Declaration officielle
Ce qu'il faut comprendre
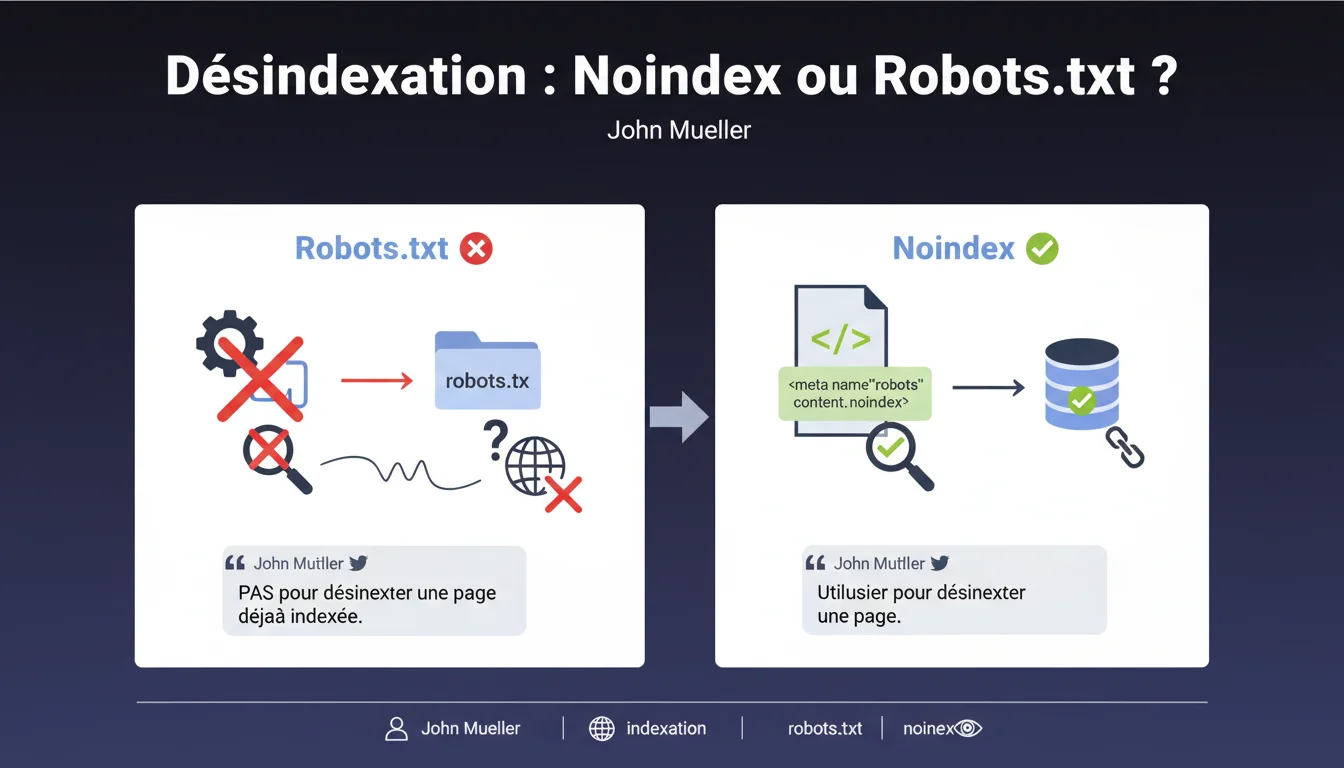
Quelle est la différence fondamentale entre robots.txt et noindex pour la désindexation ?
Le fichier robots.txt bloque le crawl des pages par Googlebot, empêchant le robot d'accéder au contenu. En revanche, la balise meta noindex autorise le crawl mais demande explicitement à Google de retirer la page de son index.
Cette distinction est cruciale : si une page est déjà indexée et que vous la bloquez via robots.txt, Google ne pourra plus la crawler pour lire l'instruction de désindexation. La page restera donc visible dans les résultats de recherche avec un snippet générique peu engageant.
Pourquoi le robots.txt seul est-il inefficace pour désindexer une page existante ?
Lorsqu'une URL est bloquée par robots.txt mais déjà connue de Google, le moteur conserve cette URL dans son index sans pouvoir mettre à jour son statut. Vous verrez apparaître des messages d'erreur dans la Search Console indiquant que la page est indexée mais non explorée.
Google maintient ces URLs dans l'index car il détecte des liens externes pointant vers elles ou les trouve dans son historique de crawl. Sans accès au contenu, il ne peut pas traiter une éventuelle directive noindex.
Dans quel ordre faut-il procéder pour une désindexation propre ?
La méthodologie recommandée suit une séquence précise en deux temps. D'abord, ajoutez la balise meta noindex sur la page tout en la laissant accessible au crawl. Attendez que Google la crawle et la retire de l'index.
