Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Le cache Google est-il indispensable pour être indexé et apparaître dans les résultats de recherche ?
- □ Faut-il vraiment se fier aux pages en cache pour diagnostiquer l'indexation ?
- □ Pourquoi certaines pages ne sont-elles pas mises en cache par Google ?
- □ Pourquoi le cache Google n'affiche-t-il pas toujours vos pages JavaScript complètes ?
- □ Faut-il s'inquiéter si Google ne met pas vos pages en cache ?
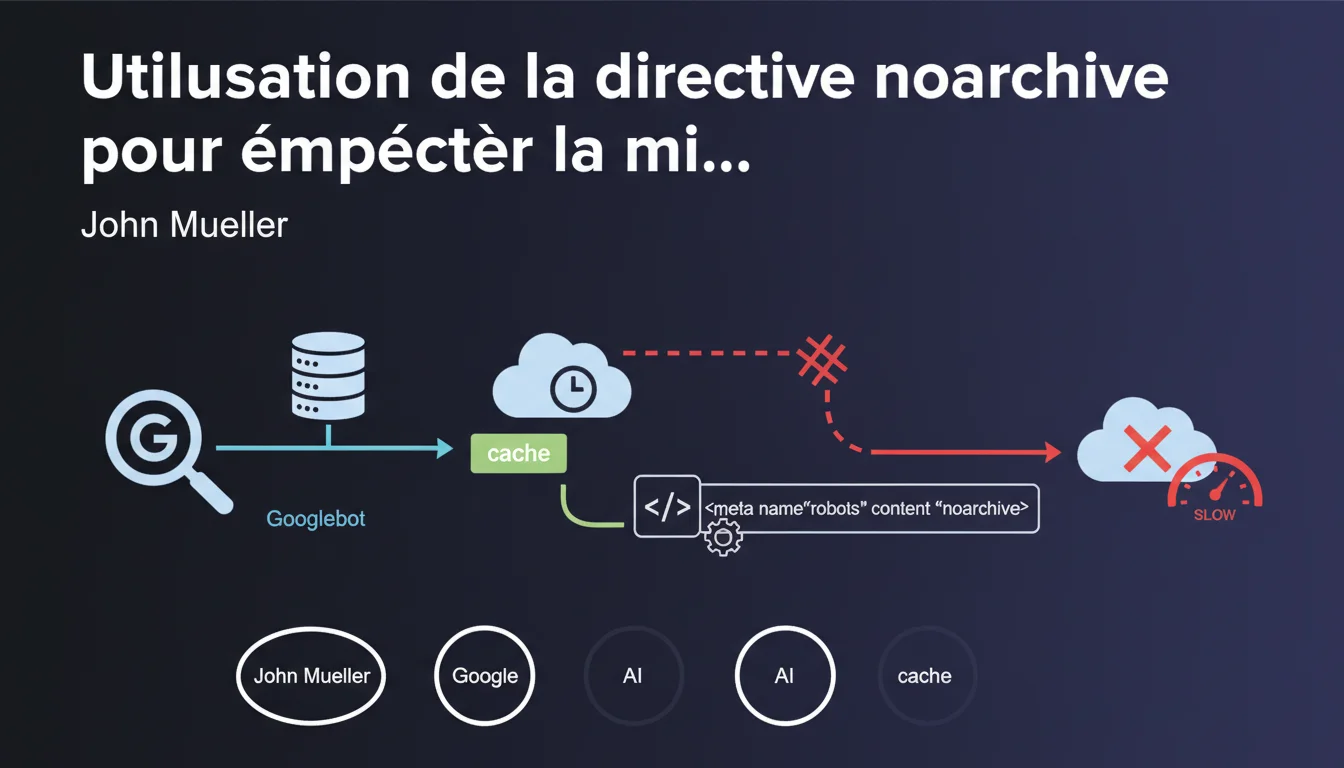
Google permet d'empêcher la mise en cache de vos pages via la directive robots 'noarchive'. Cette balise bloque l'affichage de la version archivée dans les résultats de recherche. À utiliser uniquement dans des cas précis où la confidentialité ou la fraîcheur du contenu l'exige.
