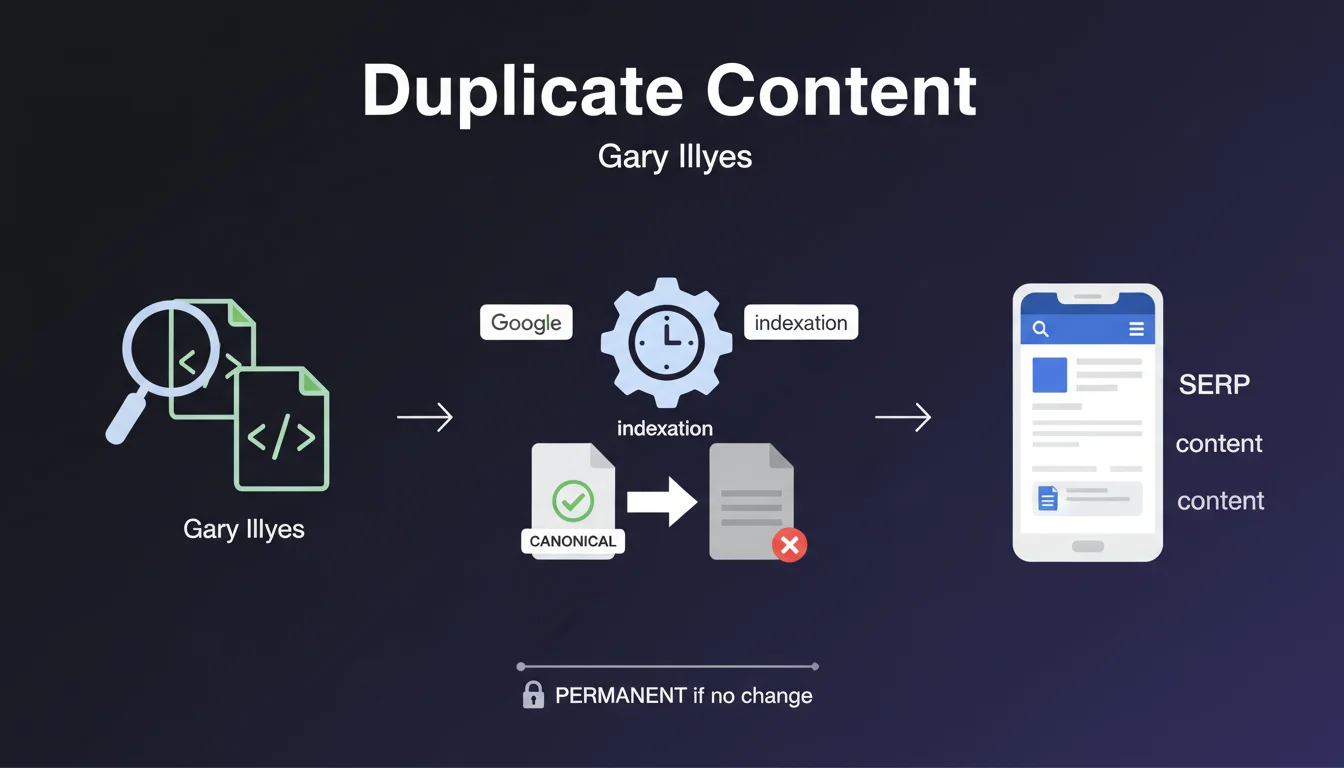
Google analyse le duplicate content au moment de l'indexation, pas lors du crawl ou du classement. Cette distinction est cruciale pour comprendre le processus.
Lorsque Googlebot indexe une page, il la compare avec les autres pages déjà présentes dans son index. Si une page est identifiée comme canonique (originale) à ce moment-là, elle conserve ce statut de manière permanente, sauf modification ultérieure du contenu ou des signaux.
Comment se fait la comparaison de contenu ?
L'analyse repose sur une comparaison globale de pages, pas sur une simple analyse de mots-clés isolés. Google examine la structure, le contenu textuel, et l'ensemble des éléments constitutifs de la page.
Cette approche holistique permet à Google de détecter les duplications même lorsque des variations mineures sont introduites (synonymes, réorganisation de paragraphes). Le moteur évalue la similarité globale plutôt que des correspondances exactes de termes.
Que signifie le message de fin de SERP sur les résultats omis ?
Le lien "afficher les résultats omis" en bas des pages de résultats répond à un mécanisme différent de la détection du duplicate content à l'indexation. Ce filtre est appliqué dynamiquement en fonction de la requête.
- Détection à l'indexation : permanente, définit la page canonique
- Comparaison page par page : analyse holistique du contenu, pas juste des mots-clés
- Filtre en SERP : mécanisme distinct, dépendant de la requête utilisateur
- Statut canonique : stable une fois attribué, sauf changement majeur
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Cette explication correspond effectivement aux comportements observés par les professionnels SEO depuis des années. Le fait que la canonicalisation soit définie à l'indexation explique pourquoi il est difficile de "reprendre" le statut de page originale une fois qu'un concurrent a indexé le contenu en premier.