Une fois la désindexation confirmée dans la Search Console, vous pouvez optionnellement bloquer le crawl via robots.txt pour économiser le budget de crawl. Cette approche garantit une suppression complète de l'index sans laisser de traces.
- Robots.txt bloque le crawl mais ne désindexe pas les pages déjà présentes dans l'index
- Meta noindex nécessite que la page soit crawlable pour être traitée efficacement
- L'ordre correct est : noindex d'abord, puis robots.txt optionnel ensuite
- Une page bloquée par robots.txt peut rester visible dans les SERP avec un snippet limité
- La Search Console signale les pages indexées mais bloquées par robots.txt comme des anomalies
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les pratiques observées sur le terrain ?
Absolument. Les audits SEO révèlent régulièrement des sites avec des centaines d'URLs indexées mais bloquées par robots.txt, créant une pollution de l'index. Ces pages affichent le message « Aucune information disponible pour cette page » dans les résultats.
Cette situation nuit à la perception de qualité du site par Google et les utilisateurs. Les tests montrent qu'une désindexation propre via noindex est traitée en 2 à 4 semaines selon la fréquence de crawl, tandis que le blocage robots.txt perpétue le problème indéfiniment.
Quelles nuances faut-il apporter à cette règle générale ?
Pour les pages jamais indexées, le robots.txt peut être utilisé directement comme mesure préventive. C'est utile pour les zones administratives, les résultats de recherche interne ou les paramètres d'URL inutiles que vous ne voulez jamais voir apparaître.
En revanche, pour du contenu sensible déjà indexé, la suppression d'urgence via l'outil de désindexation temporaire de la Search Console est plus rapide que le noindex classique. Le noindex reste ensuite nécessaire pour pérenniser la désindexation.
Dans quels cas cette approche peut-elle rencontrer des limites ?
Les sites avec un budget de crawl très limité peuvent voir la désindexation par noindex prendre plusieurs mois si les pages concernées sont rarement visitées par Googlebot. Dans ce cas, utiliser l'outil d'inspection d'URL pour forcer le recrawl accélère significativement le processus.
Pour les sites victimes de scraping massif où des milliers de pages dupliquées sont indexées ailleurs, la stratégie diffère. Il faut combiner noindex, canonical, et parfois des actions DMCA selon la gravité de la situation.
Impact pratique et recommandations
Que faut-il faire concrètement pour désindexer proprement des pages existantes ?
Commencez par identifier toutes les URLs à désindexer via un crawl complet de votre site et une extraction depuis la Search Console. Segmentez-les par type pour appliquer des solutions techniques adaptées à chaque catégorie.
Ajoutez ensuite la balise <meta name="robots" content="noindex, follow"> dans le <head> de chaque page concernée. Le paramètre "follow" permet à Google de continuer à découvrir d'autres pages via les liens présents.
Utilisez l'outil d'inspection d'URL de la Search Console pour forcer le recrawl des pages prioritaires. Surveillez ensuite le rapport de couverture d'index pour confirmer que le statut passe de "Indexé" à "Exclu par la balise noindex".
Quelles erreurs critiques faut-il absolument éviter ?
L'erreur la plus dangereuse consiste à bloquer par robots.txt une page déjà indexée en pensant la faire disparaître. Non seulement elle reste visible, mais vous perdez le contrôle sur son snippet et ne pouvez plus la mettre à jour.
Autre piège fréquent : supprimer physiquement les pages ou renvoyer un code 410 Gone trop rapidement. Google met plus de temps à désindexer une page en erreur qu'une page avec noindex clairement affiché. Gardez le contenu accessible avec noindex pendant au moins 4 à 6 semaines.
Comment vérifier et maintenir une politique de désindexation saine ?
Configurez un monitoring mensuel dans la Search Console pour détecter les pages "Indexées, mais bloquées par le fichier robots.txt". Ce rapport révèle immédiatement les incohérences entre votre stratégie de crawl et d'indexation.
Documentez votre processus de désindexation dans un guide interne pour que toutes les équipes (dev, SEO, contenu) appliquent la même méthodologie. Les migrations et refontes sont des moments critiques où ces erreurs se multiplient.
- Auditer l'index actuel et identifier les pages à désindexer par catégorie
- Implémenter la balise meta noindex sur les pages concernées avant tout blocage
- Laisser les pages accessibles au crawl pendant la phase de désindexation
- Forcer le recrawl via la Search Console pour accélérer le traitement
- Surveiller le rapport de couverture jusqu'à confirmation du statut "Exclu par noindex"
- Optionnel : bloquer ensuite par robots.txt uniquement si nécessaire pour le budget crawl
- Éviter absolument de combiner robots.txt et noindex simultanément
- Conserver les pages avec noindex pendant 4 à 6 semaines minimum avant suppression
- Mettre en place un monitoring mensuel des conflits robots.txt/indexation
💬 Commentaires (0)
Soyez le premier à commenter.