Ce qu'il faut comprendre
Qu'est-ce que la directive noarchive et comment fonctionne-t-elle ?
La directive noarchive est une balise meta robots qui empêche Google de créer et d'afficher une version mise en cache de votre page. Concrètement, elle supprime le lien "En cache" qui apparaît normalement dans les résultats de recherche.
Cette directive s'intègre dans l'en-tête HTML de vos pages (<meta name="robots" content="noarchive">) ou via l'en-tête HTTP X-Robots-Tag. Elle n'empêche pas l'indexation — votre page reste présente dans les résultats — mais Google ne conserve plus de copie archivée accessible au public.
Pourquoi voudrait-on empêcher la mise en cache ?
Plusieurs scénarios justifient l'usage de cette directive. Les sites avec contenu sensible (données personnelles, prix fluctuants, informations confidentielles) peuvent vouloir éviter qu'une version obsolète circule. Les plateformes avec contenu payant ou derrière un paywall craignent que la version cache contourne leur modèle économique.
Les sites d'actualité ou de données en temps réel ont intérêt à ce que seule la version la plus récente soit consultée. Enfin, certaines entreprises préfèrent contrôler totalement ce qui est visible, sans version intermédiaire archivée par Google.
Cette directive a-t-elle un impact sur le référencement ?
Non, la directive noarchive n'affecte pas directement votre positionnement dans les résultats. Google continue d'indexer et de classer votre page normalement. L'impact est purement fonctionnel : les utilisateurs ne peuvent plus accéder à une version cache.
Cela dit, cette fonctionnalité peut indirectement jouer sur l'expérience utilisateur. Si votre site est lent ou temporairement indisponible, le cache Google permet parfois aux visiteurs d'accéder au contenu malgré tout. Bloquer cette option peut frustrer certains utilisateurs dans ces circonstances.
- La directive noarchive bloque uniquement l'affichage du cache, pas l'indexation
- Elle s'applique page par page via meta robots ou X-Robots-Tag
- Aucun impact direct sur le classement, mais supprime une option de secours pour les utilisateurs
- Utile pour contenu sensible, payant ou à forte volatilité
- Ne confondez pas avec noindex (qui supprime la page des résultats)
Avis d'un expert SEO
Cette directive est-elle vraiment nécessaire dans la majorité des cas ?
Soyons honnêtes : la plupart des sites n'ont aucune raison valable d'utiliser noarchive. Le cache Google est rarement consulté par les internautes lambda, et son existence n'a jamais posé de problème majeur pour l'immense majorité des éditeurs web.
Trop de webmasters appliquent cette directive par réflexe ou par méconnaissance, pensant "protéger" leur contenu. En réalité, ils suppriment une fonctionnalité qui peut s'avérer utile en cas de panne serveur ou de lenteur temporaire. Le cache devient alors un filet de sécurité pour l'accessibilité du contenu.
Dans quels cas concrets faut-il vraiment l'appliquer ?
Les sites e-commerce avec prix variables ont un argument recevable : une version cache affichant des tarifs obsolètes peut créer de la confusion. Les plateformes SaaS avec espaces clients personnalisés doivent impérativement bloquer le cache pour éviter toute fuite de données.
Les médias payants (presse en ligne, sites d'analyse financière) peuvent légitimement craindre que le cache contourne leur modèle d'abonnement — bien que cette crainte soit souvent exagérée, le cache Google n'étant pas une porte dérobée si efficace. Et c'est là que ça coince : beaucoup surestiment le risque réel.
Pour les sites d'actualité en temps réel (cours de bourse, résultats sportifs), l'argument tient la route. Mais pour un blog classique, un site vitrine ou même un e-commerce standard avec mise à jour quotidienne des stocks ? Franchement inutile.
Y a-t-il des effets de bord à surveiller ?
