Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Comment la série Ecommerce Essentials de Google révolutionne-t-elle l'approche technique du SEO ?
- □ Le nouveau rapport vidéo Search Console va-t-il changer la donne pour le SEO vidéo ?
- □ Comment survivre à une Core Update de Google sans perdre tout son trafic ?
- □ Pourquoi Google confirme-t-il publiquement certaines Core Updates et pas d'autres ?
- □ Faut-il encore s'embêter avec les balises d'extension de sitemap ?
- □ Faut-il connecter Search Console à Data Studio pour optimiser ses performances SEO ?
- □ Comment Google a-t-il réellement adapté sa lutte anti-spam ces dernières années ?
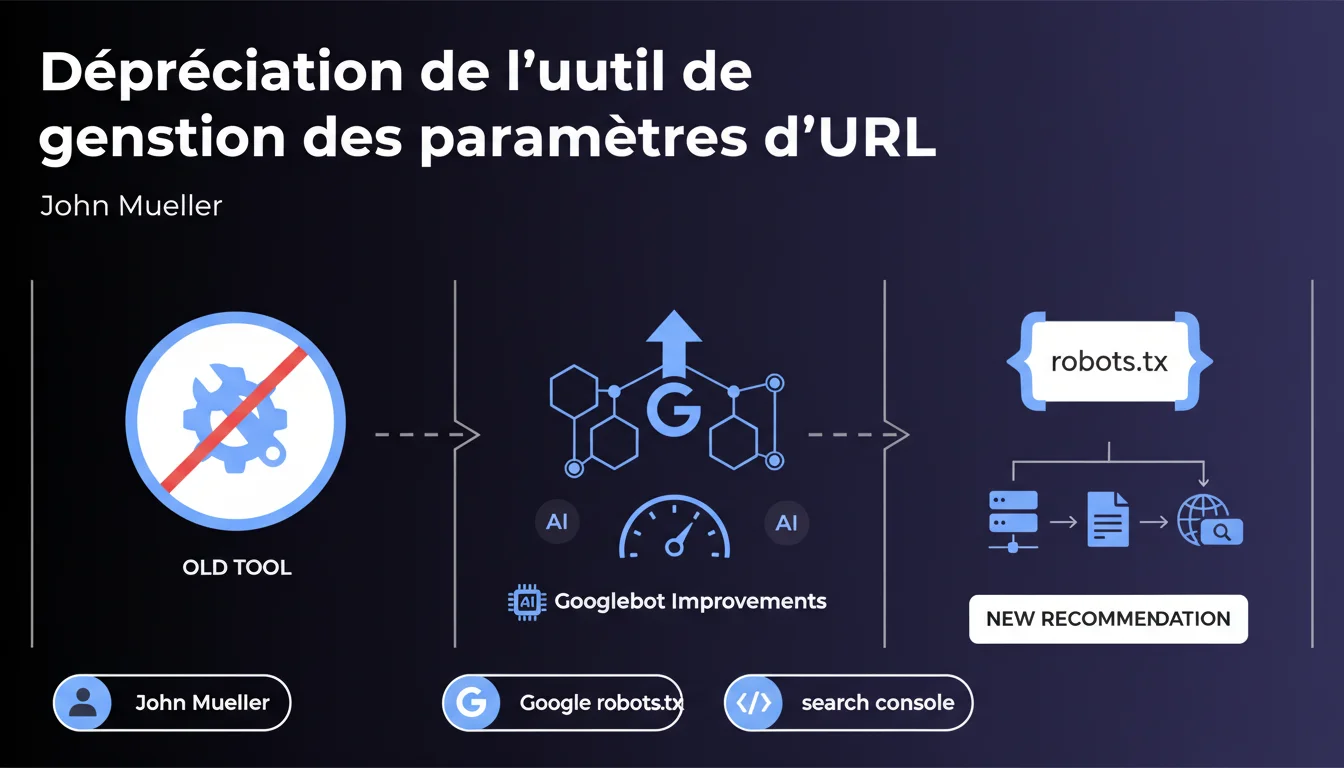
Google supprime l'outil de gestion des paramètres d'URL de Search Console, estimant que ses algorithmes d'exploration sont désormais assez performants pour gérer les URLs paramétrées sans aide manuelle. Le fichier robots.txt devient la seule option officielle pour contrôler l'exploration des URLs à paramètres. Ce changement force les SEO à revoir leur stratégie de gestion des facettes, filtres et sessions.