Toutefois, l'affirmation que le statut canonique est "permanent" mérite nuance. En pratique, des modifications substantielles de contenu, des changements de signaux (liens, autorité), ou une réindexation forcée peuvent faire basculer Google vers une nouvelle page canonique.
Quelles zones d'ombre subsistent dans cette explication ?
Gary Illyes simplifie volontairement un processus complexe. La réalité implique de nombreux signaux additionnels : les balises canonical, la structure des URLs, l'ancienneté du domaine, les backlinks pointant vers chaque version, et les données utilisateurs.
Le timing est également critique : si votre contenu est indexé quelques heures après un scraperbot, vous risquez de perdre le statut canonique même si vous êtes l'auteur original. C'est un problème récurrent pour les sites à faible fréquence de crawl.
Le filtre SERP est-il vraiment si différent du duplicate content classique ?
La distinction entre détection à l'indexation et filtrage en SERP révèle que Google utilise en réalité deux couches de traitement. La première est structurelle (quelle page entre dans l'index comme référence), la seconde est contextuelle (quelles variations afficher selon la requête).
Cette double approche explique pourquoi vous pouvez parfois voir des variations de votre propre contenu apparaître selon les requêtes, même si Google a bien identifié votre page comme canonique. Le contexte de recherche influence la pertinence perçue de chaque version.
Impact pratique et recommandations
Comment protéger son contenu du duplicate content négatif ?
La priorité absolue est d'optimiser la vitesse d'indexation de vos nouveaux contenus. Plus Google indexe rapidement votre page originale, moins vous risquez qu'un copieur soit considéré comme source canonique.
Utilisez systématiquement les balises canonical sur vos propres variations de contenu (versions imprimables, pagination, paramètres URL). Cela guide explicitement Google vers votre version préférée.
- Soumettre immédiatement les nouveaux contenus via Google Search Console (inspection d'URL)
- Implémenter un système de ping automatique vers Google lors de publication
- Configurer correctement les balises canonical sur toutes les pages à variations
- Surveiller l'indexation avec des outils comme Oncrawl ou Botify
- Optimiser le crawl budget en éliminant les pages inutiles et les redirections
Que faire si votre contenu est dupliqué par un tiers ?
Si vous constatez qu'un site copie systématiquement votre contenu et obtient un meilleur positionnement, plusieurs actions correctives sont possibles. La première est d'utiliser le rapport DMCA de Google pour signaler la violation de droits d'auteur.
Renforcez les signaux d'autorité de votre page originale : obtenez des backlinks de qualité, augmentez le maillage interne, enrichissez le contenu avec des éléments uniques (vidéos, infographies, données exclusives). Ces signaux aident Google à réévaluer quelle version devrait être canonique.
- Déposer une réclamation DMCA via le formulaire officiel de Google
- Contacter le webmaster du site copieur pour demander un lien vers votre source
- Enrichir votre contenu original avec des éléments différenciants
- Obtenir des backlinks pointant spécifiquement vers votre version
- Utiliser des horodatages et schémas structured data pour marquer l'antériorité
Comment auditer et corriger les problèmes de duplicate content interne ?
Un audit technique approfondi est indispensable pour identifier toutes les sources de duplication interne : facettes de filtres, sessions utilisateurs dans les URLs, versions HTTP/HTTPS, www/non-www, trailing slash, etc.
La correction nécessite une approche méthodique combinant redirections 301, balises canonical, paramètres dans Search Console, et optimisation du fichier robots.txt. Chaque situation requiert une stratégie spécifique selon l'architecture du site.
- Crawler le site pour identifier toutes les URLs indexables et leurs variations
- Mapper les contenus similaires et définir la version canonique pour chaque groupe
- Implémenter les redirections 301 pour les duplications complètes
- Ajouter les balises canonical pour les variations légitimes à conserver
- Configurer les paramètres d'URL dans Google Search Console
- Vérifier la cohérence des liens internes vers les versions canoniques
La gestion du duplicate content exige une vigilance constante et une compréhension fine des mécanismes d'indexation de Google. Entre la course à l'indexation, la configuration technique, et la surveillance des copies externes, les points de vigilance sont nombreux.
Ces optimisations touchent à des aspects techniques sensibles de votre site et peuvent avoir des conséquences importantes sur votre visibilité. Pour les sites complexes ou les situations délicates où du contenu a été dupliqué, l'accompagnement par une agence SEO spécialisée permet d'éviter les erreurs coûteuses et de mettre en place une stratégie de protection sur mesure, adaptée à votre écosystème et vos enjeux spécifiques.
💬 Commentaires (0)
Soyez le premier à commenter.