Un point rarement mentionné : le cache Google sert parfois d'outil de diagnostic pour les SEO. Quand une page ne s'affiche pas correctement ou qu'un contenu a disparu, la version cache permet de comprendre ce que Google a vu lors du dernier crawl. Bloquer systématiquement cette option complique ce travail d'investigation.
De plus, certains outils SEO tiers s'appuient sur le cache Google pour analyser l'évolution du contenu dans le temps. Moins critique, certes, mais c'est une considération pour les équipes qui audient régulièrement leurs sites. [A vérifier] : l'impact exact de noarchive sur les outils d'archive tiers (Wayback Machine, etc.) n'est pas toujours clair, mais ils fonctionnent généralement indépendamment du cache Google.
Impact pratique et recommandations
Comment mettre en place la directive noarchive correctement ?
Deux méthodes s'offrent à vous. La plus courante : ajouter <meta name="robots" content="noarchive"> dans la section <head> de vos pages HTML. Simple, direct, efficace pour des pages isolées.
Pour une gestion plus globale ou sur des contenus non-HTML, utilisez l'en-tête HTTP X-Robots-Tag : X-Robots-Tag: noarchive. Cette méthode est particulièrement pertinente pour les PDF, images ou autres ressources que vous souhaitez protéger du cache sans toucher au code HTML.
Si vous utilisez un CMS comme WordPress, des plugins SEO (Yoast, Rank Math) permettent d'activer noarchive page par page via une simple case à cocher. Pratique, mais vérifiez toujours le code source pour confirmer que la directive est bien présente.
Quelles erreurs éviter lors de l'implémentation ?
Erreur classique : appliquer noarchive en même temps que noindex. Si vous bloquez l'indexation, la directive noarchive devient inutile puisque la page n'apparaît de toute façon pas dans les résultats. C'est redondant et ça signale souvent une confusion sur les objectifs.
Autre piège : utiliser la directive de manière incohérente entre robots.txt, meta robots et X-Robots-Tag. Si vous bloquez le crawl dans robots.txt, Google ne verra jamais votre balise noarchive dans le HTML. La cohérence technique est cruciale.
Enfin, ne confondez pas noarchive avec unavailable_after, qui permet de supprimer une page des résultats après une date précise. Ce sont deux mécanismes différents pour deux besoins distincts. L'un concerne le cache, l'autre la présence même dans l'index.
- Identifiez les pages réellement sensibles nécessitant noarchive (contenu payant, données personnelles, prix volatils)
- Choisissez la méthode d'implémentation adaptée : meta robots pour HTML, X-Robots-Tag pour autres formats
- Vérifiez que la directive n'est pas appliquée par défaut à l'ensemble du site sans raison valable
- Testez l'implémentation en consultant le code source et en vérifiant l'absence du lien "En cache" dans les résultats
- Documentez les pages concernées pour faciliter les audits futurs et éviter les incohérences
- Ne combinez pas noarchive avec noindex — c'est redondant et source de confusion
La directive noarchive est un outil de contrôle précis, pas une mesure de sécurité générale. Son usage doit être ciblé et justifié : sites e-commerce à forte volatilité tarifaire, contenus sensibles, plateformes payantes. Pour tout autre cas, vous supprimez une fonctionnalité utile sans bénéfice réel.
La mise en œuvre technique est simple, mais la stratégie d'application demande discernement. Une mauvaise configuration peut compliquer vos diagnostics SEO et frustrer les utilisateurs sans apporter de protection tangible. Si la gestion de ces directives robots devient complexe à l'échelle de votre site, ou si vous hésitez sur les pages à traiter, un accompagnement par une agence SEO spécialisée peut vous éviter des erreurs coûteuses et vous aider à définir une stratégie cohérente avec vos objectifs métier.
❓ Questions frequentes
La directive noarchive empêche-t-elle Google d'indexer ma page ?
Puis-je appliquer noarchive uniquement à certaines sections d'une page ?
Est-ce que noarchive affecte mon positionnement dans Google ?
Combien de temps faut-il pour que la suppression du cache prenne effet ?
La directive noarchive bloque-t-elle aussi les archives tiers comme Wayback Machine ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 20/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.