Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- □ Pourquoi votre site n'apparaît-il pas dans Google : indexation ou ranking ?
- □ Pourquoi Google pousse-t-il Search Console pour diagnostiquer l'indexation ?
- □ L'URL Inspection Tool de Search Console remplace-t-il vraiment le test d'indexation manuel ?
- □ Le rapport d'indexation de la Search Console suffit-il vraiment à diagnostiquer vos problèmes d'indexation ?
- □ Faut-il vraiment chercher à indexer 100% de ses pages ?
- □ Pourquoi Google indexe-t-il toujours la page d'accueil en premier sur un nouveau site ?
- □ Pourquoi la page d'accueil de votre nouveau site ne s'indexe-t-elle pas ?
- □ Pourquoi votre homepage n'apparaît-elle toujours pas dans l'index Google ?
- □ Votre site est-il vraiment absent de l'index Google ou juste victime de la canonicalisation ?
- □ Hreflang fausse-t-il vos rapports d'indexation dans Search Console ?
- □ Pourquoi vos pages 'site en construction' ne seront jamais indexées par Google ?
- □ Pourquoi certaines pages s'indexent en quelques secondes et d'autres jamais ?
- □ Google peut-il encore indexer l'intégralité du web ?
- □ Google applique-t-il vraiment un quota d'indexation par site ?
- □ Faut-il vraiment utiliser la fonction 'Demander une indexation' de la Search Console ?
- □ L'opérateur site: est-il vraiment fiable pour mesurer l'indexation de votre site ?
- □ Comment exploiter vraiment l'opérateur site: au-delà de la simple vérification d'indexation ?
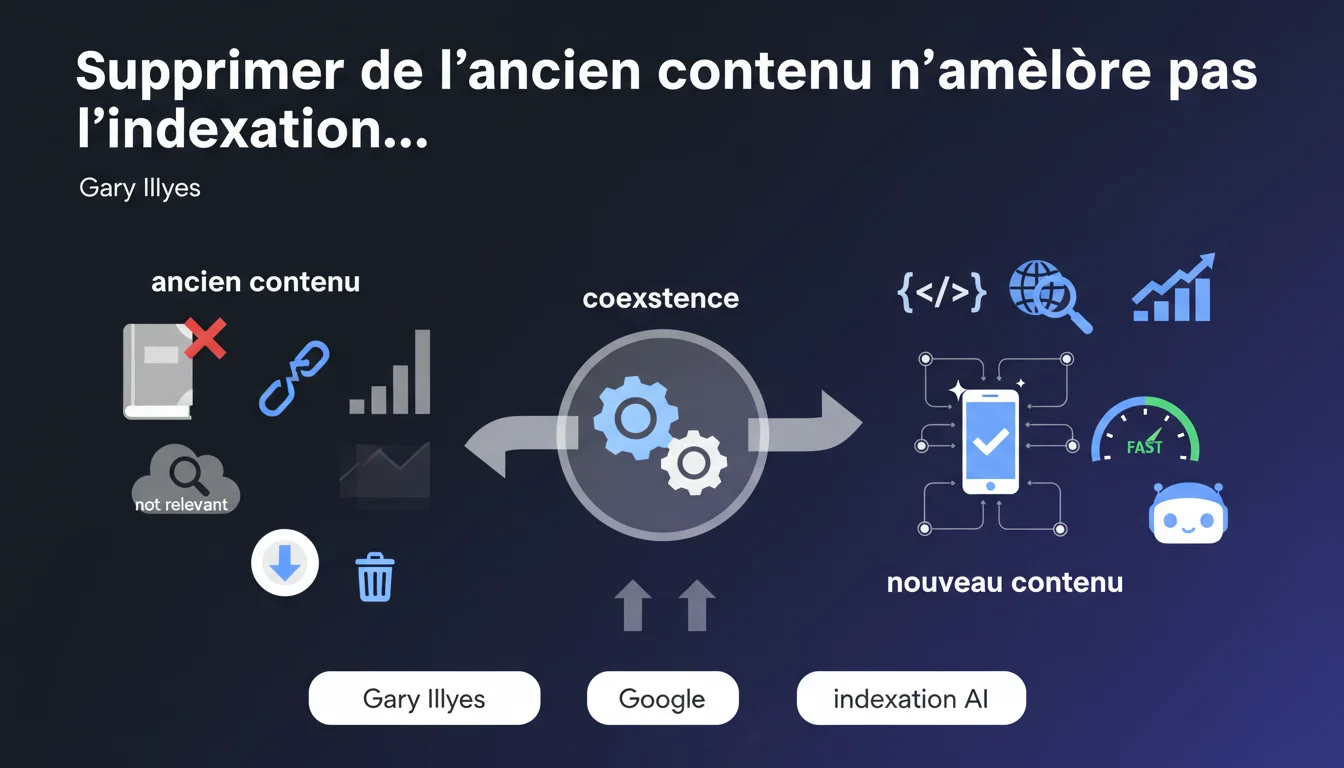
Google affirme qu'il n'existe aucun quota d'indexation par site et que supprimer de l'ancien contenu n'améliore pas l'indexation de nouvelles pages. Ancien et nouveau contenu peuvent coexister sans interférence mutuelle selon la firme de Mountain View.
Ce qu'il faut comprendre
Pourquoi cette déclaration remet-elle en question une pratique courante ?
De nombreux SEO pensent encore qu'un site avec trop de pages anciennes ou non pertinentes dilue son « capital crawl » et pénalise l'indexation des nouvelles URLs. Cette croyance repose sur l'idée qu'un quota d'indexation existe par domaine.