Ce qu'il faut comprendre
Pourquoi Google retire-t-il cet outil maintenant ?
Depuis des années, l'outil de gestion des paramètres d'URL permettait d'indiquer à Google comment traiter les URLs contenant des paramètres : lesquelles explorer activement, lesquelles ignorer, quels paramètres changeaient le contenu de la page. Un gain de temps précieux pour éviter de gaspiller du crawl budget sur des milliers d'URLs générées par des filtres ou des sessions.
Selon Mueller, les systèmes d'exploration de Google auraient tellement progressé que cet outil serait devenu superflu. Traduction : Google estime pouvoir identifier seul les patterns d'URLs à ignorer ou prioriser, sans qu'on ait besoin de lui mâcher le travail.
Quelle alternative concrète Google propose-t-il ?
La recommandation officielle : utiliser le fichier robots.txt pour bloquer l'exploration des URLs paramétrées problématiques. Techniquement faisable avec des wildcards et des patterns, mais nettement moins granulaire que l'ancien outil.
Le problème ? Robots.txt bloque l'exploration, point. Il ne permet pas de dire "explore cette URL mais ne l'indexe pas" ou "ce paramètre change le contenu, celui-là non". C'est du tout ou rien, là où l'outil de gestion offrait une palette de nuances.
Quels sites sont les plus impactés par ce changement ?
Les sites e-commerce avec navigation à facettes complexes sont en première ligne. Ceux qui généraient des centaines de milliers d'URLs via des combinaisons de filtres (couleur + taille + prix + marque) perdent un levier de contrôle fin.
Les plateformes avec gestion de sessions en URL, les sites multilingues avec paramètres de langue redondants, ou les catalogues avec options de tri multiples voient également leur marge de manœuvre réduite.
- L'outil de gestion des paramètres d'URL disparaît de Search Console
- Google estime que ses algorithmes gèrent mieux les URLs paramétrées qu'avant
- Robots.txt devient l'unique méthode recommandée pour contrôler l'exploration
- Cette transition force une approche moins granulaire et plus binaire (exploration bloquée ou autorisée)
- Les sites avec navigation à facettes perdent un outil de pilotage précis du crawl budget
Avis d'un expert SEO
Cette confiance de Google dans ses algorithmes est-elle justifiée sur le terrain ?
Soyons honnêtes : Google a effectivement progressé dans sa capacité à détecter les patterns d'URLs dupliquées ou sans valeur. Les observations montrent qu'il ignore de plus en plus souvent les URLs de tri ou de pagination évidentes sans qu'on ait besoin de le lui dire.
Mais — et c'est là que ça coince — cette intelligence n'est pas uniforme selon les types de sites. Sur des architectures e-commerce complexes avec filtres combinés, Google continue régulièrement d'explorer des milliers d'URLs inutiles qu'un paramétrage manuel aurait évitées. [A vérifier] : l'affirmation que "les systèmes se sont considérablement améliorés" manque de données chiffrées sur les taux d'amélioration réels.
Robots.txt peut-il vraiment remplacer l'outil de gestion des paramètres ?
Non, et c'est une simplification dangereuse de la part de Google. Bloquer en robots.txt empêche l'exploration ET le passage de PageRank — ce qui peut être contre-productif si certaines URLs paramétrées ont de la valeur ou reçoivent des liens externes.
