Declaration officielle
Ce qu'il faut comprendre
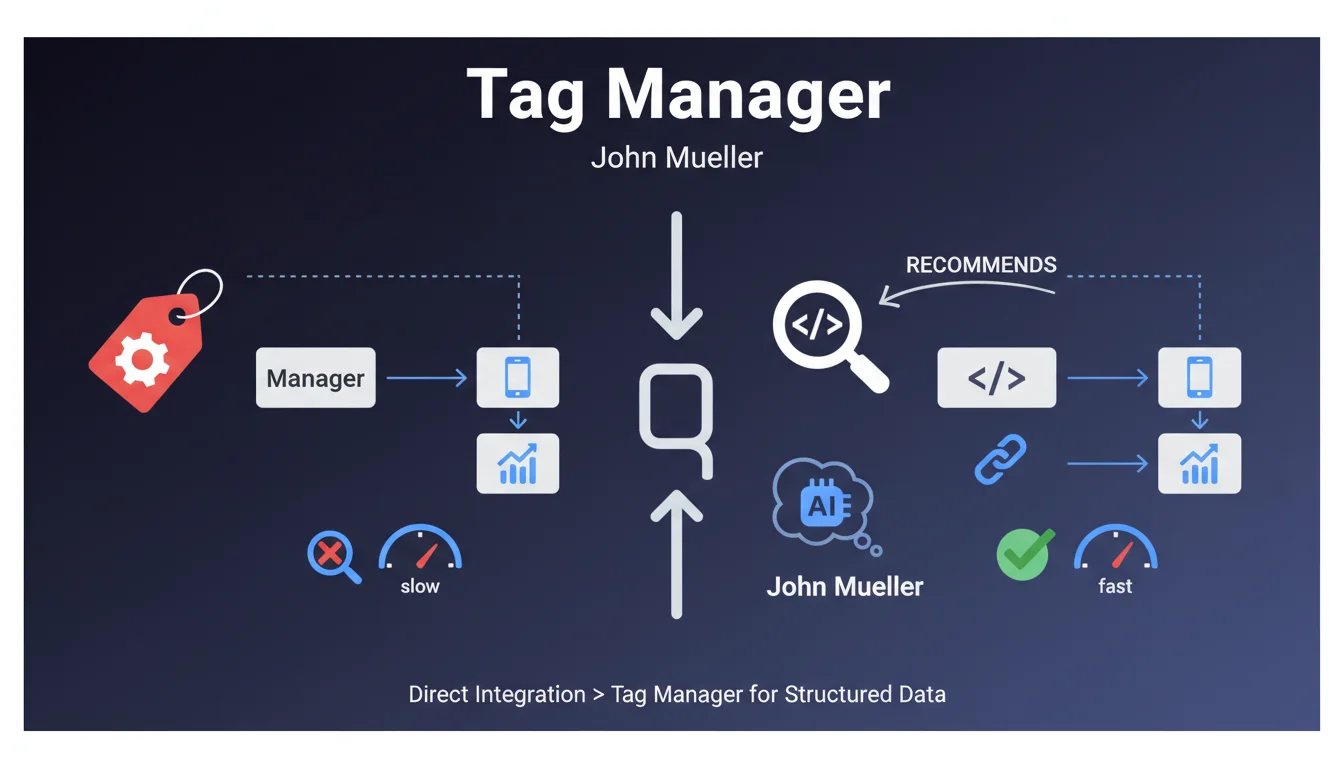
Pourquoi Google déconseille-t-il Tag Manager pour les données structurées ?
John Mueller de Google a exprimé une préférence claire pour l'intégration directe des balises de données structurées dans le code HTML des pages. Sa justification repose sur des arguments de maintenabilité et de surveillance du code.
L'approche via Tag Manager ajoute une couche d'abstraction supplémentaire. Cela complexifie le débogage et rend plus difficile l'audit des modifications apportées aux balises Schema.org au fil du temps.
- L'intégration directe facilite le versioning et le suivi des modifications dans le code source
- Les données structurées natives sont plus prévisibles et stables dans le temps
- La maintenance est simplifiée pour les équipes techniques qui gèrent le site
- Google peut crawler et indexer ces balises de manière plus fiable
Est-ce que Tag Manager empêche l'indexation des données structurées ?