Gary Illyes démonte frontalement cette hypothèse. Selon lui, Google n'impose aucune limite d'indexation par site. Un domaine peut héberger 100 pages comme 100 000 sans que cela impacte négativement la capacité du moteur à indexer de nouvelles ressources.
Quelle est la différence entre crawl budget et quota d'indexation ?
Le crawl budget correspond au nombre de pages que Googlebot va parcourir sur un site dans une période donnée. C'est une limite de ressources allouées au crawl, pas à l'indexation.
Le quota d'indexation — que Google nie ici formellement — serait une limite théorique du nombre de pages qu'un domaine peut faire indexer. Ces deux concepts sont distincts mais souvent confondus dans les discussions SEO.
Qu'implique cette déclaration pour la gestion de contenu ancien ?
Concrètement, conserver des archives, des pages produits obsolètes ou du contenu historique ne nuirait pas à l'indexation de nouveaux articles ou fiches. Google serait capable de gérer cette coexistence sans friction.
Cela ne signifie pas pour autant que tout contenu mérite d'être conservé — la question se pose plutôt en termes d'expérience utilisateur, de pertinence métier et de stratégie éditoriale, pas d'indexation pure.
- Aucun quota d'indexation par domaine selon Google
- Le crawl budget et l'indexation sont deux mécanismes distincts
- Supprimer de l'ancien contenu n'accélère pas l'indexation du nouveau
- La décision de conserver ou non du contenu ancien relève de critères business et UX, pas d'indexation technique
Avis d'un expert SEO
Cette affirmation est-elle cohérente avec les observations terrain ?
Dans la pratique, certains audits montrent qu'un grand volume de pages de faible qualité peut effectivement ralentir le crawl et, indirectement, l'indexation. [À vérifier] — Google parle ici d'indexation stricto sensu, pas de priorisation du crawl ni de qualité perçue du site.
La nuance est cruciale : si Googlebot alloue son temps à crawler des milliers de pages zombies, il en reste mécaniquement moins pour découvrir et indexer rapidement du contenu frais. Le quota d'indexation n'existe peut-être pas, mais le temps de crawl, lui, est fini.
Dans quels cas la suppression de contenu ancien reste-t-elle pertinente ?
Supprimer ou consolider du contenu ancien reste justifié pour plusieurs raisons — mais pas celle invoquée par Google. Pages dupliquées, thin content, cannibalisation interne : autant de situations où un nettoyage améliore la cohérence sémantique du site.
L'effet positif observé après un élagage massif ne vient probablement pas d'un « quota libéré », mais d'une meilleure concentration du link juice interne, d'une réduction du bruit sémantique et d'une amélioration de la qualité moyenne perçue par l'algorithme.
Quelle stratégie adopter face à cette déclaration ?
Soyons honnêtes : Google a intérêt à ce que les éditeurs conservent un maximum de contenu indexable — plus de pages, c'est plus de surface publicitaire potentielle. Cette déclaration pourrait viser à décourager les stratégies agressives de pruning.
La vraie question n'est pas « est-ce que je peux tout garder ? » mais « est-ce que ce contenu apporte de la valeur à mes utilisateurs et à ma stratégie SEO globale ? ». Si la réponse est non, supprimez — pas pour un hypothétique quota, mais pour la cohérence éditoriale.
Impact pratique et recommandations
Que faire concrètement avec l'ancien contenu de mon site ?
Ne supprimez pas aveuglément des pages anciennes sous prétexte de « libérer de l'indexation ». Évaluez chaque contenu selon des critères business : génère-t-il du trafic organique ? Sert-il un objectif de conversion ou d'information ? Participe-t-il au maillage interne stratégique ?
Si une page ancienne performe encore, conservez-la. Si elle est obsolète mais historiquement importante, envisagez une refonte ou une mise à jour plutôt qu'une suppression brutale. La stratégie de contenu prime sur la technique pure.
Quelles erreurs éviter après cette déclaration ?
L'erreur serait d'interpréter cette déclaration comme une autorisation à laisser filer la qualité éditoriale. Un site bourré de pages faibles n'aura pas de problème d'indexation selon Google, mais il aura probablement un problème de ranking et d'expérience utilisateur.
Autre piège : confondre crawl budget et indexation. Si votre site souffre de lenteur de crawl sur les nouvelles URLs, le problème vient peut-être d'une architecture défaillante, de redirections en chaîne ou d'un excès de paramètres URL — pas d'un quota d'indexation fantasmé.
Comment vérifier que mon site gère correctement ancien et nouveau contenu ?
- Analysez dans la Search Console le taux d'indexation des nouvelles pages vs pages anciennes
- Vérifiez via les logs serveur que Googlebot crawle bien vos nouveaux contenus dans un délai acceptable
- Auditez la qualité moyenne de votre index : ratio pages actives / pages zombies (zéro trafic sur 12 mois)
- Identifiez les pages anciennes qui cannibalisent du trafic sur des requêtes où vous avez publié du contenu plus récent et plus pertinent
- Mettez en place un processus de mise à jour régulière des contenus evergreen plutôt qu'une logique de suppression systématique
❓ Questions frequentes
Supprimer de vieilles pages améliore-t-il vraiment le SEO ?
Existe-t-il une limite au nombre de pages qu'un site peut faire indexer ?
Crawl budget et quota d'indexation, c'est la même chose ?
Dois-je garder toutes mes pages anciennes en ligne ?
Comment savoir si mes nouvelles pages sont bien indexées ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.