L'ancien outil permettait de dire "crawle sans indexer" ou "ce paramètre change le contenu, traite chaque variation comme unique". Robots.txt ne permet rien de tout ça. C'est comme remplacer un scalpel par une hache.
Dans quels cas cette approche robotstxt-only pose-t-elle problème ?
Cas concret : un site marchand reçoit des liens externes vers des URLs avec paramètres UTM ou de tracking. Bloquer ces patterns en robots.txt empêche Google de suivre ces liens et de transmettre leur autorité aux pages cibles.
Autre scénario problématique : les sites qui utilisent des paramètres pour gérer des variations de contenu légèrement différentes (ex: affichage liste vs grille, avec ou sans stock). Impossible de dire à Google "traite ces variations comme identiques" sans l'outil de gestion — il faut maintenant choisir entre tout explorer ou tout bloquer.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette dépréciation ?
Première étape : exporter vos paramètres configurés dans l'outil avant sa disparition complète si ce n'est déjà fait. Documentez quels paramètres vous aviez marqués comme "change le contenu", "ne change pas le contenu", ou "pagination".
Ensuite, analysez vos logs serveur sur 30-90 jours pour identifier quels paramètres Google explore réellement et en quelle quantité. Comparez avec vos anciennes configurations : si Google respectait vos directives, la transition sera délicate.
Comment adapter sa stratégie de crawl budget sans l'outil ?
Pour les paramètres clairement inutiles (sessions, tracking interne, tris redondants), une directive robots.txt avec wildcard fait l'affaire : Disallow: /*?sort= ou Disallow: /*?sessionid=.
Pour les cas plus nuancés, il faut combiner plusieurs leviers : canonical tags pour regrouper les variations, noindex sur les combinaisons de facettes trop profondes, et pagination avec rel=next/prev ou View All si pertinent. Le pilotage devient multi-canal au lieu d'être centralisé dans un seul outil.
Les sites avec navigation à facettes complexes doivent repenser leur architecture : limiter le nombre de niveaux de filtres combinables, implémenter du JavaScript côté client pour les filtres secondaires (avec fallback accessible), ou créer des landing pages statiques pour les combinaisons populaires.
Quelles erreurs éviter dans cette transition ?
Erreur classique : bloquer en masse tous les paramètres en robots.txt par précaution. Résultat : des pages légitimes deviennent inaccessibles, du trafic organique s'effondre sur des requêtes de longue traîne qui passaient par des URLs paramétrées.
Autre piège : ne rien faire en se disant "Google gère tout seul maintenant". Sur des sites de taille moyenne à grande, l'inaction mène à un gaspillage continu de crawl budget et potentiellement à des problèmes de duplicate content si les canonicals ne sont pas parfaitement configurées.
- Exporter et documenter vos configurations actuelles de paramètres d'URL avant la fermeture de l'outil
- Analyser les logs serveur pour mesurer l'impact réel des paramètres sur votre crawl budget
- Identifier les paramètres strictement inutiles (sessions, tracking) et les bloquer via robots.txt
- Auditer vos canonical tags pour s'assurer qu'elles couvrent bien toutes les variations paramétrées
- Implémenter des noindex sur les combinaisons de facettes profondes ou peu pertinentes
- Vérifier dans Search Console que les URLs bloquées n'ont pas de backlinks externes avant d'appliquer robots.txt
- Monitorer l'évolution du nombre de pages explorées et indexées après chaque changement
- Revoir l'architecture des sites à facettes pour réduire la génération d'URLs paramétrées inutiles
❓ Questions frequentes
L'outil de gestion des paramètres d'URL est-il déjà supprimé ou peut-on encore l'utiliser ?
Si je bloque des paramètres en robots.txt, est-ce que Google peut quand même indexer ces URLs ?
Comment gérer des URLs paramétrées qui reçoivent des backlinks externes ?
Les filtres de navigation à facettes doivent-ils tous être bloqués en robots.txt maintenant ?
Google détecte-t-il vraiment mieux les URLs paramétrées inutiles qu'avant ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 23/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.