Non, c'est un point crucial à comprendre. Google est capable de lire et interpréter les données structurées injectées via Google Tag Manager. Le JavaScript est exécuté et les balises sont bien prises en compte par Googlebot.
La recommandation de Mueller n'est donc pas liée à un problème technique d'indexation. Il s'agit plutôt d'une meilleure pratique organisationnelle visant à optimiser la gestion long terme du code.
Dans quel contexte Tag Manager reste-t-il acceptable ?
Google reconnait une utilisation légitime de GTM pour les phases de test et d'expérimentation. Cette approche permet de valider rapidement l'impact des données structurées sans déploiement technique lourd.
Une fois les tests concluants, la bonne pratique consiste à migrer ces balises directement dans le code de la page. Cette stratégie hybride combine agilité et pérennité.
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les pratiques observées sur le terrain ?
Absolument. Dans ma pratique d'expert SEO depuis 15 ans, j'observe que les sites avec des données structurées natives présentent moins de problèmes de maintenance. Les équipes techniques apprécient la clarté d'avoir tout le code au même endroit.
Cependant, la réalité des organisations est nuancée. Certaines entreprises n'ont pas la vélocité de développement nécessaire pour intégrer rapidement des modifications dans leur code source. GTM devient alors un mal nécessaire pour rester agile.
- Les grandes entreprises avec des cycles de release longs utilisent souvent GTM par nécessité
- Les sites e-commerce dynamiques bénéficient de l'intégration native pour les fiches produits
- Les tests A/B sur les données structurées se font logiquement via GTM
Quelles nuances faut-il apporter à cette directive ?
La position de Mueller est pragmatique mais ne constitue pas une règle absolue. Il existe des cas où GTM reste la meilleure solution, notamment pour les organisations décentralisées où les équipes marketing n'ont pas accès direct au code.
Un autre aspect souvent négligé concerne la performance de rendu. Les données structurées injectées en JavaScript peuvent subir un léger délai avant d'être disponibles pour le crawler, bien que Google gère désormais très bien le JS.
Quel est le véritable enjeu derrière cette recommandation ?
Au-delà de l'aspect technique, Mueller soulève une question de gouvernance du code SEO. Les données structurées font partie intégrante du contenu sémantique d'une page, pas d'une couche de tracking.
Philosophiquement, il est plus cohérent de traiter les balises Schema.org comme du contenu structuré permanent plutôt que comme des tags marketing temporaires. Cette vision influence positivement la qualité globale de l'implémentation.
Impact pratique et recommandations
Que faut-il faire concrètement sur votre site ?
Si vous utilisez actuellement GTM pour vos données structurées, pas de panique immédiate. Commencez par auditer vos implémentations existantes et établissez un plan de migration progressif.
Priorisez les balises les plus importantes : Organization, Product, Article, Breadcrumb devraient être migrées en priorité dans le code natif. Les éléments moins critiques peuvent attendre une version ultérieure.
- Identifiez toutes les données structurées actuellement gérées via GTM
- Validez leur bon fonctionnement avec le Rich Results Test de Google
- Créez un planning de migration par ordre de priorité SEO
- Testez chaque implémentation native sur un environnement de staging
- Documentez les modifications pour faciliter la maintenance future
- Gardez GTM uniquement pour les tests et expérimentations temporaires
Quelles erreurs éviter lors de la migration ?
L'erreur classique consiste à désactiver GTM avant que le code natif soit déployé et validé. Vous risquez une perte temporaire de vos rich snippets dans les résultats de recherche.
Autre piège fréquent : dupliquer les balises en ayant à la fois la version GTM et la version native active simultanément. Google pourrait alors recevoir des données contradictoires sur une même page.
Comment garantir une implémentation pérenne et performante ?
Intégrez les données structurées dans votre workflow de développement standard. Elles doivent être considérées comme du code de production, avec versioning Git, revue de code et tests automatisés.
Pour les sites complexes avec des catalogues produits importants, envisagez une génération dynamique côté serveur des balises Schema.org. Cette approche garantit cohérence et scalabilité.
- Créez des templates réutilisables pour chaque type de données structurées
- Mettez en place une surveillance automatique avec Search Console
- Formez vos équipes techniques aux bonnes pratiques Schema.org
- Documentez vos standards d'implémentation dans un guide interne
💬 Commentaires (0)
Soyez le premier à commenter.